spark项目实战(一~~九)
Posted 葱葱一抹绿随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark项目实战(一~~九)相关的知识,希望对你有一定的参考价值。


Spark项目之电商用户行为分析大数据平台之(一)项目介绍
目录
一、项目概述
二、业务模块介绍
2.1 用户访问session分析
2.2 页面单跳转化率统计
2.3 热门商品离线统计
2.4 广告流量实时统计
正文
一、项目概述
本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行复杂的分析。用统计分析出来的数据,辅助公司中的PM(产品经理)、数据分析师以及管理人员分析现有产品的情况,并根据用户行为分析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提升公司的业绩、营业额以及市场占有率的目标。
本项目使用了Spark技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL和Spark Streaming,进行离线计算和实时计算业务模块的开发。业务模块主要包括以下部分:
(1)用户访问session分析
(2)页面单跳转化率统计
(3)热门商品离线统计
(4)广告流量实时统计4个业务模块。
二、业务模块介绍
2.1 用户访问session分析
该模块主要是对用户访问session进行统计分析,包括session的聚合指标计算、按时间比例随机抽取session、获取每天点击、下单和购买排名前10的品类、并获取top10品类的点击量排名前10的session。该模块可以让产品经理、数据分析师以及企业管理层形象地看到各种条件下的具体用户行为以及统计指标,从而对公司的产品设计以及业务发展战略做出调整。主要使用Spark Core实现。
2.2 页面单跳转化率统计
该模块主要是计算关键页面之间的单步跳转转化率,涉及到页面切片算法以及页面流匹配算法。该模块可以让产品经理、数据分析师以及企业管理层看到各个关键页面之间的转化率,从而对网页布局,进行更好的优化设计。主要使用Spark Core实现。
2.3 热门商品离线统计
该模块主要实现每天统计出各个区域的top3热门商品。然后使用Oozie进行离线统计任务的定时调度;使用Zeppeline进行数据可视化的报表展示。该模块可以让企业管理层看到公司售卖的商品的整体情况,从而对公司的商品相关的战略进行调整。主要使用Spark SQL实现。
2.4 广告流量实时统计
该模块负责实时统计公司的广告流量,包括广告展现流量和广告点击流量。实现动态黑名单机制,以及黑名单过滤;实现滑动窗口内的各城市的广告展现流量和广告点击流量的统计;实现每个区域每个广告的点击流量实时统计;实现每个区域top3点击量的广告的统计。主要使用Spark Streaming实现。
Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
