数据可视化:看中国经济发展
Posted 韩锋频道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化:看中国经济发展相关的知识,希望对你有一定的参考价值。
近期因工作需要,尝试使用一些数据可视化手段做产品运营分析。自己之前对可视化的理解仅仅限于excel做做图表,但深入下去发现数据可视化远不限于此,可以说很多的工作的基本功。掌握必要的数据可视化手段,可以大大提升你的工作效率。下面将通过示例,尝试使用数据可视化手段分析国家、地域经济发展状态。数据来自于国家统计局(http://data.stats.gov.cn)公开披露数据(少部分2019年数据来自于互联网)。
数据可视化
数据可视化,是指数据用各种图像处理技术,将数据转化为各种图表的方法和手段。其目的是为了观察和跟踪各种数据,生成实时的、可读性强的图表;分析数据、生成交互式的图表;发现数据间潜在关系,生成多维图表,以及多角度的分析数据,帮助用户深刻地连接数据含义和变化,进而做出及时和准确的决策。
1. 可视化准备工作
1). 数据建模
在我们开始数据可视化之旅之前,需要做些前期的准备工作。在传统的数据分析来说,是要有个数据建模过程。即通过对业务需求的分析,建立对现实世界的抽象(建模)过程。这个不是本篇重点,简略带过。
2).数据准备
