Swift 性能相关
Posted 全栈取经之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Swift 性能相关相关的知识,希望对你有一定的参考价值。
为什么说 Swift 性能相比较于 Objective-C 会更加 好 ?
为什么在编译 Swift 的时候这么慢 ?
如何更优雅的去写 Swift ?
Swift中的类型
首先,我们先统一一下关于类型的几个概念。
平凡类型
有些类型只需要按照字节表示进行操作,而不需要额外工作,我们将这种类型叫做平凡类型 (trivial)。比如,Int 和 Float 就是平凡类型,那些只包含平凡值的 struct 或者 enum 也是平凡类型。
struct AStruct {
var a: Int
}struct BStruct {
var a: AStruct
}// AStruct & BStruct 都是平凡类型引用类型
对于引用类型,值实例是一个对某个对象的引用。复制这个值实例意味着创建一个新的引用,这将使引用计数增加。销毁这个值实例意味着销毁一个引用,这会使引用计数减少。不断减少引用计数,最后当然它会变成 0,并导致对象被销毁。但是需要特别注意的是,我们这里谈到的复制和销毁值,只是对引用计数的操作,而不是复制或者销毁对象本身。
struct CStruct { var a: Int
}class AClass { var a: CStruct
}class BClass { var a: AClass
}// AClass & BClass 都是引用类型组合类型
类似 AClass 这类,引用类型包含平凡类型的,其实还是引用类型,但是对于平凡类型包含引用类型,我们暂且称之为组合类型。
struct DStruct {
var a: AClass
}// DStruct 是组合类型影响性能的主要因素
主要原因在下面几个方面:
内存分配 (Allocation):主要在于 堆内存分配 还是 栈内存分配。
引用计数 (Reference counting):主要在于如何 权衡 引用计数。
方法调度 (Method dispatch):主要在于 静态调度 和 动态调度 的问题。
内存分配(Allocation)
内存分区 中的 堆 和 栈。
堆(heap)**
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或 缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张); 当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈 (stack heap)**
栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}” 中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外, 在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值 也会被存放回栈中。由于栈的后进先出特点,所以 栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
在 Swift 中,对于 平凡类型 来说都是存在 栈 中的,而 引用类型 则是存在于 堆 中的,如下图所示:
我们都知道,Swift建议我们多用 平凡类型,那么 平凡类型 比 引用类型 好在哪呢?换句话说「在 栈 中的数据和 堆 中的数据相比有什么优势?」
数据结构
存放在栈中的数据结构较为简单,只有一些值相关的东西
存放在堆中的数据较为复杂,如上图所示,会有type、retainCount等。
数据的分配与读取
存放在栈中的数据从栈区底部推入 (push),从栈区顶部弹出 (pop),类似一个数据结构中的栈。由于我们只能够修改栈的末端,因此我们可以通过维护一个指向栈末端的指针来实现这种数据结构,并且在其中进行内存的分配和释放只需要重新分配该整数即可。所以栈上分配和释放内存的代价是很小。