目录
一、CentOS7集群搭建
1.1 准备3台centos7的虚拟机
1.3 修改主机映射
1.4 修改主机名
1.5 关闭防火墙
1.6 修改repo
1.7 配置免密登录
二、软件的安装
2.1 JDK的安装
正文
一、CentOS7集群搭建
1.1 准备3台centos7的虚拟机
IP及主机名规划如下:
192.168.123.110 spark1
192.168.123.111 spark2
192.168.123.112 spark3
1.2 修改IP地址
[root@bigdata ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
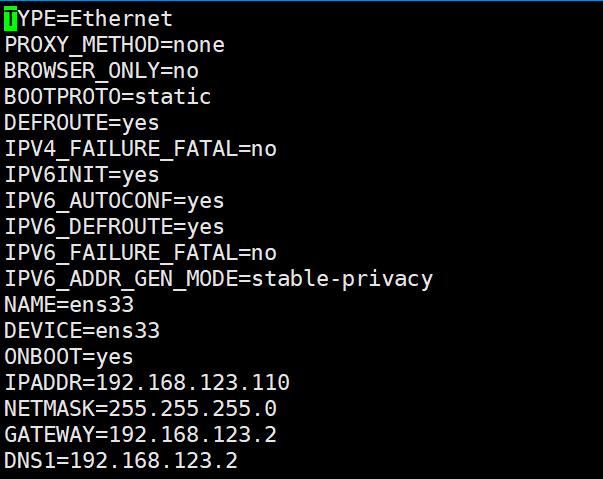
1.3 修改主机映射
[root@bigdata ~]# vi /etc/hosts

1.4 修改主机名
三台机器分别把主机名修改为spark1、spark2、spark3
[root@bigdata ~]# vi /etc/hostname

1.5 关闭防火墙
//临时关闭systemctl stop firewalld//禁止开机启动systemctl disable firewalld

1.6 修改repo
[root@bigdata ~]# cd /etc/yum.repos.d/[root@bigdata yum.repos.d]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo

如果还有其他源,可以暂且把他们重命名成其他扩展名,比如 CentOS-Base.repo.bak
[root@bigdata yum.repos.d]# mv CentOS-Base.repo CentOS-Base.repo.bak
[root@bigdata yum.repos.d]# mv CentOS7-Base-163.repo CentOS7-Base.repo [root@bigdata yum.repos.d]# yum clean all[root@bigdata yum.repos.d]# yum makecache
安装 epel 源
[root@bigdata yum.repos.d]# yum install epel-release[root@bigdata yum.repos.d]# yum makecache
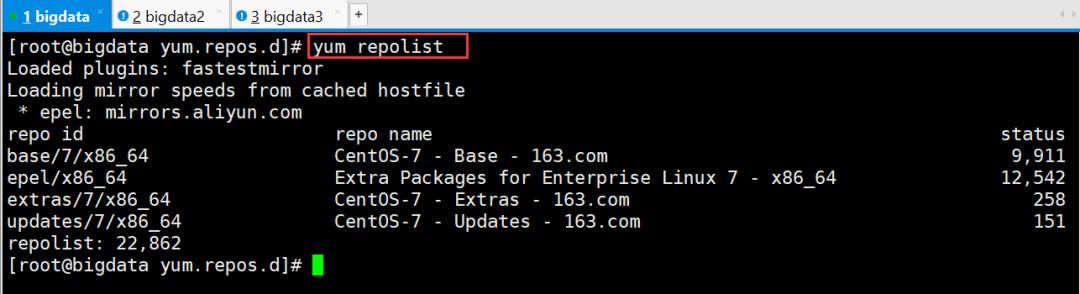
检查是否安装成功
[root@bigdata yum.repos.d]# yum repolist
1.7 配置免密登录
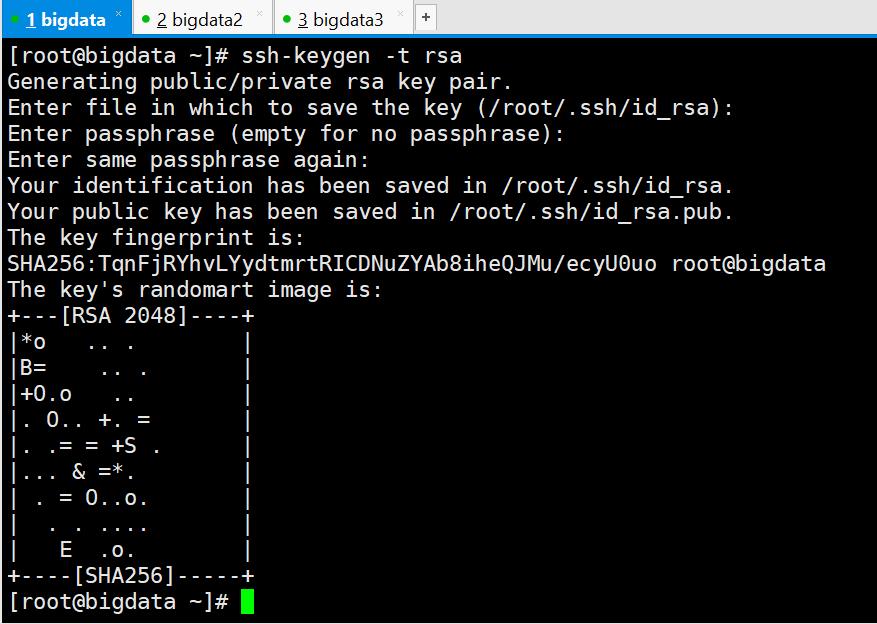
[root@bigdata ~]# ssh-keygen -t rsa
三次回车
将spark1上的公钥复制到文件authorized_keys中
[root@spark1 ~]# cd .ssh[root@spark1 .ssh]# cat id_rsa.pub > authorized_keys