在分析之前,是需要有个数据准备过程。一般是将数据从内部系统、外部数据源等抽取出来。抽取的数据需要进一步检查质量,是否达到数据分析标准。如果有问题是需要做必要的清洗。此外,如果各数据的口径、度量不同,也需要在此做必要的处理。后续根据需要还需对数据进行必要的聚合以及各种计算需求。最后将结果加载在目标表中,供后续分析使用。整个这个过程就是常说的ETL过程。
“ETL”,即数据抽取(Extract)、转换(Transform)、装载(Load)的过程。它是构建数据仓库系统的关键环节。因为数据仓库主要是面向主题的、集成的、稳定的并且随着时间不断变化的数据集合,所以数据在进入到仓库之前,需要经过清洗、转化的过程,保证数据仓库的数据是准确的。ETL的作用就是解决数据集成化的问题。ETL过程中包括一些灵活的计算、汇总、字段拆分、字段合并、数据比较、过滤、混合运算等内容,还包括对自定义函数的支持、复杂条件的过滤、数据的批量加载、时间类型的转换、多种数据类型支持、去重复记录等功能。
2).数据分层
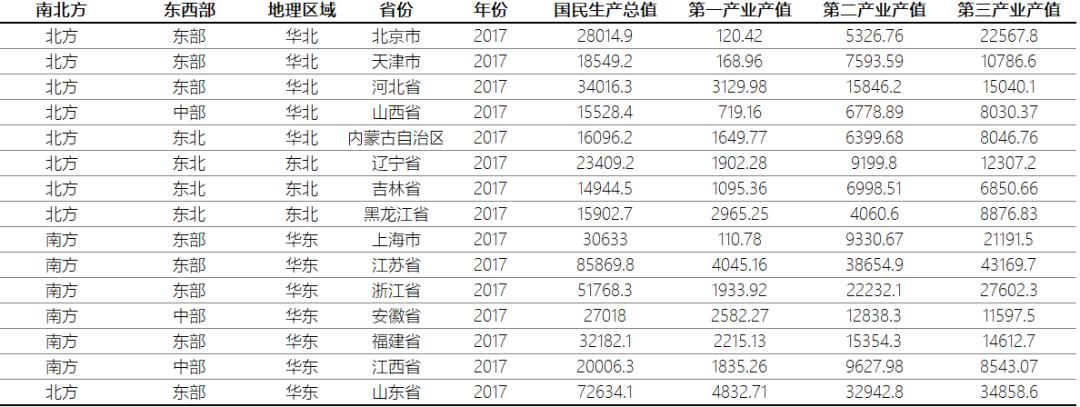
进入系统中的数据,根据使用特点,一般可细分为SOURCE、STAGE、DW、DM、APP层等。这里涉及到不同的建模方式,内容较多不展开了。大家可简单理解为,数据经过各层加工,最终形成一张“大宽表”,里面涵盖了我们需要分析的所有数据即可。例如针对后面的示例,整理出下面一张表。
2. 可视化几个概念
在我们开始数据可视化之前,还需要明确几个概念。
维度
