分享 | Spark Skew Join的原理与优化
Posted eBay技术荟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享 | Spark Skew Join的原理与优化相关的知识,希望对你有一定的参考价值。
作者 | 王刚
导读
Carmel是eBay内
部基于Apache Spark打造的一款SQL-on-Hadoop查询引擎。我们通过对Apache Spark的改进,为用户提供了一套高可用高性能的服务,用以满足eBay内部大量的分析型查询需求,如今单日查询量已接近
25万
。
在生产中,我们发现制约查询执行性能的一个重要因素是data skew(数据倾斜),Spark在3.0的版本中引入了skew join,用来解决在join过程中出现的data skew问题。但由于其所能覆盖的场景有限,我们对其做了一系列的扩展和改进,从而解决更多我们线上遇到的data skew问题。本文就Spark skew join进行介绍,包括skew join的原理与实现,并重点介绍我们在skew join之上所做的优化。
在一个分布式查询引擎中,对于aggregation(为了方便介绍,本文提到的aggregation都特指group by之后做的聚合)、 join等一些操作,引擎通常需要保证在执行的过程中具有相同key的数据汇集到同一个处理单元内进行处理。在Spark中,这一过程通常是通过shuffle(包括shuffle write和shuffle read)来完成的, shuffle对应的physical operator是ShuffleExchangeExec。那么Spark是如何决定应该为哪些operator加上ShuffleExchangeExec的呢?
requiredChildDistribution
每个physical operator都实现了requiredChildDistribution方法,以获得一个Distribution的实例,用于表示
operator对其input数据分布情况的要求。
举例来说,对于HashAggregateExec( aggregation对应的physical operator,也可能是SortAggregateExec,这里我们拿HashAggregateExec举例),其执行的前提是“所有具有相同aggregation key的record放到同一个处理单元中”(为了方便介绍,本文我们暂不考虑partital aggregation)。在Spark中,这样的处理单元就是RDD的一个partition,因此也就是要满足“所有group by 的column具有相同value的record被分配到RDD的同一个partition中”。而这样的数据分布规律有一个专门的类来表示ClusteredDistribution。
ClusteredDistribution表示的数据分布情况是“在一个RDD中,所有具有相同key的record被分配在同一个partition内”。
HashAggregateExec的requiredChildDistribution就是ClusteredDistribution。
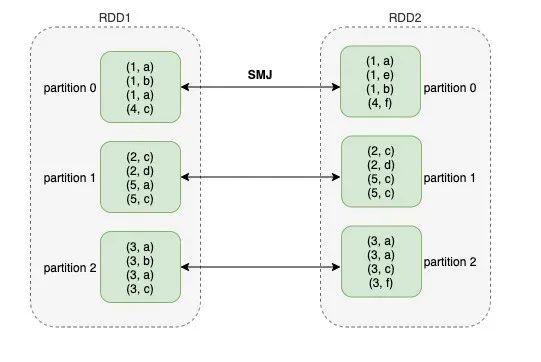
