技术猩球范文臣:基于 Spark 的高性能查询引擎
Posted 七牛云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术猩球范文臣:基于 Spark 的高性能查询引擎相关的知识,希望对你有一定的参考价值。
11 月 24 日,「七牛云 Niu Talk」 数据科学系列论坛第三期如期举行。论坛上,Databricks 开源技术负责人范文臣为我们带来主题为《基于 Spark 的高性能查询引擎》的精彩分享。本文根据现场分享整理,并贴心送上完整现场视频回顾。
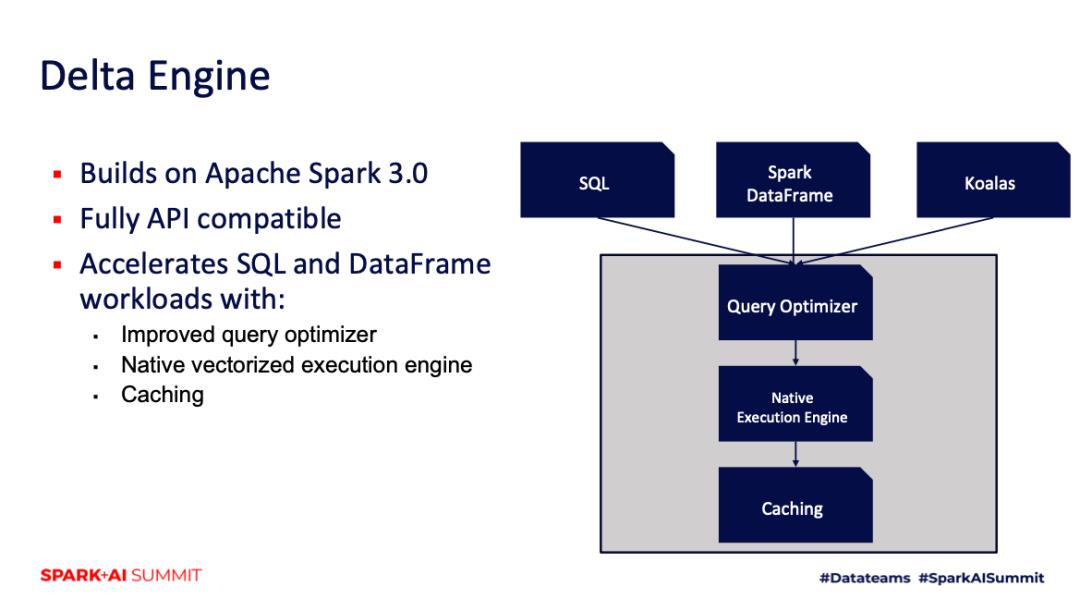
今天分享的主要内容是 Delta Engine,Databricks 研发的一款基于 Spark 的高性能查询引擎,Delta Engine 基于 Spark 3.0 打造,与 Spark 完全 API 兼容。
Delta Engine 是从如下三个方面来优化 SQL 的性能:
第一, Databricks 提升了 Query 的优化器;
第二, Databricks 从头打造了一个本地化、向量化的执行引擎;
第三,Databricks 做了一些 IO 方面的缓存。
Databricks 优化过的 Query 优化器
首先以本身自有的基于代价的优化器,和基于运行时的自适应优化器扩展 Spark,并且加上了一些更加高级的数据和信息来提升性能。在实践中发现,改进过后的优化器最高可以达到 18 倍的性能提升。
缓存层非常智能,它可以自动地缓存输入数据,并且在缓存中不是直接把数据缓存起来,而是先把它转换成对 CPU 更加友好的格式,然后缓存到本地的 NVMe SSD 中来优化 IO 性能。我们发现,这样可以获得 5 倍的性能提升。
设计这款引擎有两个出发点,一个是当前形势下硬件的趋势,这决定了我们设计引擎的硬件基础,另一个是目前的公司业务的发展趋势,这个决定了我们的优化方向,要保证这个引擎有的放矢。