是指人们观察事物的角度,如地理维度、时间维度、产品维度等。我们可理解为对数据的属性、标签等。有的时候维度和后面谈到的度量不太容易区分。维度,是有某些特点,例如它们一般是离散的,不能直接比较、运算的等。但这也并非一定之规,有些情况下维度和度量是可以转换的。在上面的示例中,维度就包括了地理分区(南北方、东西部、地理区域等)、省份、年份维度。顺便提下,原始数据中只有省份、年份,其余维度是通过数据加工得到的,也称为派生维度。
层次
根据描述维度的不同,划分数据在逻辑上的等级关系,用来描述维度的各个方面。例如,时间维度包括年、月、日等层次;地理维度包括国家、省、市、区(县)等层次。像时间、地理维度是天生具备层次性的,有些维度是需要人工加工得到。维度的层次划分,可为后续我们做数据钻取提供依据。
维度成员
维度的取值,即维度中的各个数据元素的取值。例如,地区维度里具体成员有北京市、天津市等。
钻取
通过变换维度的层次,改变粒度的大小。它包括向上钻取(Drill Up)和向下钻取(Drill Down)。向上钻取是将细节数据向上追溯到最高层次的汇总数据。向下钻取是将最高层次的汇总数据深入到最低层次的细节数据中。例如,我们可以看全国的GDP总量,也可以向下钻取到省、市一级。
旋转
通过变换维度的方向,重新安排维的位置,如行列互换。
切片
在一个或多个维度上选取固定的值,分析其他维度上的度量数据。如其他维度剩余两个,则是切片;如果是三个,则是切块。例如,后面尝试对直辖市做的分析,就是一种数据切片。
度量
多维数据的取值,例如图表中的国民生产总值(GDP)、第一产业产值等。一般度量是可以计算、比较的。
3. 中国经济发展分析