存放在堆中的数据并不是直接 push/pop,类似数据结构中的链表,需要通过一定的算法找出最优的未使用的内存块,再存放数据。同时销毁内存时也需要重新插值。
多线程处理
栈是线程独有的,因此不需要考虑线程安全问题。
堆中的数据是多线程共享的,所以为了防止线程不安全,需同步锁来解决这个问题题。
综上几点,在内存分配的时候,尽可能选择 栈 而不是 堆 会让程序运行起来更加快。
引用计数(Reference counting)
首先 引用计数 是一种 内存管理技术,不需要程序员直接去操作指针来管理内存。
而采用 引用计数 的 内存管理技术,会带来一些性能上的影响。主要以下两个方面:
需要通过大量的 release/retain 代码去维护一个对象生命周期。
存放在 堆区 的是多线程共享的,所以对于 retainCount 的每一次修改都需要通过同步锁等来保证线程安全。
对于 自动引用计数 来说, 在添加 release/retain 的时候采用的是一个宁可多写也不漏写的原则,所以 release/retain 有一定的冗余。这个冗余量大概在 10% 的左右(如下图,图片来自于ios可执行文件瘦身方法)。
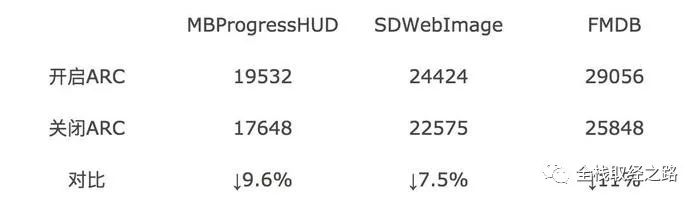
而这也是为什么虽然 ARC 底层对于内存管理的算法进行了优化,在速度上也并没有比 MRC 写出来的快的原因。这篇文章 详细描述了 ARC 和 MRC 在速度上的比较。
综上,虽然因为自动引用计数的引入,大大减少了内存管理相关的事情,但是对于引用计数来说,过多或者冗余的引用计数是会减慢程序的运行的。
而对于引用计数来说,还有一个权衡问题,具体如何权衡会再后文解释。
方法调度 (Method dispatch)
在 Swift 中, 方法的调度主要分为两种:
静态调度: 可以进行inline和其他编译期优化,在执行的时候,会直接跳到方法的实现。
struct Point {
var x, y: Double func draw() { // Point.draw implementation
}
}func drawAPoint(_ param: Point) {
param.draw()
}
let point = Point(x: 0, y: 0)
drawAPoint(point)// 1.编译后变为下面的inline方式point.draw()// 2.运行时,直接跳到实现 Point.draw implementation动态调度: 在执行的时候,会根据运行时,采用 V-Table 的方式,找到方法的执行体,然后执行。无法进行编译期优化。V-Table 不同于 OC 的调度,在 OC 中,是先在运行时的时候先在子类中寻找方法,如果找不到,再去父类寻找方法。而对于 V-Table 来说,它的调度过程如下图:
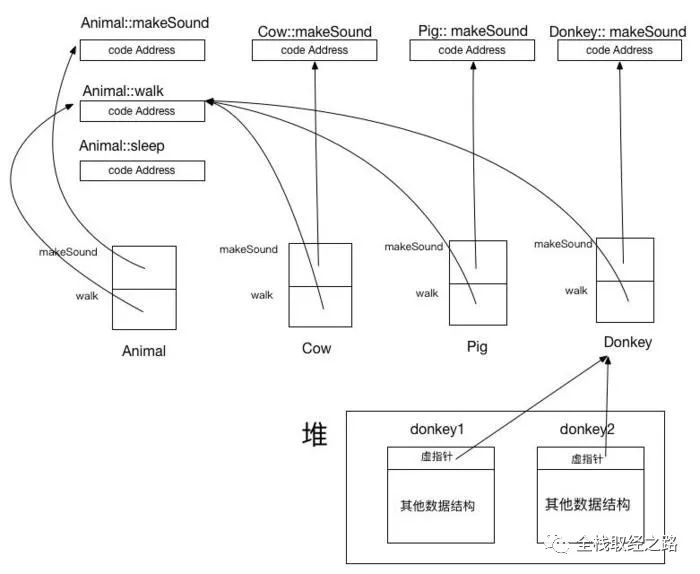
因此,在性能上「静态调度 > 动态调度」并且「Swift中的V-Table > Objective-C 的动态调度」。
协议类型 (Protocol types)
在 Swift 引入了一个 协议类型 的概念,示例如下:
protocol Drawable {
func draw()
}
struct Point : Drawable { var x, y: Double
func draw() { ... }
}
struct Line : Drawable { var x1, y1, x2, y2: Double
func draw() { ... }
}var drawables: [Drawable]// Drawable 就称为协议类型for d in drawables {
d.draw()
}在上述代码中,Drawable 就称为协议类型,由于 平凡类型 没有继承,所以实现多态上出现了一些棘手的问题,但是 Swift 引入了 协议类型 很好的解决了 平凡类型 多态的问题,但是在设计 协议类型 的时候有两个最主要的问题:
对于类似 Drawable 的协议类型来说,如何去调度一个方法?
对于不同的类型,具有不同的size,当保存到 drawables 数组时,如何保证内存对齐?