现在是 2020 年,我们来看一下硬件趋势,这时我们发现,储存层有了 NVMe 接口的 SSD,做到了十倍以上的提升;关于网络层,现在一些高速网络也要比五年前有十倍提升;然而 CPU 主频还在 3GHz 左右,我们发现 CPU 持续成为我们性能提升的瓶颈,我们需要找到提升性能的方法。
现在,很多公司会强调敏捷开发,他们的业务变化非常快,后果就是公司组织者没有时间去优化数据模型,或增加一些数据的清洗条件。而且用户非常喜欢用 string,因为 string 非常方便,甚至有些人把日期列都存为string。
另外,随着数据湖越发流行,用户越来越多地想要去处理半结构化数据,并且数据会持续不断地到来。相比以前,数据模型比较松散,这就导致性能优化没有以前好。
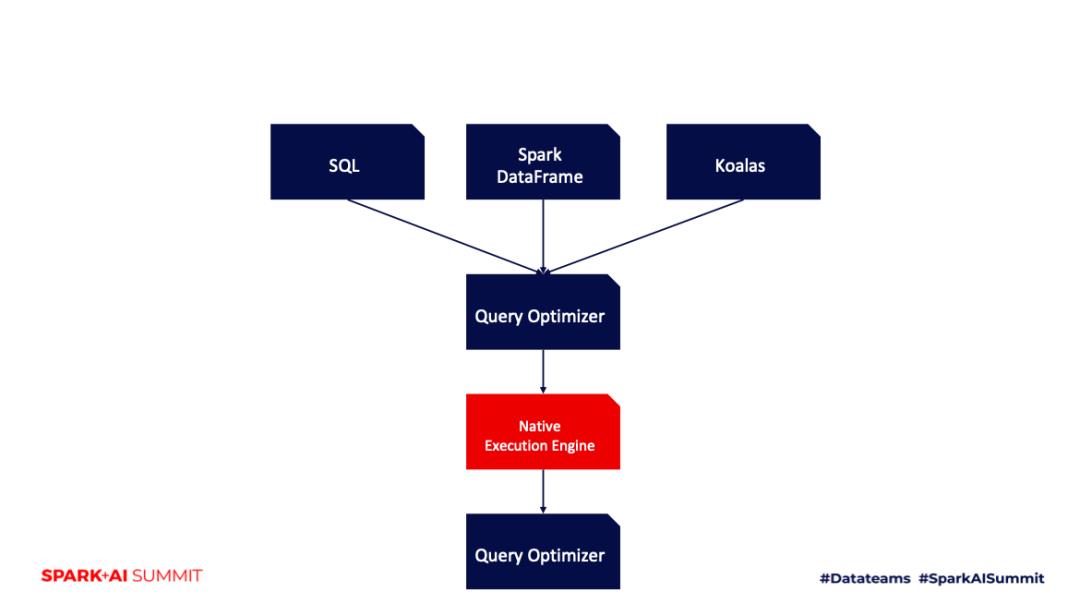
如何同时达到的敏捷性和查询性能的提升?Databricks 给出的答案是 Photon,它是我们从零打造的一款执行引擎,可以加速 Spark SQL 的 Query。Photon 是用 C++ 从头开始实现的,它主要从两个方向提升性能,一个是利用CPU的向量化技术;一个是针对目前用户的 workload 做了优化,加速半结构化数据查询。
第一,Photon 利用CPU数据并行的技术原理来提升 query 性能。这里涉及到列式存储的数据结构,线性地访问内存数据,对 CPU 缓存更友好;
第二,Photon 利用 CPU 指令并行的技术原理,改造对于一些关键数据结构的访问模式,以提升性能;
最终,Photo Engine 跟原来基于 JVM 的 codegen Engine 相比,在 TPC-DS 有 3.3 倍的性能提升。
「七牛云 Niu Talk 」数据科学系列论坛干货回顾
以上是关于技术猩球范文臣:基于 Spark 的高性能查询引擎的主要内容,如果未能解决你的问题,请参考以下文章
分享 | Spark Skew Join的原理与优化
Spark SQL(十):Hive On Spark
两款高性能并行计算引擎Storm和Spark比較
Apache Spark在海致大数据平台中的优化实践
OpenMLDB: 拓展Spark源码实现高性能Join
1.spark简介