1). 整体现状
下图为《2019年度,中国省、自治区GDP总览图》
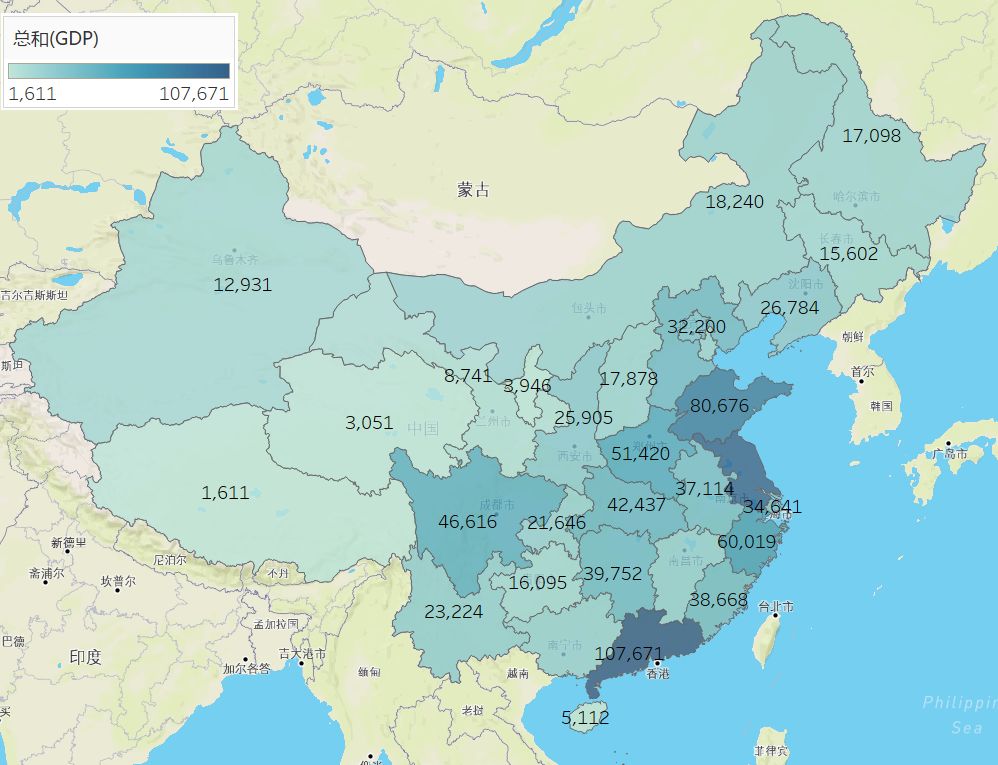
从上图可看出,全国各省的发展差异。从最高的广东10万多亿,到最低的西藏1600多亿,差距非常之大。图中通过色块颜色差异,很明显地标识出地区间差异。主要经济发达地区,集中在沿海一带(广东、江苏、浙江、山东)和部分内陆省份(河南、四川、湖北等)。其余中西区及东北地区,还有很大发展潜力。
地图
与地理位置密切相关,希望知道各区域的分布状况可以选用数据地图。这是最贴合实际,生动形象的一张图,自带基本维度——地理维度。通过区域块颜色深浅反映程度/分类。
2). 历年发展情况
下图为《1999~2019年,全国GDP增长图》
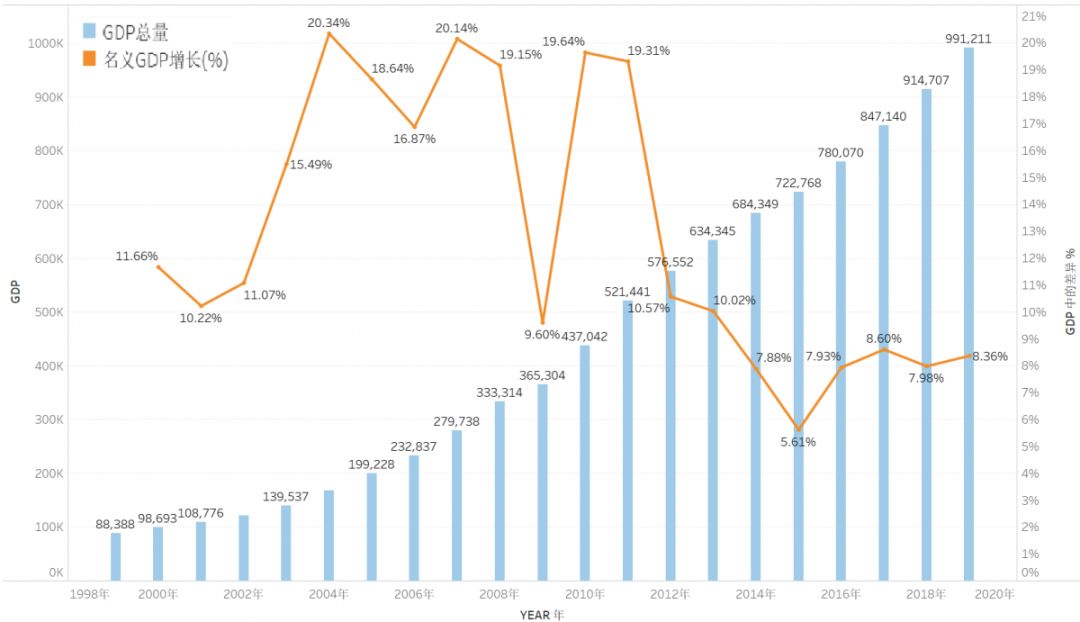
上图中,柱状图显示各年份的经济总量;折线图部分显示名义经济增长率%的变化趋势。从上图可见,在02~12的十年间,中国GDP的发展经历了黄金十年。近几年的发展逐步减缓,并稳定在6%~9%之间。
条形图 & 柱状图
适用于二维数据集,用来显示一段时期内数据的变化或者描述各项之间的比较。分类项水平组织,数值垂直组织,用来强调数据随时间或者其他条件的变化,适用中小规模的数据集。纵向的(如上图)成为柱状图,横向的成为条状图。
折线图
折线图适合二维的大数据集,尤其是那些趋势比单个数据点更重要的场合。假设需要查看各个年份的GDP增长率的走势,此时选择折线图组件来提供数据分析是比较合适的。