对于第一个问题,如何去调度一个方法?因为对于 平凡类型 来说,并没有什么虚函数指针,所以在 Swift 中并没有 V-Table 的方式,但是还是用到了一个叫做 The Protocol Witness Table (PWT) 的函数表,如下图所示:
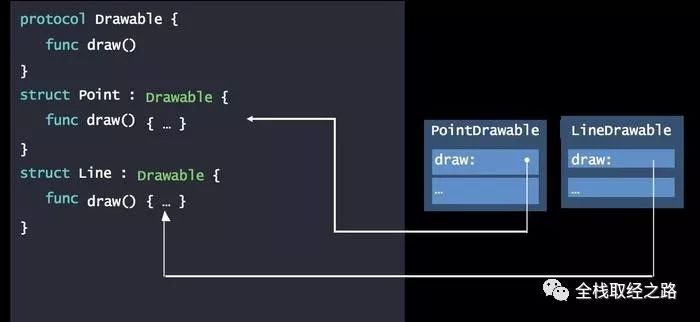
对于每一个 Struct:Protocol 都会生成一个 StructProtocol 的 PWT。
对于第二个问题,如何保证内存对齐问题?
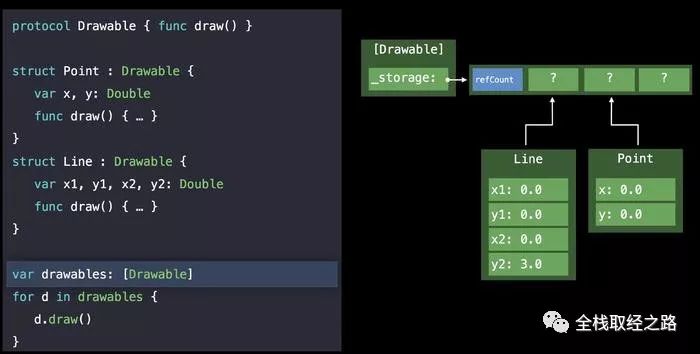
有一个简单粗暴的方式就是,取最大的Size作为数组的内存对齐的标准,但是这样一来不但会造成内存浪费的问题,还会有一个更棘手的问题,如何去寻找最大的Size。所以为了解决这个问题,Swift 引入一个叫做 Existential Container 的数据结构。

Existential Container
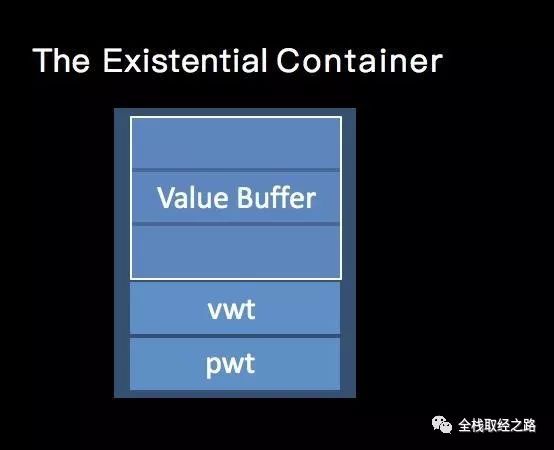
这是一个最普通的 Existential Container。
前三个word:Value buffer。用来存储Inline的值,如果word数大于3,则采用指针的方式,在堆上分配对应需要大小的内存
第四个word:Value Witness Table(VWT)。每个类型都对应这样一个表,用来存储值的创建,释放,拷贝等操作函数。(管理 Existential Container 生命周期)
第五个word:Protocol Witness Table(PWT),用来存储协议的函数。
用伪代码表示如下:
// Swift 伪代码struct ExistContDrawable { var valueBuffer: (Int, Int, Int) var vwt: ValueWitnessTable var pwt: DrawableProtocolWitnessTable
}所以,对于上文代码中的 Point 和 Line 最后的数据结构大致如下:
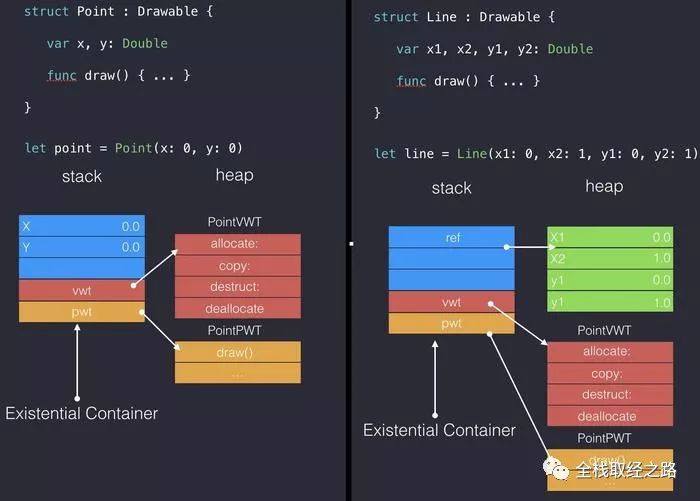
这里需要注意的几个点:
在 ABI 稳定之前 value buffer 的 size 可能会变,对于是不是 3个 word 还在 Swift 团队还在权衡.
