Spark之正则表达式与处理日期与时间类型
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark之正则表达式与处理日期与时间类型相关的知识,希望对你有一定的参考价值。
🌵今天继续给大家介绍pyspark的内容之匹配字符和处理时间类型的数据,我们在前面还给大家介绍了spark处理其他类型数据的方法,有兴趣的小伙伴可以查看下面文章👇:
🌕今天主要来学习spark在字符串中搜索子串,替换被选中的字符等,以及处理时间类型数据的方法,尤其是对时间序列的处理在后面机器学习的部分有很大的帮助。
目录
1.正则表达式
spark充分利用了Java正则表达式的强大功能,但是java正则化表达式与其他语言的正则表达式有微小的差别,因此实际应用之前需要检查,想要进行正则表达式操作,需要知道两个函数——regexp_extract和regexp_replace
1.1 regexp_replace 替换值
如我们利用regexp_extract函数替换掉Description列中的颜色名。
#使用字符“color”替换Black|WHITE|RED|GREEN|BLUE这些字符
from pyspark.sql.functions import regexp_replace,col
regex_string="Black|WHITE|RED|GREEN|BLUE"
df.select(
regexp_replace(col("Description"),regex_string,"color").alias("color_clean"),col("Description")).show(5,False)
看看效果:替换成功

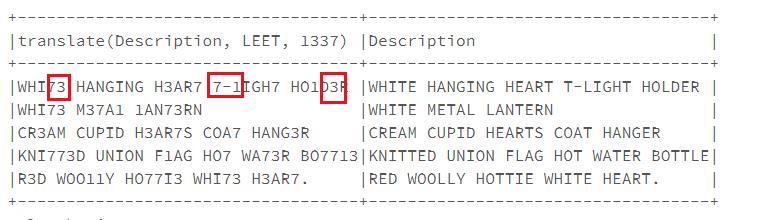
1.2 translate字符级替换
translate可以实现将单词中的字符进行替换,比使用正则表达式方便多了。
#实现L-1,E-3,T-7转换
from pyspark.sql.functions import translate#L=1,E=3,T=7
df.select(translate(col("Description"),"LEET","1337"),col("Description")).show(5,False)
效果如下:
1.3 regexp_extract 提取值
有时候我们不需要提替换值只需要提取值,这时就是使用regexp_extract 函数
例如:取出第一个出现的颜色
#取出第一个被提及的颜色regexp_extract
from pyspark.sql.functions import regexp_extract
extrect_str="(Black|WHITE|RED|GREEN|BLUE)"
df.select(
regexp_extract(col("Description"),extrect_str,1).alias("color_clean"),col("Description")).show(5,False)
结果如下:

1.4 contains 是否存在字符
有时候我们不需要提取、替换字符,只需要判断是否存在即可,在scala中可以使用contains函数返回一个布尔类型的数据判断是否存在,但在python中,我们可以使用instr这个函数来判断
#我们有时候不需要提取字符,只是想检查他们是否存在,scala中有contains,python中用instr即可
from pyspark.sql.functions import instr
containsBlack=instr(col("Description"),"BLACK")>=1
containsWhite=instr(col("Description"),"WHITE")>=1
df.withColumn("hasssimplecolor",containsBlack|containsWhite).where("hasssimplecolor").select("Description").show(3,False)
效果如下:返回含有BLACK或者WHITE的值。

1.5 locate 返回位置(int类型)
类似于instr函数都是返回字符出现的位置,但locate可以指定从哪个字符开始LOCATE(substr,str,pos),从str的第pos位置开始查找substr
#仅有两个值看起来很简单,有多个值时我们可以使用数组来接受参数,使用locate函数返回整数位置然后转换为布尔类型的数据。显示包含["black", "white", "red", "green", "blue"]的行
from pyspark.sql.functions import expr, locate
simpleColors = ["black", "white", "red", "green", "blue"]
def color_locator(column, color_string):
return locate(color_string.upper(), column).cast("boolean").alias("is_" + color_string)
selectedColumns = [color_locator(df.Description, c) for c in simpleColors]
selectedColumns.append(expr("*")) # has to a be Column type
df.select(*selectedColumns).where(expr("is_white OR is_red")).select("Description").show(3, False)
结果如下:

2.处理时间数据
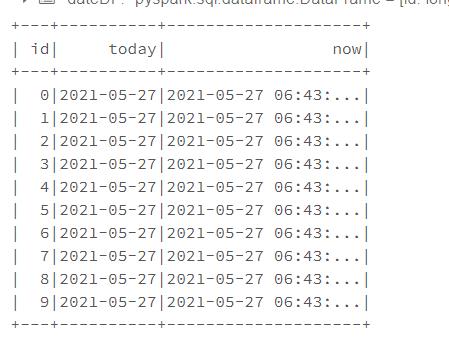
2.1 获取当前日期和时间
使用current_date获取日期;current_timestamp获取当前时间(尴尬:服务器时间和我的不一样)
#构建了一个10行时间数据的Dataframe
from pyspark.sql.functions import current_date, current_timestamp
dateDF = spark.range(10).withColumn("today", current_date()).withColumn("now", current_timestamp())
dateDF.show()
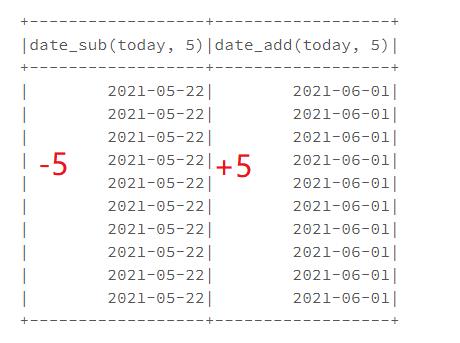
2.1 日期相加减天数
可以使用date_sub减法,和date_add加法对日期进行加减
from pyspark.sql.functions import date_add,date_sub
dateDF.select(date_sub(col("today"),5),date_add(col("today"),5)).show()
结果如下:
2.2 两日期相加减
查看两个日期之间的时间间隔,我们可以使用以下函数:
- datediff 返回两个日期之间的天数
- months_between 返回两个日期之间的相隔月数
from pyspark.sql.functions import datediff, months_between, to_date,lit
#先将日期加7天,再计算和当当前时间的天数
dateDF.withColumn("week_ago", date_sub(col("today"), 7)).select(datediff(col("week_ago"), col("today"))).show(1)
#计算两个日期之间的月数
dateDF.select(
to_date(lit("2020-01-01")).alias("start"),
to_date(lit("2021-05-27")).alias("end")).select(months_between(col("start"), col("end"))).show(1)
结果如下:

2.3 日期格式的转换
格式的转换一般使用to_date和to_timestamp,一个是转化为日期,一个是转换为时间戳。
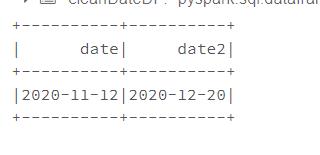
日期类型数据的转换to_date
#告诉spark日期形式,然后将这种类型的形式的数据都转化为年-月-日形式的数据,
#例如将年-日-月的数据转换为年-月-日
from pyspark.sql.functions import to_date
dateFormat = "yyyy-dd-MM"
cleanDateDF = spark.range(1).select(
to_date(lit("2020-12-11"), dateFormat).alias("date"),
to_date(lit("2020-20-12"), dateFormat).alias("date2"))
cleanDateDF.show()
结果如下: 转化成功
时间戳类型数据的转换to_timestamp
#这里的dateFormat与to_date的一样,但是会返回时间戳
from pyspark.sql.functions import to_timestamp
cleanDateDF.select(to_timestamp(col("date"), dateFormat)).show()
结果如下:

需要注意:spark在处理时间类型的数据时,如果spark无法解析时间类型的数据,它不会报错,它会返回null值
参考资料
《Hadoop权威指南》
《大数据hadoop3.X分布式处理实战》
《Spark权威指南》
《Pyspark实战》
以上是关于Spark之正则表达式与处理日期与时间类型的主要内容,如果未能解决你的问题,请参考以下文章