3). 区域分析
我国地域辽阔,各地域间经济发展差距显著。一般在数据分析上,经常使用几类划分进行分析。
★ 南-北划分
在地理上,人们经常把“秦岭-淮河”作为南北分界线,北方地区包括黑龙江、吉林、辽宁、河北、北京、天津、内蒙、新疆、甘肃、宁夏、山西、陕西、青海、山东、河南等 15 个省份,总面积 580万平方公里,人口约5.9亿。南方地区包括江苏、浙江、上海、安徽、湖北、湖南、江西、四川、重庆、贵州、云南、广西、福建、广东、海南、西藏等 16 个省份,总面积 384 万平方公里,常住人口 8.1 亿人。
下图为《1999~2019,南北方经济总量发展对比》
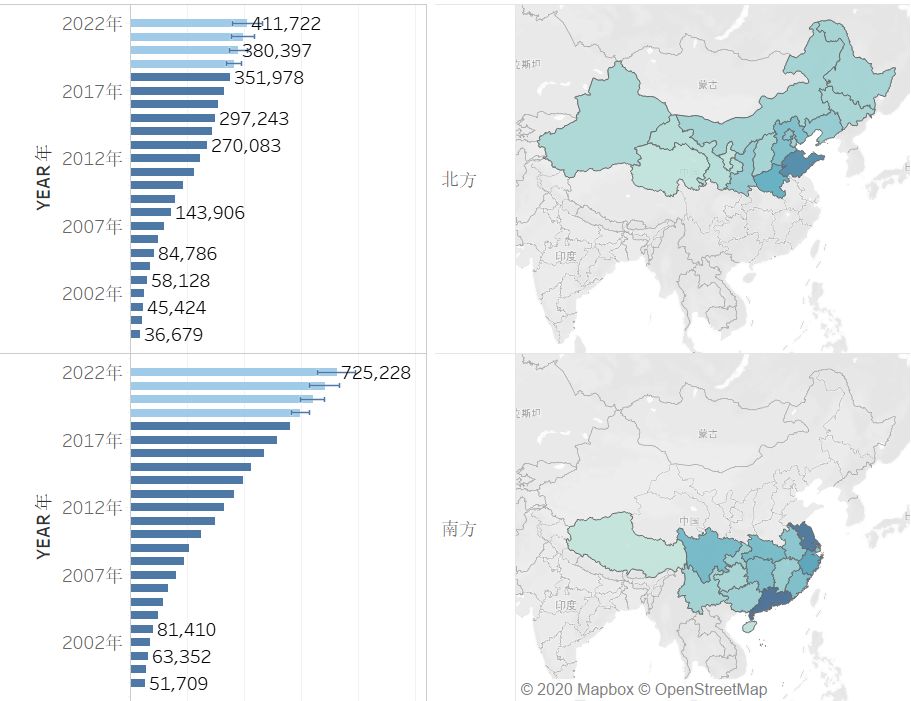
从上图可见,南北方差异较大,且整体发展趋势仍呈扩大趋势。
维度分层
上图中使用了维度分层的概念,将省份划分为南北方,并基于单一维度在多维度值下呈现变化趋势。
趋势分析
上图中还使用了指数趋势分析,在分析连续几年的数据时,以其中一年的数据为基期数据(通常是以最早的年份为基期),将基期的数据值定为100,其他各年的数据转换为基期数据的百分数,然后比较分析相对数的大小,得出有关数据的趋势。
★ 东-西划分
这里要介绍下胡焕庸线,即中国地理学家胡焕庸(1901-1998)在1935年提出的划分我国人口密度的对比线,也称为“爱辉—腾冲一线”或“黑河—腾冲线”。其经过黑龙江、内蒙古、山西、陕西、甘肃、四川、云南多省。在经济学统计上,参照此类划分将地域分为东-中-西-东北部。
