Spark Streaming实时流处理项目实战Spark Streaming整合Kafka实战一
Posted 怒上王者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming实时流处理项目实战Spark Streaming整合Kafka实战一相关的知识,希望对你有一定的参考价值。
Spark Streaming整合Kafka实战
Spark Streaming对kafka的支持
spark streaming
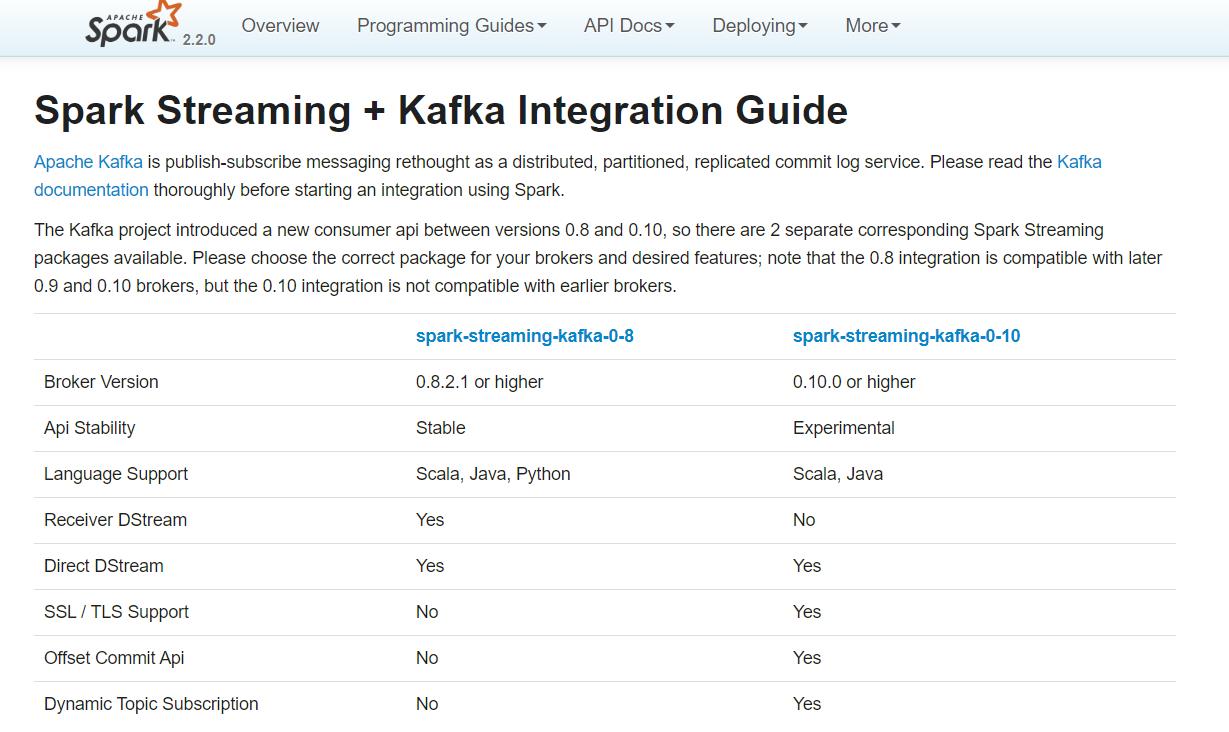
官网链接:https://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
Spark Streaming整合kafka的两种方式
- 0.8版本整合 :receiver方式 direct方式
- 0.10版本整合:direct方式。(0.10版本不再支持receiver方式)
receiver方式:基于线程拉取数据
Spark的程序,启动线程去kafka里面拉取数据回来,拉取回来的数据存放spark的executor里面了,等着被其他的线程处理。
拉取数据的线程与处理数据的线程,不是同一个线程;拉取数据是A线程,处理数据B线程。
存在问题:拉取线程有可能一直在工作,但是处理数据线程有可能停止了 就会造成数据积压的情况
优点:使用kafka的high_level的API进行消费,kafka的offset都存储再zk里面,不用我们自己管了
这种方式基本已经废弃了,生产中一般使用第二种方式
direct方式:直接连接模式
拉取数据的线程以及处理数据的线程,都是同一个线程,数据拉取与数据处理都是统一批线程,不会存在线程停掉的问题
缺点:需要我们自己去维护offset 默认保存在kafka的一个topi里面了
1.Receiver-based Approach
- 直接用receiver接收数据。Receiver是使用Kafka高级消费者API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark执行器中,然后由Spark Streaming启动的作业处理数据。但是在默认配置下,此方法可能会在失败时丢失数据。
- 为确保零数据丢失,必须在Spark Streaming中另外启用Write Ahead Logs(在Spark
1.2中引入)。这将同步保存所有收到的Kafka将数据写入分布式文件系统(例如HDFS)上的预写日志,以便在发生故障时可以恢复所有数据,但是性能不好。
kafka对接streaming实战
在kafka中创建topic
[root@hadoop01 kafka_2.11-0.9.0.0]# bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic kafka_streaming_topic
pom.xml中添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.3.3</version>
</dependency>
核心代码
mport org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
完整代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* Created by llp on 2021/5/10.
*/
object KafkaReceiverWordCount
def main(args: Array[String]): Unit =
if(args.length !=4)
System.err.println("Usage: <zkQuorum> <group> <topics> <numThreads>")
val Array(zkQuorum, group, topics,numThreads) = args
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("KafkaReceiverWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap
//TODO...Spark Streaming 对接kafka
val kafkaStream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
kafkaStream.print()
kafkaStream.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
执行测试
idea配置好参数
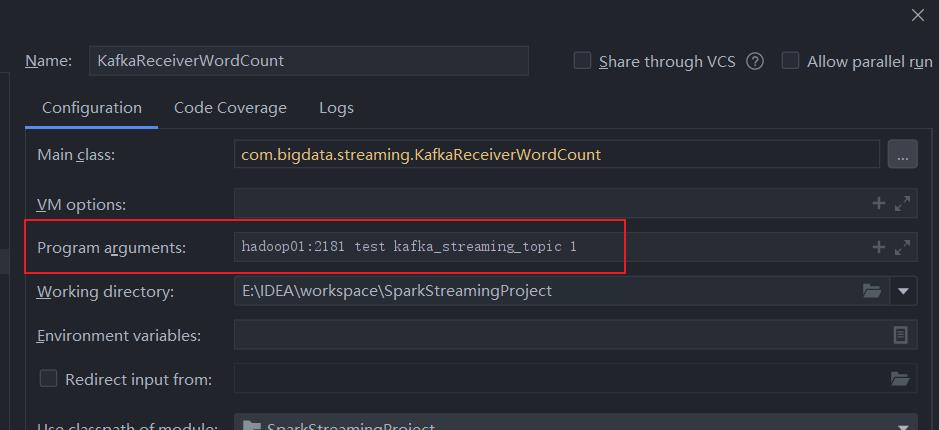
统计结果