Existential Container 的 size 不是只有 5 个 word。示例如下:
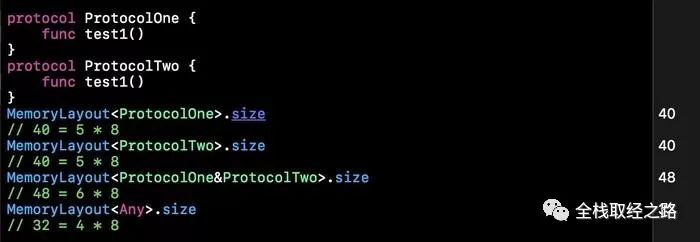
对于这个大小差异最主要在于这个 PWT 指针,对于 Any 来说,没有具体的函数实现,所以不需要 PWT 这个指针,但是对于 ProtocolOne&ProtocolTwo 的组合协议,是需要两个 PWT 指针来表示的。
OK,由于 Existential Container 的引入,我们可以将协议作为类型来解决 平凡类型 没有继承的问题,所以 Struct:Protocol 和 抽象类就越来越像了。
回到我们最初的疑问,「在 Swift 中的, Struct:Protocol 比 抽象类 好在哪里?」
由于 Swift 只能是单继承,所以 抽象类 很容易造成 「上帝类」,而Protocol可以是一个多这多个则没有这个问题
在内存分配上上,Struct是在栈中的,而抽象类是在堆中的,所以简单数据的Struct:Protocol会再性能上比抽象类更加好
(写起来更加有逼格算不算?)
但是,虽然表面上协议类型确实比抽象类更加的“好”,但是我还是想说,不要随随便便把协议当做类型来使用。
为什么这么说?先来看一段代码:
struct Pair {
init(_ f: Drawable, _ s: Drawable) {
first = f ; second = s
}
var first: Drawable
var second: Drawable
}首先,我们把 Drawable 协议当做一个类型,作为 Pair 的属性,由于协议类型的 value buffer 只有三个 word,所以如果一个 struct(比如上文的Line) 超过三个 word,那么会将值保存到堆中,因此会造成下图的现象:
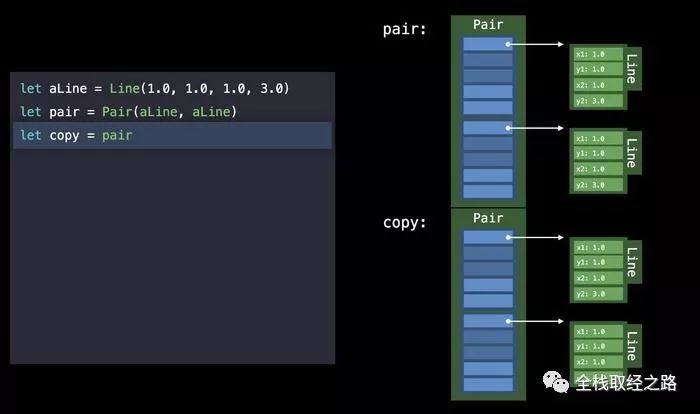
一个简单的复制,导致属性的copy,从而引起 大量的堆内存分配。
所以,不要随随便便把协议当做类型来使用。上面的情况发生于无形之中,你却没有发现。
当然,如果你非要将协议当做类型也是可以解决的,首先需要把Line改为class而不是struct,目的就是引入引用计数。所以,将Line改为class之后,就变成了如下图所示:
至于修改了 line 的 x1 导致所有 pair 下的 line 的 x1 的值都变了,我们可以引入 Copy On Write 来解决。
当我们 Line 使用平凡类型时,由于line占用了4个word,当把协议作为类型时,无法将line存在 value buffer 中,导致了堆内存分配,同时每一次复制都会引发堆内存分配,所以我们采用了引用类型来替代平凡类型,增加了引用计数而降低了堆内存分配,这就是一个很好的引用计数权衡的问题。
泛型(Generic code)
首先,如果我们把协议当做类型来处理,我们称之为 「动态多态」,代码如下:
protocol Drawable {
func draw()
}
func drawACopy(local : Drawable) {
local.draw()
}let line = Line()
drawACopy(line)
// ...let point = Point()
drawACopy(point)而如果我们使用泛型来改写的话,我们称之为 「静态多态」,代码如下:
// Drawing a copy using a generic methodprotocol Drawable {