下图为《2019年,东西部区域各省、自治区经济总量图》
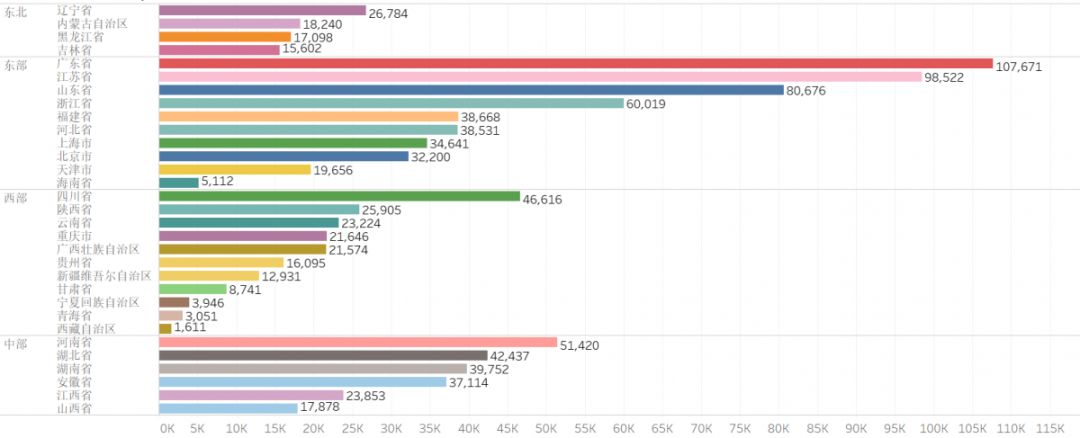
上图数据可见,各区域发展特点不同。东北地区,整体疲软,各地区间差异不大。东部地区表现突出,经济重点省份集中于此。西部地区,差异较大,发展不同。中部地区,整体平均,后劲十足。
多维度坐标轴 + 条状图
多维度坐标轴的使用,很方便对比维度间差异和二级维度内的不同。一般常见的是层次维度或枚举个别维度值的对比。而条状图,较柱状图而言,更适合表现元素较多、差异巨大的数据。
★ 行政划分
除了上述划分为,更为常见的方式是按行政区划的划分。
下图为《2019年,行政区域GDP总量对比》
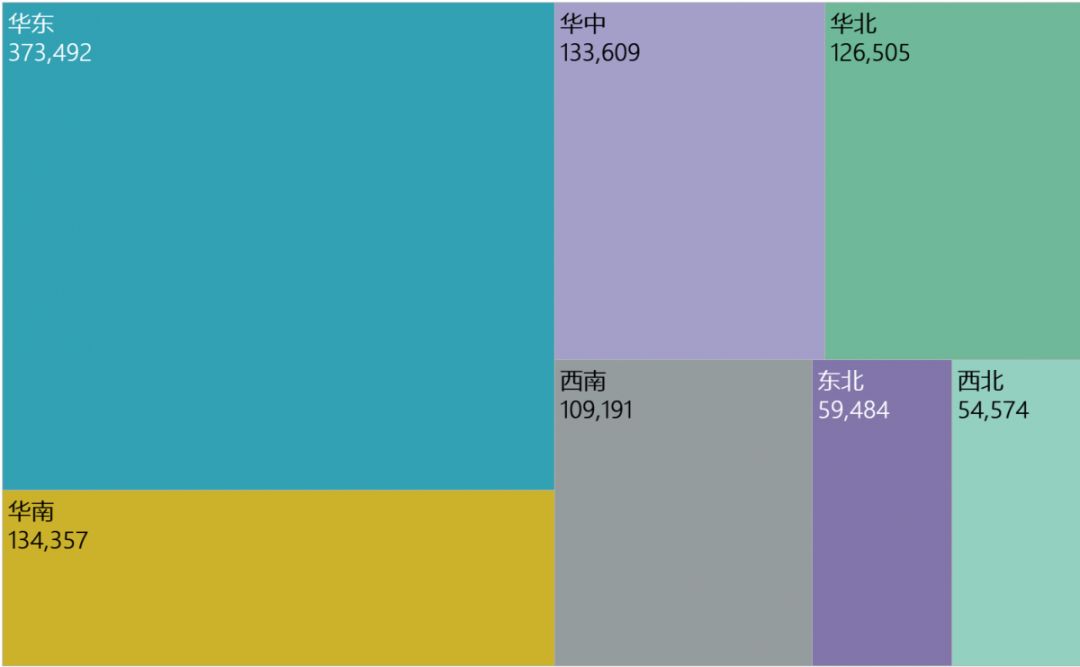
树状图,比较适合呈现大块数据的对比。其总量是100%,各其余占比可通过色块直观体现。
4). 产业分析
三大产业是联合国使用的分类方法:第一产业包括农业、林业、牧业和渔业;第二产业包括制造业、采掘业、建筑业和公共工程、水电油气、医药制造;第三产业包括商业、金融、交通运输、通讯、教育、服务业及其他非物质生产部门。随着社会经济和科学进步,其变化趋势是:起初是第一产业的比重不断下降,第二产业的比重不断上升,第三产业的比重也不断上升;随后包括第一、第二产业的物质生产部门的比重都不同程度下降,第三产业的比重持续上升。这种变化趋势在发达国家比较突出。发达国家第三产业的产值和就业人口的比重一般都在50%以上,成为规模最大、增长最快的产业。下面看看我国的情况。