将spark2、和spark3机器上的公钥发送到spark1上
[root@spark2 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark2.pub[root@spark3 .ssh]# scp -r id_rsa.pub root@192.168.123.110:~/spark3.pub
在spark1上将spark2、和spark3的公钥追加到authorized_keys中
[root@bigdata ~]# cat spark2.pub > .ssh/authorized_keys [root@bigdata ~]# cat spark3.pub > .ssh/authorized_keys
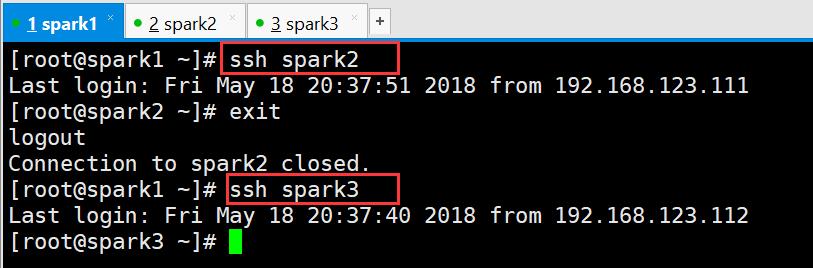
在spark1上验证ssh免密登录是否设置成功
二、软件的安装
2.1 JDK的安装
上传并解压
[root@spark1 ~]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C apps/
修改环境变量
[root@spark1 apps]# vi /etc/profile
#JAVA export JAVA_HOME=/root/apps/jdk1.8.0_73 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
保存并使其生效
[root@spark1 apps]# source /etc/profile
检查

Spark项目之电商用户行为分析大数据平台之(三)大数据集群的搭建
讨论QQ:1586558083
Zookeeper集群搭建
http://www.cnblogs.com/qingyunzong/p/8619184.html
Hadoop集群搭建
http://www.cnblogs.com/qingyunzong/p/8634335.html
http://www.cnblogs.com/qingyunzong/p/8639918.html
Hbase集群搭建
http://www.cnblogs.com/qingyunzong/p/8668880.html
Hive的搭建
http://www.cnblogs.com/qingyunzong/p/8708057.html
Kafka的搭建
http://www.cnblogs.com/qingyunzong/p/9005062.html
Flume的搭建
http://www.cnblogs.com/qingyunzong/p/8994494.html
Spark的搭建
http://www.cnblogs.com/qingyunzong/p/8888080.html
Spark项目之电商用户行为分析大数据平台之(四)离线数据采集

Spark项目之电商用户行为分析大数据平台之(五)实时数据采集
