技术猩球王玉明:Spark Adaptive Execution 帮助 eBay 解决的重要问题
Posted 七牛云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术猩球王玉明:Spark Adaptive Execution 帮助 eBay 解决的重要问题相关的知识,希望对你有一定的参考价值。
嘉宾简介
王玉明,eBay INDE 小组的软件工程师,专注于 Spark 优化。同时是 Apache Spark 的 Committer。
在「七牛云 Niu Talk 」数据科学系列论坛直播中,王玉明老师主要分享了 Spark Adaptive Execution 帮助 eBay 解决的一些问题,王玉明老师是一名 Spark Committer,主要关注 Spark SQL 模块的优化,其中包括:Spark Adaptive Query Execution 优化、dynamic partition pruing 和 data cache(在两个 HDFS 之间访问数据、物化视图、基于 Bloom Filter 的 index、shuffle pruning、更出色的 data layout 等优化。
演讲实录
王玉明老师今天分享的集群主要负责 Ad-hoc query cluster,包含 1600 多台机器、900 TB 的 memory 和 10 个 queue,每天有超过 10w 的查询,其中 90% 的 query duration 都小于 1 分钟。
eBay 需要 Adaptive Query Execution 的原因
Adaptive Query Execution 可以帮助 eBay 解决三个重要问题,第一,动态设置 shuffle partition 数量;第二,动态优化 join 规则;第三,处理 skew join 的 case 。
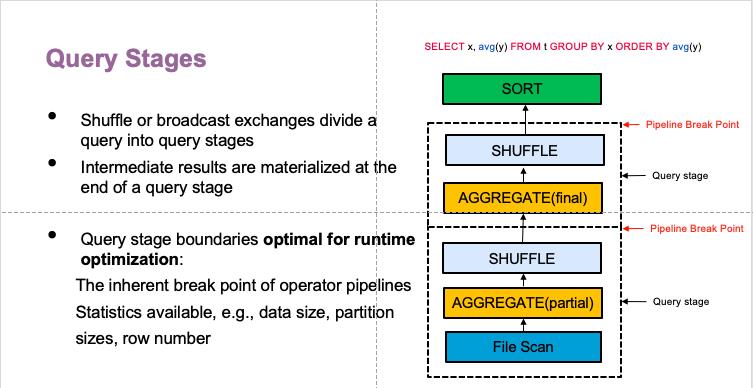
举个例子,图中右上角的 query 有两个 shuffle :一个 aggregation shuffle ,一个order by shuffle。按照 shuffle 的点分成两个 query stage,这样 shuffle 数据物化后就能了解每一个 partition 的 size 以及行数。
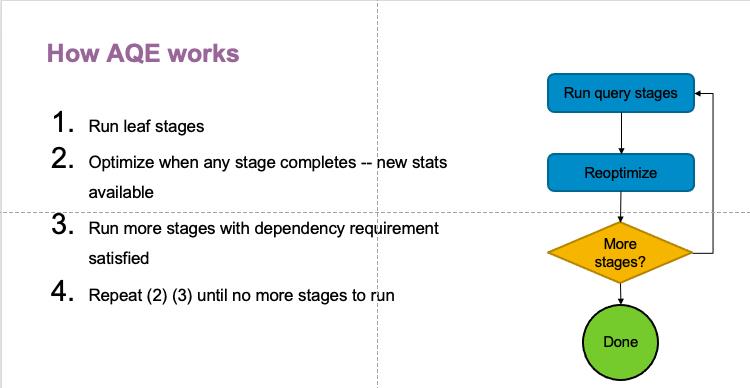
partition size 可以优化 skewed 的场景,data size 和行数可以优化 join 策略。下图是query stage 的工作流程。先跑下面的 query stage,再用跑完的 query stage 的统计数据来优化接下来的 query stage,直到运行结束。
动态设置 shuffle partition 的数量:这个参数设置小会产生 GC、Disk spilling、查询性能等问题,设置大会产生小文件的问题,因此对用户而言很难设置合适的参数。
AQE 可以先设置一个较大 shuffle partition 数量 ,再根据经常查的 query 和集群情况 更新设置。比如,初始数量是 10000,后面根据 query stage 的统计信息,可能只需要 500 或 1000 个 reduce 来处理数据。
Shuffle partition 的工作流程
如上图所示:有 P0、P1、P2、P3、P4,5 个 mapper,其中 P1、P2、P3 size 非常小。到 reducer 这一侧就可以把 P1、P2、P3 合成一个 reducer ,前面有 5 个 mapper,而后面只需要 3 个 reducer 。
优化 join 的 strategy
Spark 可以根据 size 选择 Broadcast Hash Join/Broadcast Nested LoopJoin 。但是 size 经常不准或者数量比较复杂。Adaptive query execution 会根据运行时的 data size 来动态调整 join 策略。
最后,王玉明老师分享了处理 skewed join 场景。当数据在群集中的分区之间分布不均时,就会发生数据倾斜,严重的偏斜会严重降低查询性能。AQE skew join 会从 shuffle 统计信息中自动检测这种偏斜。然后将偏斜的分区拆分为较小的子分区,这些子分区将分别从另一侧连接到相应的分区。
总结一下,今天的分享主要可以概括为以下两点:
动态的设置 shuffle partition 的数量更易用;
动态优化 join 和处理 skew join 提升查询性能。
「七牛云 Niu Talk 」数据科学系列论坛干货回顾
点击阅读原文
了解更多七牛云信息
以上是关于技术猩球王玉明:Spark Adaptive Execution 帮助 eBay 解决的重要问题的主要内容,如果未能解决你的问题,请参考以下文章
Spark3自适应查询计划(Adaptive Query Execution,AQE)
Spark3 AQE (Adaptive Query Execution) 一文搞懂 新特性