再看join,拿sort merge join举例,其对应的physical operator是SortMergeJoinExec。在Spark的实现里,SortMergeJoinExec的实现简单来说就是把join两边的RDD中具有相同id的partition zip到一起进行关联。前文提到,ClusteredDistribution保证的是具有相同key的record能聚集到同一个partition中,但对join来说这样还不够。如图1所示,在RDD1中假设join key为1的record分配到了partition 0,那么如果RDD1和RDD2要进行join,则RDD2中所有join key为1的record也必须分配到partition 0中。Spark通过在左右两边的shuffle中使用相同的hash函数和shuffle partition number来保证这一点。因此,SortMergeJoinExec对join两边的requiredChildDistribution就不是ClusteredDistribution,而是HashClusteredDistribution。
HashClusteredDistribution不仅保证具有相同key的record被分配到同一个partition内,而且保证了对每一个key分配到的partition id也都是确定的。
同时,每个physical operatior还实现了outputPartitioning接口,以获得一个Partitioning的实例,用于表示
operator输出数据满足的分布情况。
举例来说,对于ShuffleExchangeExec,其主要的目的是按照input数据的shuffle key的hash值进行分桶,经过ShuffleExchangeExec后,具有相同hash值的record会聚集到具有相同id的桶里,也就是同一个shuffle partition中。Spark把这样的分布情况叫做HashPartitioning。因此ShuffleExchangeExec的outputPartitioning就是HashPartitioning。而像HashAggregateExec这样的operator,由于其本身并不会改变input数据的分布情况,其outputPartitioning就是其input operator的outputPartitioning。
决定应该为哪些operator加上ShuffleExchangeExec的逻辑都是在rule EnsureRequirements里完成的。一个physical plan在Spark中用一个tree来表示,每一个physical operator都对应tree上的一个节点。EnsureRequirements的执行过程要遍历整个 tree,当遍历到一个节点时,去检查其子节点的 outputPartitioning是否满足该节点的requiredChildDistribution。如果不满足,则在两个节点之间加上一个ShuffleExchangeExec。整个遍历过程从叶子节点开始,一直到根节点结束。这样当遍历结束后,就能确保每个节点的子节点的outputPartitioning都满足该operator的requiredChildDistribution。
