Spark Operator 初体验
Posted 民生运维人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Operator 初体验相关的知识,希望对你有一定的参考价值。
关于存算分离
目前企业级的大数据应用主流还是采用Yarn或者Mesos来进行资源分配和运行调度的,例如我行目前采用Yarn来进行作业调度,并使用HDFS作为大数据的存储平台,这是典型的计算和存储紧耦合的模式,这种方案是通过数据本地化策略来减少数据的网络传输,从而实现良好的计算性能。
随着业务的发展,支持作业运行所需要的计算资源(CPU、内存、网络带宽)的需求量也会不断增长,就可能出现Hadoop集群的计算资源不足的情况,在目前的架构下我们只能通过扩容集群服务器的方式来解决,然而这种方式的步骤较为繁琐,且无法实现计算资源的弹性伸缩,时效性和灵活性较差 。而Spark作业通过Kubernetes进行资源管理和调度的方案可以方便地实现计算资源的动态调整,从而快速适应业务场景的变化,并且还可以实现硬件资源的充分利用并节约成本。
存算分离:将计算模块改为运行在K8S集群中来实现计算资源的快速调整;而存储模块由于状态复杂,并且不需要进行快速的资源调整和变化,因此可以将计算模块与存款模块分离开来,即近期讨论较多的存算分离的模式。
Spark Operator
Spark是目前在我行使用范围非常广泛的一种大数据计算引擎,本文将主要讨论Spark on K8S的实现。
我们也可以采用Spark Operator的方式,Spark Operator( https://github.com/GoogleCloudPlatform/spark-on-k8s-operator )是由谷歌发起和维护的开源项目,它将Spark和Kubernetes进行了深度的集成,是一个可以管理Spark应用程序生命周期的Kubernetes插件。开发人员通过编写yaml文件即可在K8S集群上提交Spark作业,而不需要在客户机上配置spark-submit工具。
Spark Operator还提供了强大的作业管理功能,例如使用sparkctl命令来执行创建、查看、停止作业来管理Spark作业的生命周期,还支持通过ingress的服务暴露模式来访问作业的UI界面。本文中将主要介绍Spark Operator这种作业运行模式。
Operator是由CoreOS公司推出的, 通过定义CRD(CustomResourceDefinition)和实现相应的Controller来扩展Kubernetes 集群的功能。CRD是从Kubernetes 1.7 版本开始引入的概念,它可以注册到 kubernetes 集群中,使得用户可以像使用原生的集群资源(例如 pod、deployment)一样对CRD对象进行创建、查看、删除等操作;Controller则会监听资源的状态变化并进行处理,尝试让CRD 定义的资源达到预期的状态。
接下来我们来看一下SparkOperator的相关实现原理。
Spark Operator架构
Spark Operator的主要组件如下:
其中,Controller是作为Spark Operator的核心组件,用于控制和处理pod以及应用运行的状态变化。
如下代码片段展示了Controller更新Driver和Executor Pod状态变化的逻辑:
func (c *Controller) getAndUpdateAppState(app *v1beta2.SparkApplication) error {
if err := c.getAndUpdateDriverState(app); err != nil {
return err
}
if err := c.getAndUpdateExecutorState(app); err != nil {
return err
}
return nil
}
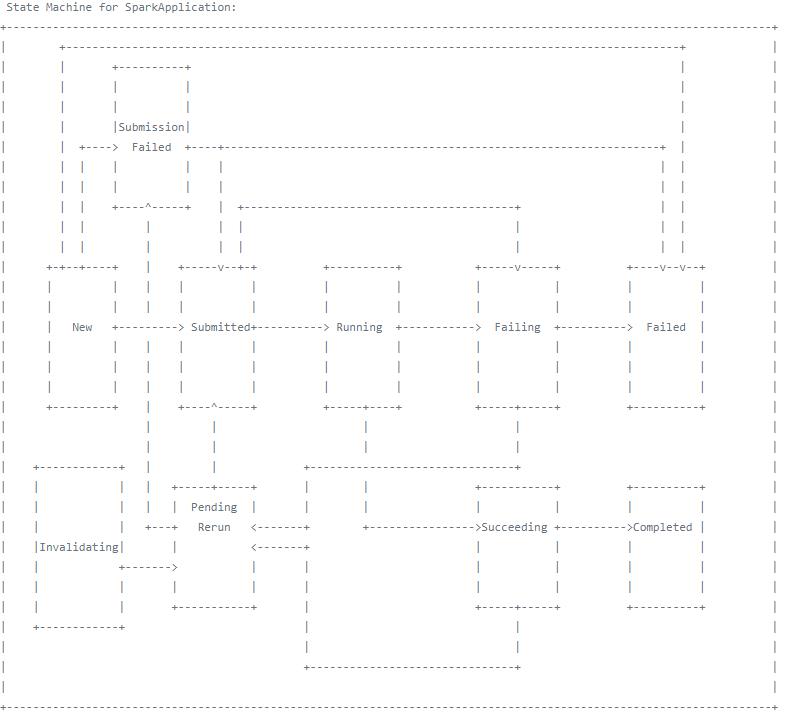
Spark 应用的状态机图示如下:
如下代码片段展示了Controller更新application应用状态的相关操作:
func (c *Controller) syncSparkApplication(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
...