下图为《2018年度,国内各省、自治区GDP及第三产业占比》
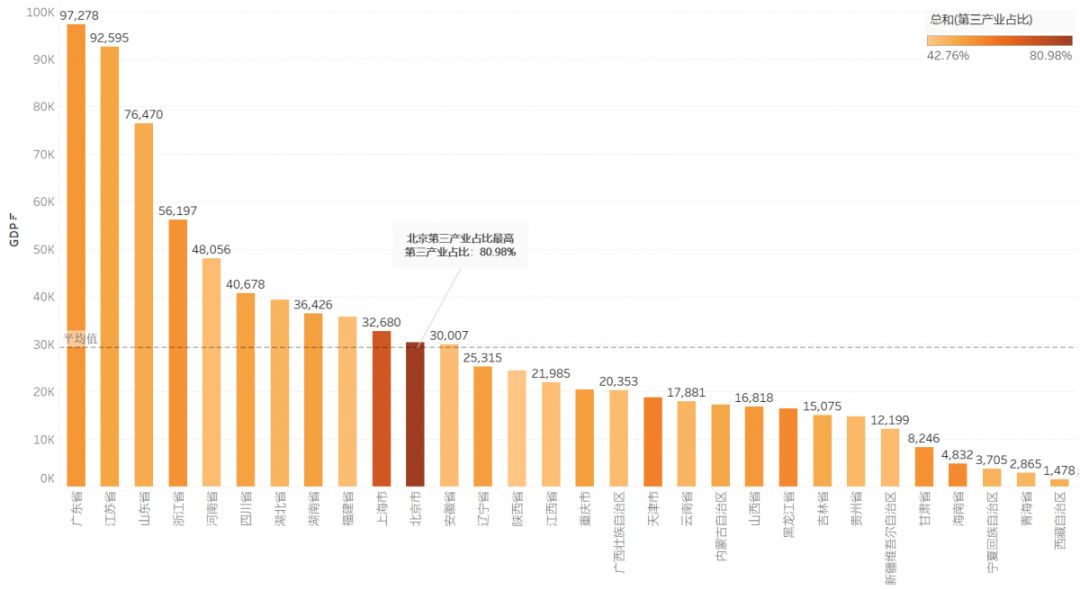
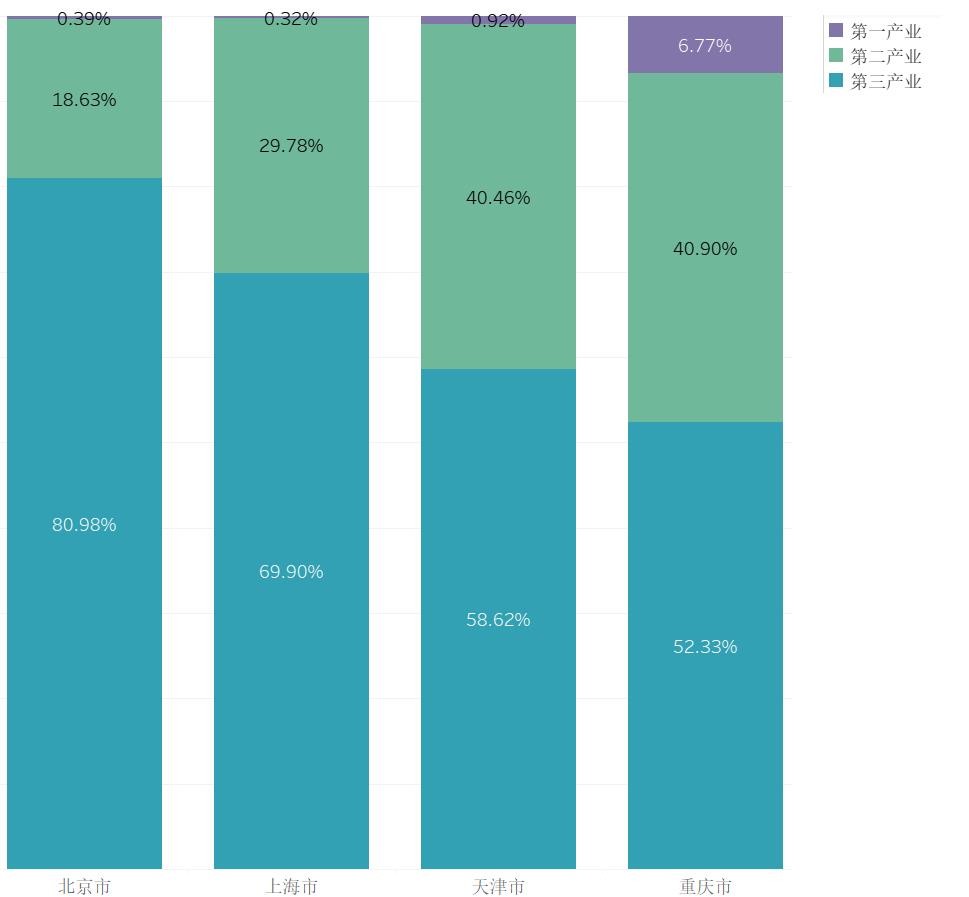
从各省来看,差距非常明显(颜色深浅),北京的第三产业比重最高,超过了80%。较发达地区的第三产业比重普遍较高。再从直辖市角度分析可见,各直辖市各产业占比情况。重庆市与天津市,仍处于早期阶段。
堆积图 & 百分比堆积图
堆积柱形图是在每个分类下将每个系列的值堆积起来显示,不仅可以直观的看出每个系列的值,还能够反映出系列的总和;而百分比堆积柱形图是每个分类下系列的总和为100%,每个系列按照所占的百分比进行堆积,这样就能直观的看出每个系列所占的比重。
5). 典型地区对比
下面以我熟悉的两个地方,黑龙江和北京,对比下地方的发展差异。
下图为《1999~2019年,北京与黑龙江GDP发展及增量差异》
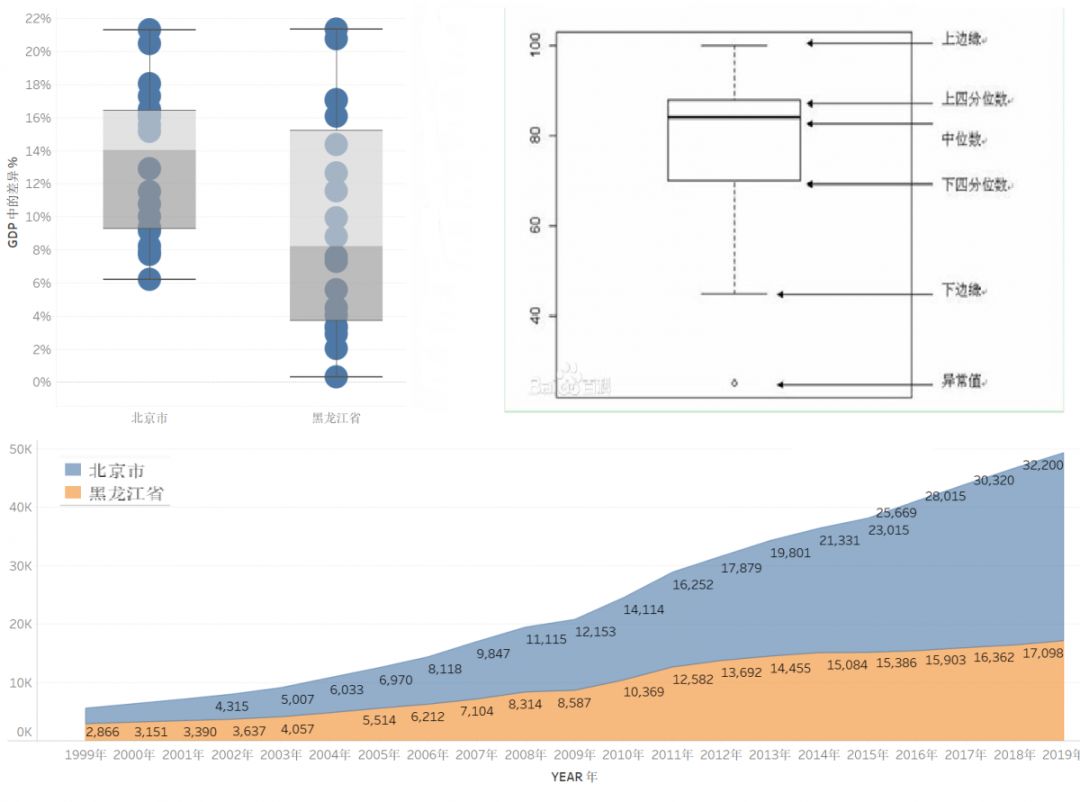
上图显示的两个地区,在过去20年的的GDP变化。从面积图中可见,两者从最开始1999年的同等起跑线,到2019年差距接近一倍。这也是近些年来,对东北经济发展滞后的一个写照。针对每年的发展率,我们可从左上的箱式图,从中可发现其发展率的空间分布。北京整体较高,且发展变化比较均匀,而黑龙江则变动较大。右上则是对箱式图中各指标的说明。