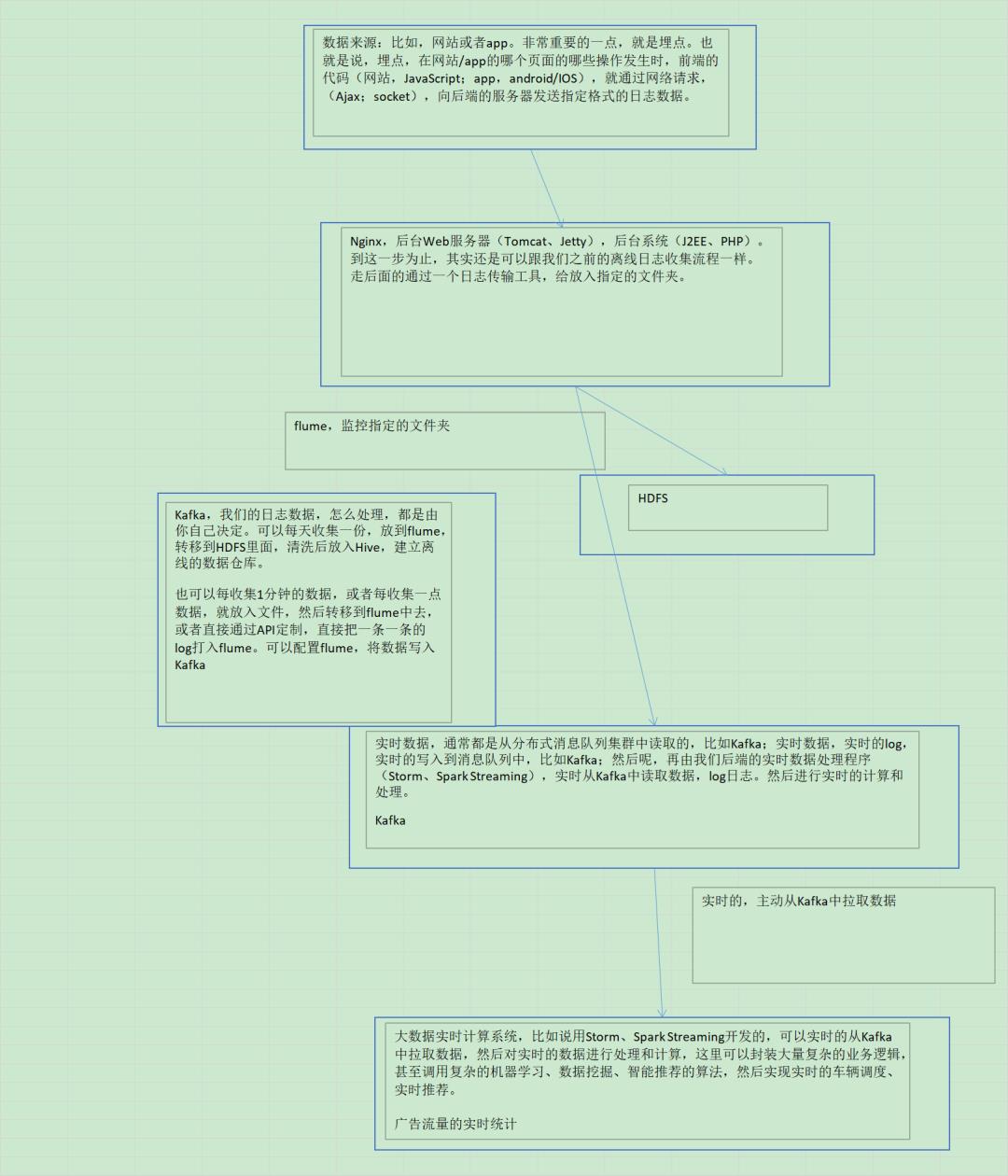
Spark项目之电商用户行为分析大数据平台之(六)用户访问session分析模块介绍
目录
一、对用户访问session进行分析
二、在实际企业项目中的使用架构
三、用户访问session的介绍
正文
一、对用户访问session进行分析
1、可以根据使用者指定的某些条件,筛选出指定的一些用户(有特定年龄、职业、城市);
2、对这些用户在指定日期范围内发起的session,进行聚合统计,比如,统计出访问时长在0~3s的session占总session数量的比例;
3、按时间比例,比如一天有24个小时,其中12:00~13:00的session数量占当天总session数量的50%,当天总session数量是10000个,那么当天总共要抽取1000个session,ok,12:00~13:00的用户,就得抽取1000*50%=500。而且这500个需要随机抽取。
4、获取点击量、下单量和支付量都排名10的商品种类
5、获取top10的商品种类的点击数量排名前10的session
6、开发完毕了以上功能之后,需要进行大量、复杂、高端、全套的性能调优(大部分性能调优点,都是本人在实际开发过程中积累的经验,基本都是全网唯一)
7、十亿级数据量的troubleshooting(故障解决)的经验总结
8、数据倾斜的完美解决方案(全网唯一,非常高端,因为数据倾斜往往是大数据处理程序的性能杀手,很多人在遇到的时候,往往没有思路)
9、使用mock(模拟)的数据,对模块进行调试、运行和演示效果
二、在实际企业项目中的使用架构
1、J2EE的平台(美观的前端页面),通过这个J2EE平台可以让使用者,提交各种各样的分析任务,其中就包括一个模块,就是用户访问session分析模块;可以指定各种各样的筛选条件,比如年龄范围、职业、城市等等。。
2、J2EE平台接收到了执行统计分析任务的请求之后,会调用底层的封装了spark-submit的shell脚本(Runtime、Process),shell脚本进而提交我们编写的Spark作业。
3、Spark作业获取使用者指定的筛选参数,然后运行复杂的作业逻辑,进行该模块的统计和分析。
4、Spark作业统计和分析的结果,会写入mysql中,指定的表
5、最后,J2EE平台,使用者可以通过前端页面(美观),以表格、图表的形式展示和查看MySQL中存储的该统计分析任务的结果数据。
三、用户访问session的介绍
用户在电商网站上,通常会有很多的点击行为,首页通常都是进入首页;然后可能点击首页上的一些商品;点击首页上的一些品类;也可能随时在搜索框里面搜索关键词;还可能将一些商品加入购物车;对购物车中的多个商品下订单;最后对订单中的多个商品进行支付。
用户的每一次操作,其实可以理解为一个action,比如点击、搜索、下单、支付
用户session,指的就是,从用户第一次进入首页,session就开始了。然后在一定时间范围内,直到最后操作完(可能做了几十次、甚至上百次操作)。离开网站,关闭浏览器,或者长时间没有做操作;那么session就结束了。