// Take action based on application state.
switch appCopy.Status.AppState.State {
case v1beta2.NewState:
c.recordSparkApplicationEvent(appCopy)
if err := c.validateSparkApplication(appCopy); err != nil {
appCopy.Status.AppState.State = v1beta2.FailedState
appCopy.Status.AppState.ErrorMessage = err.Error()
} else {
appCopy = c.submitSparkApplication(appCopy)
}
case v1beta2.SucceedingState:
if !shouldRetry(appCopy) {
appCopy.Status.AppState.State = v1beta2.CompletedState
c.recordSparkApplicationEvent(appCopy)
} else {
if err := c.deleteSparkResources(appCopy); err != nil {
glog.Errorf("failed to delete resources associated with SparkApplication %s/%s: %v",
appCopy.Namespace, appCopy.Name, err)
return err
}
appCopy.Status.AppState.State = v1beta2.PendingRerunState
}
...
}
Spark Operator通过启动一个监听对象ResourceUsageWatcher来实时监听和更新集群资源的使用情况:
func newResourceUsageWatcher(crdInformerFactory crdinformers.SharedInformerFactory, coreV1InformerFactory informers.SharedInformerFactory) ResourceUsageWatcher {
glog.V(2).Infof("Creating new resource usage watcher")
r := ResourceUsageWatcher{
crdInformerFactory: crdInformerFactory,
currentUsageLock: &sync.RWMutex{},
coreV1InformerFactory: coreV1InformerFactory,
currentUsageByNamespace: make(map[string]*ResourceList),
usageByNamespacePod: make(map[string]map[string]*ResourceList),
usageByNamespaceScheduledApplication: make(map[string]map[string]*ResourceList),
usageByNamespaceApplication: make(map[string]map[string]*ResourceList),
}
// Note: Events for each handler are processed serially, so no coordination is needed between
// the different callbacks. Coordination is still needed around updating the shared state.