kafkaStream.map(x=>x).print() 的打印结果,所以在取值时要取map中的第二个。

生产方式
打包
mvn clean package -DskipTests
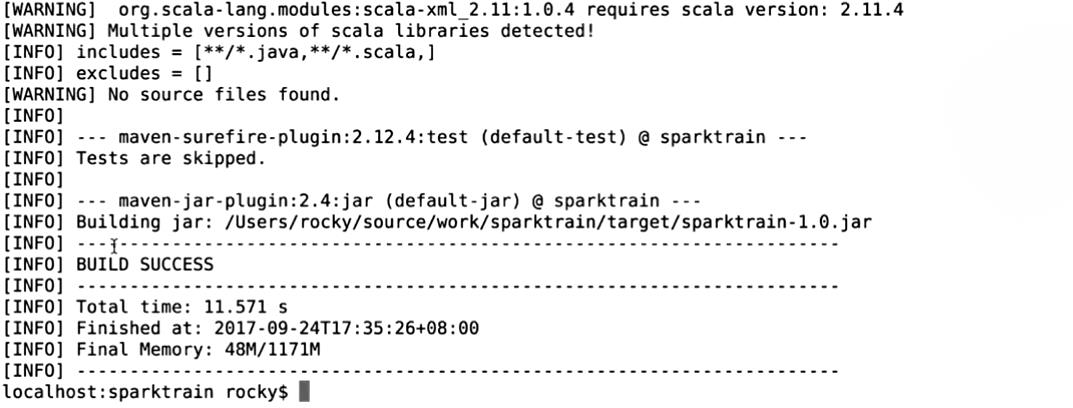
使用spark-submit提交

以上是关于Spark Streaming实时流处理项目实战Spark Streaming整合Kafka实战一的主要内容,如果未能解决你的问题,请参考以下文章