以上用户在网站内的访问过程,就称之为一次session。简单理解,session就是某一天某一个时间段内,某个用户对网站从打开/进入,到做了大量操作,到最后关闭浏览器。的过程。就叫做session。
session实际上就是一个电商网站中最基本的数据和大数据。那么大数据,面向C端,也就是customer,消费者,用户端的,分析,基本是最基本的就是面向用户访问行为/用户访问session。
Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍
目录
一、user_visit_action(Hive表)
1.1 表的结构
1.2 表的说明
二、user_info(Hive表)
2.1 表的结构
2.2 表的说明
三、task(MySQL表)
3.1 表的结构
3.2 表的说明
四、工作流程
正文
一、user_visit_action(Hive表)
1.1 表的结构
date:日期,代表这个用户点击行为是在哪一天发生的
user_id:代表这个点击行为是哪一个用户执行的
session_id :唯一标识了某个用户的一个访问session
page_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的id
action_time :这个点击行为发生的时间点
search_keyword :如果用户执行的是一个搜索行为,比如说在网站/app中,搜索了某个关键词,然后会跳转到商品列表页面;搜索的关键词
click_category_id :可能是在网站首页,点击了某个品类(美食、电子设备、电脑)
click_product_id :可能是在网站首页,或者是在商品列表页,点击了某个商品(比如呷哺呷哺火锅XX路店3人套餐、iphone 6s)
order_category_ids :代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些
商品品类,可能有6个商品,但是就对应了2个品类,比如有3根火腿肠(食品品类),3个电池(日用品品类)
order_product_ids :某次下单,具体对哪些商品下的订单
pay_category_ids :代表的是,对某个订单,或者某几个订单,进行了一次支付的行为,对应了哪些品类
pay_product_ids:代表的,支付行为下,对应的哪些具体的商品
1.2 表的说明
user_visit_action表,其实就是放,比如说网站,或者是app,每天的点击流的数据。可以理解为,用户对网站/app每点击一下,就会代表在这个表里面的一条数据。
二、user_info(Hive表)
2.1 表的结构
user_id:其实就是每一个用户的唯一标识,通常是自增长的Long类型,BigInt类型
username:是每个用户的登录名
name:每个用户自己的昵称、或者是真实姓名
age:用户的年龄
professional:用户的职业