sparkApplicationInformer := r.crdInformerFactory.Sparkoperator().V1beta2().SparkApplications()
sparkApplicationInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: r.onSparkApplicationAdded,
UpdateFunc: r.onSparkApplicationUpdated,
DeleteFunc: r.onSparkApplicationDeleted,
})
scheduledSparkApplicationInformer := r.crdInformerFactory.Sparkoperator().V1beta2().ScheduledSparkApplications()
scheduledSparkApplicationInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: r.onScheduledSparkApplicationAdded,
UpdateFunc: r.onScheduledSparkApplicationUpdated,
DeleteFunc: r.onScheduledSparkApplicationDeleted,
})
r.podInformer = r.coreV1InformerFactory.Core().V1().Pods()
r.podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: r.onPodAdded,
UpdateFunc: r.onPodUpdated,
DeleteFunc: r.onPodDeleted,
})
return r
}
当发生新增应用的调度请求、应用状态更新,以及新增Pod或者Pod状态更新等情况下,均可触发ResourceUsageWatcher的相关操作。例如在onPodUpdated方法中,通过调用ResourceUsageWatcher的setResources来实时更新集群当前的可调度资源:
func (r *ResourceUsageWatcher) onPodUpdated(oldObj, newObj interface{}) {
newPod := newObj.(*corev1.Pod)
if !launchedBySparkOperator(newPod.ObjectMeta) {
if newPod.Status.Phase == corev1.PodFailed || newPod.Status.Phase == corev1.PodSucceeded {
r.deleteResources("Pod", namespaceOrDefault(newPod.ObjectMeta), newPod.ObjectMeta.Name, r.usageByNamespacePod)
} else {
r.setResources("Pod", namespaceOrDefault(newPod.ObjectMeta), newPod.ObjectMeta.Name, podResourceUsage(newPod), r.usageByNamespacePod)
}
}
}
搭建运行环境
接下来我们通过一个实验来测试一下Spark Operator的相关特性。
1.本实验环境所采用的K8S集群为1.15.12 版本,Spark 采用3.0.0版本。
2.Hadoop集群采用的是CDH 5.13版本,Hadoop的版本为2.6.0。
3.下载并编译Spark Operator :
[root@master ~]# git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
[root@master ~]# cd spark-on-k8s-operator-master
docker build --build-arg SPARK_IMAGE=gcr.io/spark-operator/spark:v3.0.0 -t joanjiao2016/sparkoperator:v3.0.0 .
在sparkctl目录下执行编译得到sparkctl工具,并将sparkctl 拷贝到/usr/bin目录下,即可使用sparkctl命令行工具。
[root@master spark-on-k8s-operator-master]# cd sparkctl && go build -o sparkctl
[root@master sparkctl]# chmod 755 sparkctl
[root@master sparkctl]# mv sparkctl /usr/bin
4.为Spark Operator插件创建namespace:
kubectl create namespace spark-operator
5.通过helm安装Spark Operator :
helm install incubator/sparkoperator \
--namespace spark-operator \
--set sparkJobNamespace=default \
--set operatorImageName=gcr.io/spark-operator/spark-operator \
--set operatorVersion=v1beta2-1.2.0-3.0.0 \
--set enableWebhook=true \
--set ingressUrlFormat="\{\{\$appName\}\}.joanjiao2016.com" \
--set enableBatchScheduler=true \
--generate-name
6.创建Spark作业的ServiceAccount相关权限对象
在本实验中ServiceAccount资源的创建使用的是官网上的示例yaml文件,其中ServiceAccount设置为spark,实际工作中我们也可以定义自己的ServiceAccount、Role和RoleBinding资源,并在作业提交时指定相应的对象名称即可。
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: spark-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["*"]
- apiGroups: [""]
resources: ["services"]
verbs: ["*"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: spark-role-binding
namespace: default
subjects:
- kind: ServiceAccount
name: spark
namespace: default
roleRef:
kind: Role
name: spark-role
apiGroup: rbac.authorization.k8s.io
一个操作HDFS文件的wordcount实例
编写示例代码
本项目中的代码是一个简单的Spark wordcount程序,通过读取存储在HDFS上的文本文件,并利用Spark计算出在该文本中每个单词的出现频率。同时采用Kerberos的认证方式来实现对HDFS的安全访问。
本示例中所采用的分布式文件系统是HDFS,后续我们也将考虑使用对象存储平台来做测试。
主要代码如下:
import org.apache.hadoop.security.UserGroupInformation
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val sparkconf = new SparkConf().setAppName("words")
val sc = new SparkContext(sparkconf)
val config = sc.hadoopConfiguration
config.addResource("/opt/hadoop/conf/hdfs-site.xml")
config.addResource("/opt/hadoop/conf/resources/core-site.xml")
config.set("hadoop.security.authentication","kerberos")
System.setProperty("java.security.krb5.conf","/etc/krb5.conf")
UserGroupInformation.setConfiguration(config)
UserGroupInformation.loginUserFromKeytab("joan","/opt/hadoop/conf/joan.keytab") //基于kerberos的安全认证方式
sc.textFile("hdfs://nameservice1:8020/sparktest/words",2) //读取hdfs上的words文件
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey((a,b)=>a+b)
.collect().foreach(println)
}
}
生成docker镜像
1.代码编写完成后,通过maven工具对本项目进行编译和打包,得到该项目的jar包:WordCount1-1.0-SNAPSHOT.jar
2.然后编写Dockerfile并生成docker镜像:
Dockerfile文件内容如下:
FROM gcr.io/spark-operator/spark:v3.0.0
USER ${spark_uid}
RUN mkdir -p /opt/hadoop/conf
COPY core-site.xml /opt/hadoop/conf
COPY hdfs-site.xml /opt/hadoop/conf/
COPY krb5.conf /etc
COPY joan.keytab /opt/hadoop/conf/
ENV HADOOP_HOME /opt/hadoop
ENV HADOOP_CONF_DIR /opt/hadoop/conf
RUN mkdir -p /opt/spark/jars
COPY WordCount-1.0-SNAPSHOT.jar /opt/spark/jars
生成docker镜像:
docker build -t joanjiao2016/words:v1.0 .