func draw()
}
func drawACopy<T: Drawable>(local : T) {
local.draw()
}let line = Line()
drawACopy(line)// ...let point = Point()
drawACopy(point)而这里所谓的 动态 和 静态 的区别在哪里呢?
在 Xcode 8 之前,唯一的区别就是由于使用了泛型,所以在调度方法是,我们已经可以根据上下文确定了这个 T 到底是什么类型,所以并不需要 Existential Container,所以泛型没有使用 Existential Container,但是因为还是多态,所以还是需要VWT和PWT作为隐形参数传递,对于临时变量仍然按照ValueBuffer的逻辑存储 - 分配3个word,如果存储数据大小超过3个word,则在堆上开辟内存存储。如图所示:
这样的形式其实和把协议作为类型并没有什么区别。唯一的就是没有 Existential Container 的中间层了。
但是,在 Xcode 8 之后,引入了 Whole-Module Optimization 使泛型的写法更加静态化。
首先,由于可以根据上下文知道确定的类型,所以编译器会为每一个类型都生成一个drawACopy的方法,示例如下:
func drawACopy<T : Drawable>(local : T) {
local.draw()
}
// 编译后
func drawACopyOfALine(local : Line) {
local.draw()
}
func drawACopyOfAPoint(local : Point) {
local.draw()
}
//比如:
drawACopy(local: Point(x: 1.0, y: 1.0))
//变为
drawACopyOfAPoint(local : Point(x: 1.0, y: 1.0))由于每个类型都生成了一个drawACopy的方法,drawACopyOfAPoint的调用就吧编程了一个静态调度,再根据前文静态调度的时候,编译器会做 inline 处理,所以上面的代码经过编译器处理之后代码如下:
drawACopy(local: Point(x: 1.0, y: 1.0))
//会变为
Point(x: 1.0, y: 1.0).draw()由于编译器一步步的处理,再也不需要 vwt、pwt及value buffer了。所以对于泛型来做多态来说,就叫做静态多态。
几点总结
为什么在编译 Swift 的时候这么慢
因为编译做了很多事情,例如 静态调度的inline处理,静态多态的分析处理等
为什么说 Swift 相比较于 Objective-C 会更加快
对于Swift来说,更多的静态的,比如静态调度、静态多态等。
更多的栈内存分配
更少的引用计数
如何更优雅的去写 Swift
不要把协议当做类型来处理
如果需要把协议当做类型来处理的时候,需要注意 big Value 的复制就引起堆内存分配的问题。可以用 Indirect Storage + Copy On Write 来处理。
对于一些抽象,可以采用 Struct:Protocol 来代替抽象类。至少不会有上帝类出现,而且处理的好的话性能是比抽象类更好的。
以上是关于Swift 性能相关的主要内容,如果未能解决你的问题,请参考以下文章
如何将这个 Objective-C 代码片段写入 Swift?
如何使用 Swift 使用此代码片段为 iOS 应用程序初始化 SDK?