city:用户所在的城市
2.2 表的说明
user_info表,实际上,就是一张最普通的用户基础信息表;这张表里面,其实就是放置了网站/app所有的注册用户的信息。那么我们这里也是对用户信息表,进行了一定程度的简化。比如略去了手机号等这种数据。因为我们这个项目里不需要使用到某些数据。那么我们就保留一些最重要的数据,即可。
三、task(MySQL表)
3.1 表的结构
task_id:表的主键
task_name:任务名称
create_time:创建时间
start_time:开始运行的时间
finish_time:结束运行的时间
task_type:任务类型,就是说,在一套大数据平台中,肯定会有各种不同类型的统计分析任务,比如说用户访问session分析任务,页面单跳转化率统计任务;所以这个字段就标识了每个任务的类型
task_status:任务状态,任务对应的就是一次Spark作业的运行,这里就标识了,Spark作业是新建,还没运行,还是正在运行,还是已经运行完毕
task_param:最最重要,用来使用JSON的格式,来封装用户提交的任务对应的特殊的筛选参数
3.2 表的说明
task表,其实是用来保存平台的使用者,通过J2EE系统,提交的基于特定筛选参数的分析任务,的信息,就会通过J2EE系统保存到task表中来。之所以使用MySQL表,是因为J2EE系统是要实现快速的实时插入和查询的。
四、工作流程
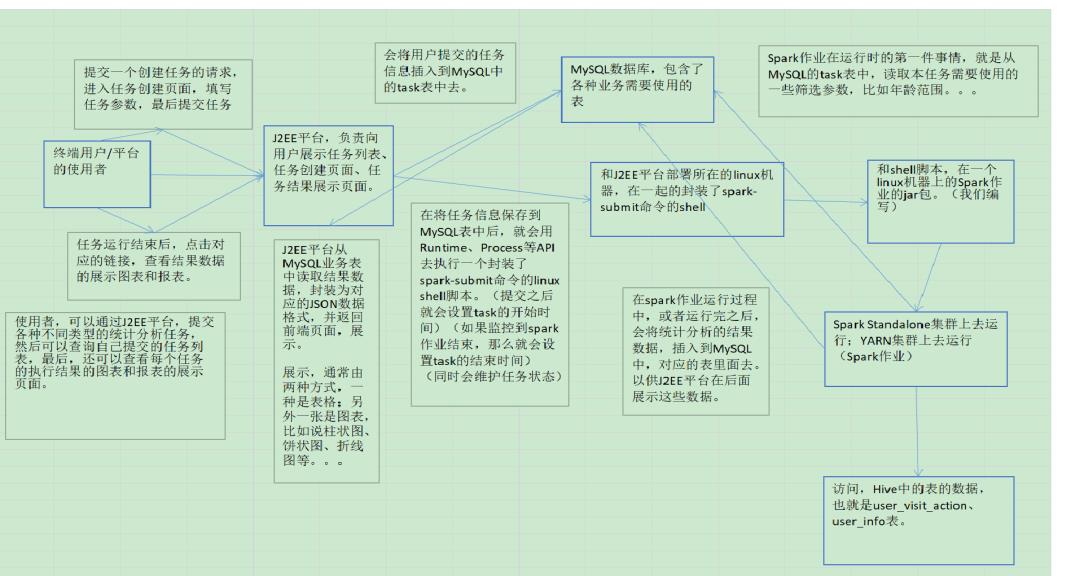
Spark项目之电商用户行为分析大数据平台之(八)需求分析
1、按条件筛选session
搜索过某些关键词的用户、访问时间在某个时间段内的用户、年龄在某个范围内的用户、职业在某个范围内的用户、所在某个城市的用户,发起的session。找到对应的这些用户的session,也就是我们所说的第一步,按条件筛选session。
这个功能,就最大的作用就是灵活。也就是说,可以让使用者,对感兴趣的和关系的用户群体,进行后续各种复杂业务逻辑的统计和分析,那么拿到的结果数据,就是只是针对特殊用户群体的分析结果;而不是对所有用户进行分析的泛泛的分析结果。比如说,现在某个企业高层,就是想看到用户群体中,28~35岁的,老师职业的群体,对应的一些统计和分析的结果数据,从而辅助高管进行公司战略上的决策制定。
2、统计出符合条件的session中,访问时长在1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m以上各个范围内的session占比;访问步长在1~3、4~6、7~9、10~30、30~60、60以上各个范围内的session占比
session访问时长,也就是说一个session对应的开始的action,到结束的action,之间的时间范围;还有,就是访问步长,指的是,一个session执行期间内,依次点击过多少个页面,比如说,一次session,维持了1分钟,那么访问时长就是1m,然后在这1分钟内,点击了10个页面,那么session的访问步长,就是10.
