Spark处理复杂类型数据
Posted 大数据杂烩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark处理复杂类型数据相关的知识,希望对你有一定的参考价值。
一、背景介绍
Spark处理的复杂数据类型有Struct、Array、Map、JSON等,今天介绍一下Struct类型,节后第一天上班,线上一堆问题,查看后是Spark对复杂数据类型的数据处理有问题,因为节前数据流走向和处理都是没有问题的,查找日志后显示mongdb中有存在Struct类型的数据,Spark在读取计算后无法存入Hive表,原因是Spark中操作mongdb以后数据存入Hive默认Parquet格式不支持原有的Struct格式数据。
二、运行报错
三、解决思路
1.针对mongdb里面数据进行数据格式转换,但是转换以后出现了新问题,就是原有的数据字段有部分不会显示,就算数据显示了,也存在值的缺省。
2.针对mongdb里面数据字段进行拆分,因为数据是一条一条处理的,所以拆分后的数据也是一条完整的数据,对字段进行拼接然后在存入Hive表。
四、数据类型的比对
拆分前Schema
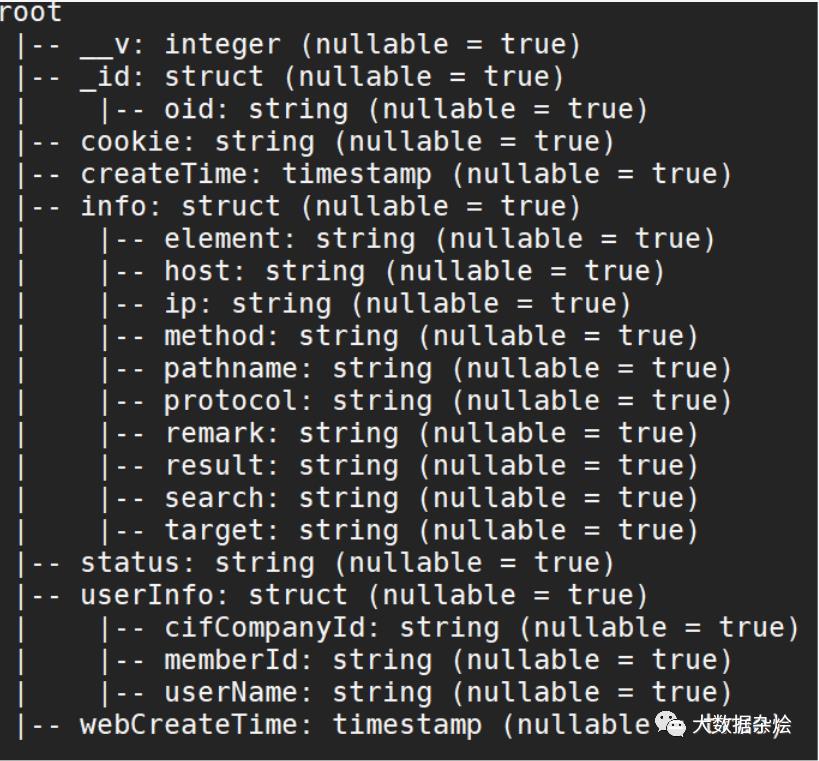
拆分后Schema
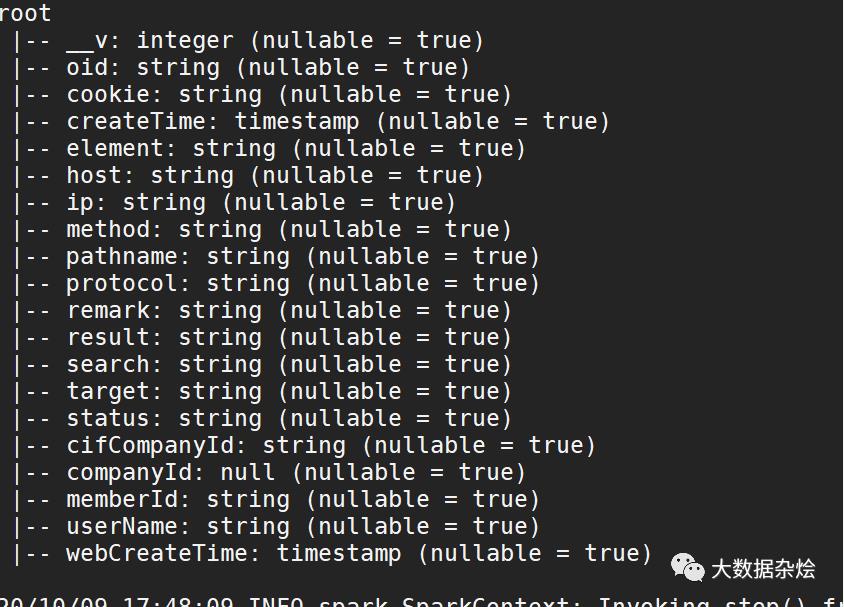
不难看出在拆分前数据类型部分是Struct格式的,拆分后针对数据类型现在变成了正常的数据类型的处理,其实最为重要对于后面处理数据的兄弟也是方便了很多。
五、上代码
数据类型更改前代码
更改后代码
由于现在companyId类型为null业务上也没有用到直接删除,针对Mongdb数据Struct格式数据其实也就是JSON格式数据
直接运行代码就OK了
以上是关于Spark处理复杂类型数据的主要内容,如果未能解决你的问题,请参考以下文章