docker push joanjiao2016/words:v1.0
将作业运行于K8S集群
打包好应用镜像之后,编写words.yaml文件,用于提交作业到K8S集群:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: words
namespace: default
spec:
type: Scala
mode: cluster
image: "joanjiao2016/words:v1.0"
imagePullPolicy: IfNotPresent
mainClass: WordCount
mainApplicationFile: "local:///opt/spark/jars/WordCount-1.0-SNAPSHOT.jar"
sparkVersion: "3.0.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.0.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.0.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
然后我们将在K8S集群中运行该示例程序:
提交作业
通过执行sparkctl create ${appname}.yaml 来提交作业:
[root@master ~]]# sparkctl create words.yaml
SparkApplication "words" created
查看Spark作业的运行状态
作业提交后,通过执行 sparkctl list 命令可以查看所有已提交的Spark 作业,并可以查看作业当前的运行状态:
[root@master ~]# sparkctl list
+----------+-----------+----------------+-----------------+
| NAME | STATE | SUBMISSION AGE | TERMINATION AGE |
+----------+-----------+----------------+-----------------+
| spark-pi | COMPLETED | 67d | 67d |
| words | RUNNING | 26s | N.A. |
+----------+-----------+----------------+-----------------+
查看应用日志
通过执行sparkctl log ${appname} 命令即可输出该作业的详细日志信息:
sparkctl log words
后续我们考虑通过filebeat将pod的日志信息收集到ELK日志平台,从而为用户提供更为方便的日志查询渠道。
查看Spark作业的事件
通过执行sparkctl event ${appname} 命令查看该Spark作业的event信息;
另外,在作业启动失败的情况下也可以通过该命令来分析失败原因:
[root@master ~]# sparkctl event words
+------------+--------+----------------------------------------------------+
| TYPE | AGE | MESSAGE |
+------------+--------+----------------------------------------------------+
| Normal | 1m | SparkApplication words was |
| | | added, enqueuing it for |
| | | submission |
| Normal | 55s | SparkApplication words was |
| | | submitted successfully |
| Normal | 52s | Driver words-driver is running |
| Normal | 42s | Executor |
| | | words-1602342178654-exec-1 is |
| | | pending |
| Normal | 39s | Executor |
| | | words-1602342178654-exec-1 is |
| | | running |
| Normal | 6s | Driver words-driver completed |
| Normal | 6s | SparkApplication words |
| | | completed |
+------------+--------+----------------------------------------------------+
查看作业运行界面
[root@master ~]# kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
words-ui-ingress words.joanjiao2016.com 80 13m
注意:没有DNS的同学可以在hosts中添加相应的域名映射即可访问。
至此我们了解了Spark on K8S的相关原理,并从0开始搭建环境并实践了一个的基于Spark Operator的应用。
目前Spark Operator这个项目还在不断地更新迭代,我们将持续关注该项目的进展,并继续在用户授权、资源隔离、日志接入和作业监控等方面进行进一步地测试和验证,逐渐探索出适合我行的Spark on K8S方案。
作者简介:
焦媛,2011年加入民生银行,目前主要负责Hadoop平台运维和相关工具研发,以及HDFS和Spark相关产品的技术支持工作。
以上是关于Spark Operator 初体验的主要内容,如果未能解决你的问题,请参考以下文章