比如说,符合第一步筛选出来的session的数量大概是有1000万个。那么里面,我们要计算出,访问时长在1s~3s内的session的数量,并除以符合条件的总session数量(比如1000万),比如是100万/1000万,那么1s~3s内的session占比就是10%。依次类推,这里说的统计,就是这个意思。
这个功能的作用,其实就是,可以让人从全局的角度看到,符合某些条件的用户群体,使用我们的产品的一些习惯。比如大多数人,到底是会在产品中停留多长时间,大多数人,会在一次使用产品的过程中,访问多少个页面。那么对于使用者来说,有一个全局和清晰的认识。
3、在符合条件的session中,按照时间比例随机抽取1000个session
这个按照时间比例是什么意思呢?随机抽取本身是很简单的,但是按照时间比例,就很复杂了。比如说,这一天总共有1000万的session。那么我现在总共要从这1000万session中,随机抽取出来1000个session。但是这个随机不是那么简单的。需要做到如下几点要求:首先,如果这一天的12:00~13:00的session数量是100万,那么这个小时的session占比就是1/10,那么这个小时中的100万的session,我们就要抽取1/10 * 1000 = 100个。然后再从这个小时的100万session中,随机抽取出100个session。以此类推,其他小时的抽取也是这样做。
这个功能的作用,是说,可以让使用者,能够对于符合条件的session,按照时间比例均匀的随机采样出1000个session,然后观察每个session具体的点击流/行为,比如先进入了首页、然后点击了食品品类、然后点击了雨润火腿肠商品、然后搜索了火腿肠罐头的关键词、接着对王中王火腿肠下了订单、最后对订单做了支付。
之所以要做到按时间比例随机采用抽取,就是要做到,观察样本的公平性。
4、在符合条件的session中,获取点击、下单和支付数量排名前10的品类
什么意思呢,对于这些session,每个session可能都会对一些品类的商品进行点击、下单和支付等等行为。那么现在就需要获取这些session点击、下单和支付数量排名前10的最热门的品类。也就是说,要计算出所有这些session对各个品类的点击、下单和支付的次数,然后按照这三个属性进行排序,获取前10个品类。
这个功能,很重要,就可以让我们明白,就是符合条件的用户,他最感兴趣的商品是什么种类。这个可以让公司里的人,清晰地了解到不同层次、不同类型的用户的心理和喜好。
5、对于排名前10的品类,分别获取其点击次数排名前10的session
这个就是说,对于top10的品类,每一个都要获取对它点击次数排名前10的session。
这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的session的行为。
Spark项目之电商用户行为分析大数据平台之(九)表的设计
目录
一、概述
二、MySQL表设计
2.1 session_aggr_stat表
2.2 session_random_extract表
2.3 top10_category表
2.4 top10_category_session表
2.5 session_detail
2.6 task表
正文
一、概述
数据设计,往往包含两个环节:
第一个:就是我们的上游数据,就是数据调研环节看到的项目基于的基础数据,是否要针对其开发一些Hive ETL,对数据进行进一步的处理和转换,从而让我们能够更加方便的和快速的去计算和执行spark作业;
第二个:就是要设计spark作业要保存结果数据的业务表的结构,从而让J2EE平台可以使用业务表中的数据,来为使用者展示任务执行结果。
二、MySQL表设计
2.1 session_aggr_stat表
存储第一个功能,session聚合统计的结果

CREATE TABLE `session_aggr_stat` ( `task_id` int(11) NOT NULL, `session_count` int(11) DEFAULT NULL, `1s_3s` double DEFAULT NULL, `4s_6s` double DEFAULT NULL, `7s_9s` double DEFAULT NULL, `10s_30s` double DEFAULT NULL, `30s_60s` double DEFAULT NULL, `1m_3m` double DEFAULT NULL, `3m_10m` double DEFAULT NULL, `10m_30m` double DEFAULT NULL, `30m` double DEFAULT NULL, `1_3` double DEFAULT NULL, `4_6` double DEFAULT NULL, `7_9` double DEFAULT NULL, `10_30` double DEFAULT NULL, `30_60` double DEFAULT NULL, `60` double DEFAULT NULL, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.2 session_random_extract表