面积图
面积图能够表示数据的时间序列关系,和折线图不同的是,面积图能够清晰表示出量。
箱式图
箱式图,又称为盒须图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域也经常被使用,常见于品质管理。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。
6). 其他角度分析
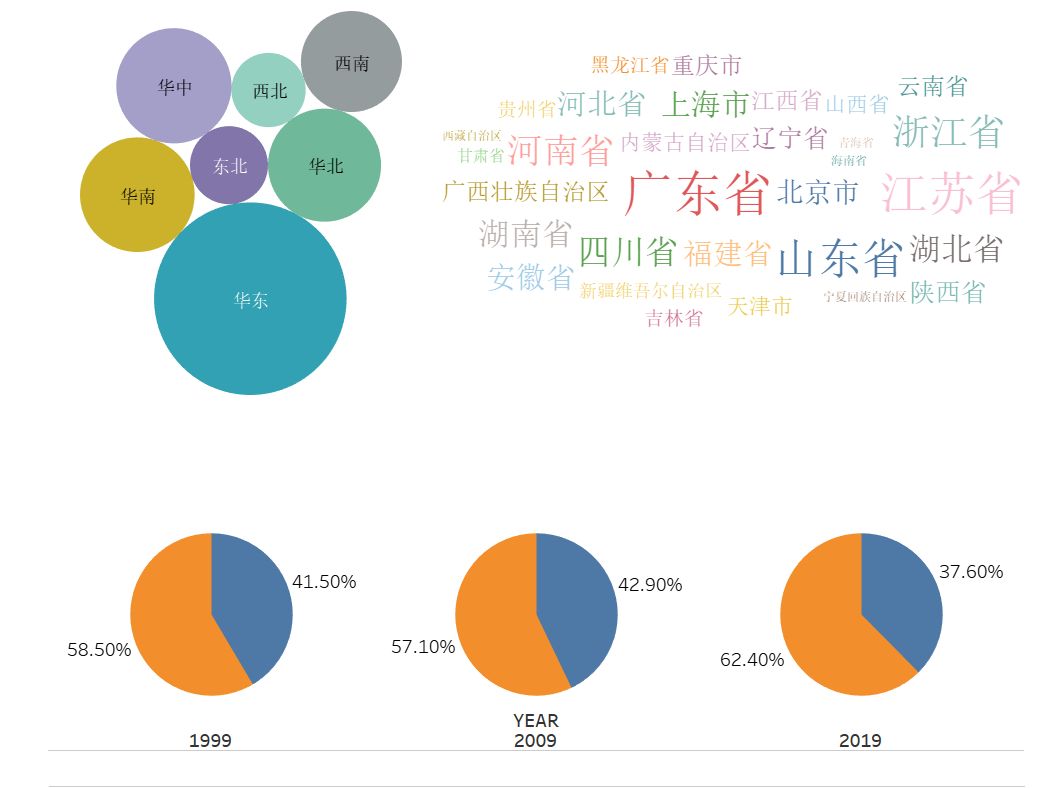
左上是气泡图,反映了各行政区域2018年GDP对比。右上为词云,显示类似的指标。下方为十年阶段下,南北方GDP在全国中的占比。
饼图
普通的饼图表现并不是很直观,因为肉眼对面积大小不敏感。所以,在具体反映某个比重的时候,配上具体数值,会有较好的效果。此外,也可以使用等弧度玫瑰图,以面积的大小放大各比重的排列,比较赏心悦目。
散点图 & 气泡图
散点图适用于三维的数据集,但一般只有两维需要比较,主要看分布,有些会设置四象限。气泡图是散点图的一种衍生。不同于散点图,通过每个点的面积大小,都反映了第三维,比如十字象限气泡图。
词云
类似于气泡图,仿照搜索的关键字的方式呈现。其通过颜色、文字大小比例等,反映度量的大小比例。
韩锋频道:
关注技术、管理、随想。
长按扫码可关注
以上是关于数据可视化:看中国经济发展的主要内容,如果未能解决你的问题,请参考以下文章
仪表板展示 | DataEase看中国:数据呈现中国能源发展情况