存储我们的按时间比例随机抽取功能抽取出来的1000个session
CREATE TABLE `session_random_extract` ( `task_id` int(11) NOT NULL, `session_id` varchar(255) DEFAULT NULL, `start_time` varchar(50) DEFAULT NULL, `end_time` varchar(50) DEFAULT NULL, `search_keywords` varchar(255) DEFAULT NULL, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.3 top10_category表
存储按点击、下单和支付排序出来的top10品类数据
CREATE TABLE `top10_category` ( `task_id` int(11) NOT NULL, `category_id` int(11) DEFAULT NULL, `click_count` int(11) DEFAULT NULL, `order_count` int(11) DEFAULT NULL, `pay_count` int(11) DEFAULT NULL, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.4 top10_category_session表
存储top10每个品类的点击top10的session
CREATE TABLE `top10_category_session` ( `task_id` int(11) NO NULL, `category_id` int(11) DEFAULT NULL, `session_id` varchar(255) DEFAULT NULL, `click_count` int(11) DEFAULT NULL, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.5 session_detail
用来存储随机抽取出来的session的明细数据、top10品类的session的明细数据
CREATE TABLE `session_detail` ( `task_id` int(11) NOT NULL, `user_id` int(11) DEFAULT NULL, `session_id` varchar(255) DEFAULT NULL, `page_id` int(11) DEFAULT NULL, `action_time` varchar(255) DEFAULT NULL, `search_keyword` varchar(255) DEFAULT NULL, `click_category_id` int(11) DEFAULT NULL, `click_product_id` int(11) DEFAULT NULL, `order_category_ids` varchar(255) DEFAULT NULL, `order_product_ids` varchar(255) DEFAULT NULL, `pay_category_ids` varchar(255) DEFAULT NULL, `pay_product_ids` varchar(255) DEFAULT NULL, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
2.6 task表
用来存储J2EE平台插入其中的任务的信息
CREATE TABLE `task` ( `task_id` int(11) NOT NULL AUTO_INCREMENT, `task_name` varchar(255) DEFAULT NULL, `create_time` varchar(255) DEFAULT NULL, `start_time` varchar(255) DEFAULT NULL, `finish_time` varchar(255) DEFAULT NULL, `task_type` varchar(255) DEFAULT NULL, `task_status` varchar(255) DEFAULT NULL, `task_param` text, PRIMARY KEY (`task_id`) ) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
以上是关于spark项目实战(一~~九)的主要内容,如果未能解决你的问题,请参考以下文章
云计算大数据(Hadoop)开发工程师项目实战视频教程(九部分)
git项目初次push提示error: failed to push some refs to https://gitee.com/xxxx/gittest.git’解决方案 --九五小庞(代码片段
Spark Streaming实时流处理项目实战Spark Streaming整合Kafka实战一
Spark Streaming实时流处理项目实战Spark Streaming整合Kafka实战一