Data skew本身是一个很泛化的概念,指的是数据分布不均匀,从而导致大量数据聚集到少数的单元内。Spark中这样的单元是RDD的一个partition,而每一个partition对应一个task。因此data skew也意味着某一些task要处理的数据量远大于其它task处理的数据量,这些task可能会拖累整个SQL的执行速度,尤其是对join来说。
从3.0开始,Spark引入了adaptive query execution(AQE),使得Spark能够通过stage执行结果动态地调整plan,而skew join就是AQE的一项重要应用。
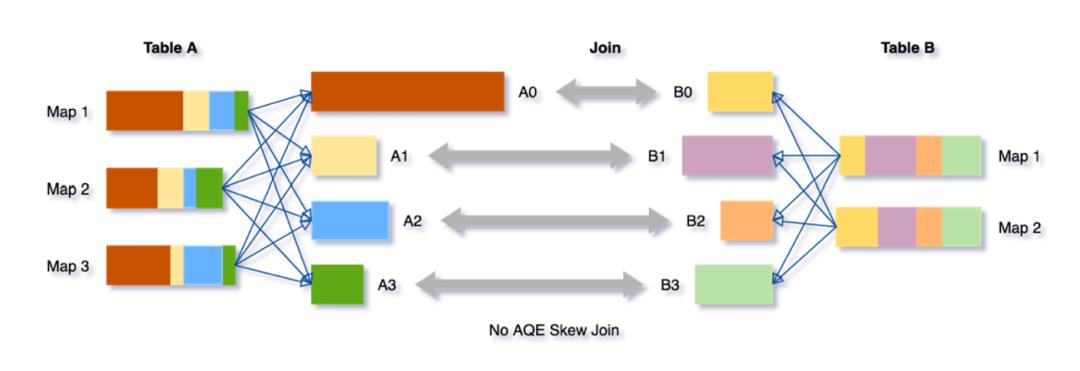
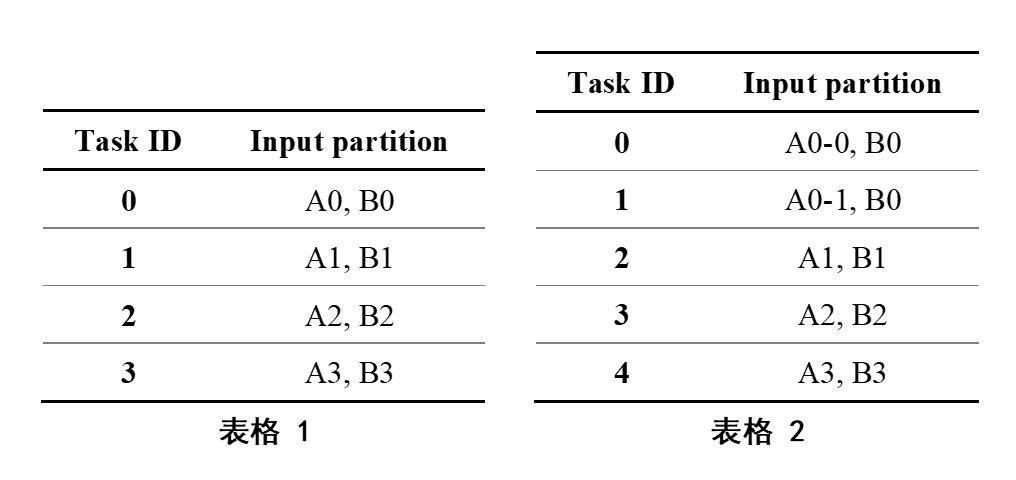
下面我们借用databricks的一篇blog里的例子来介绍skew join的实现。如图2,Table A join Table B,shuffle partition是4,那么在join阶段task和shuffle partition的分配情况如表1所示。但从图2我们可以看出,partition A0的size要明显大于其他partition的size,所以对task 0来说,其所要读的数据量也远大于其他task的数据量。
这就是一个典型的data skew现象。
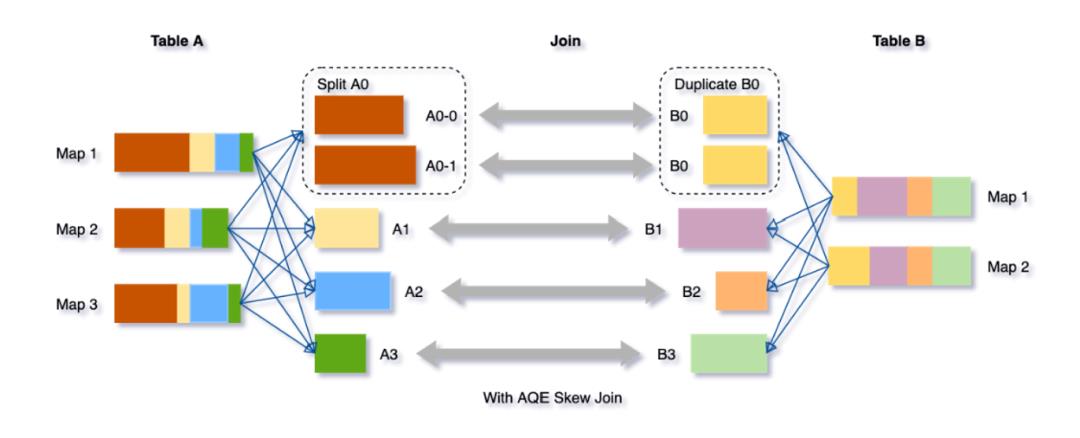
针对这种问题,Spark提供了一种解决方案,其基本思路是,对那些skewed partition进行切分,将skewed partition的数据分片分配到不同task上。这样原本一个shuffle partition只会分配到一个task,变成了同一个shuffle partition的数据可能分配到多个task上,如图3所示,从而减小了单个task的压力,进而提升整个SQL的执行速度。经过skew join处理后,其分配情况如表2所示。因此在join阶段,task数量由4变为5,并行度提升了
25%。
skew join通过对skewed partition进行切割,能够大幅度提高并行度,避免出现长尾现象。从而大大提升了某些SQL的执行性能。但通过观察线上的使用情况,我们发现了现有skew join的一些不足。
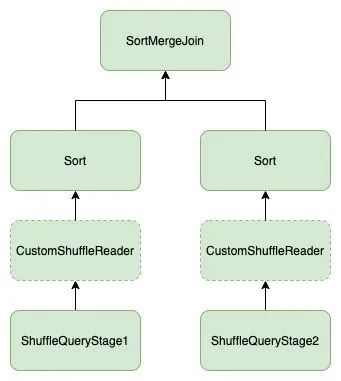
首先,现有的skew join只支持最基本的sort merge join的pattern。如图4所示,join左右两边必须是sort和shuffle,而线上的SQL千变万化,这样的pattern不足以覆盖所有的场景。
其次,我们在线上经常会发现一些case,在SQL执行过程中出现了data skew的现象,而且plan也match现有skew join支持的pattern,但skew join并没有生效。经过分析发现, Spark在决定是否采用skew join的时候还有一个判断:
引入skew join后是否会导致引入额外的ShuffleExchangeExec,如果会,则放弃使用skew join。那什么样的情况下会引入额外的ShuffleExchangeExec呢?
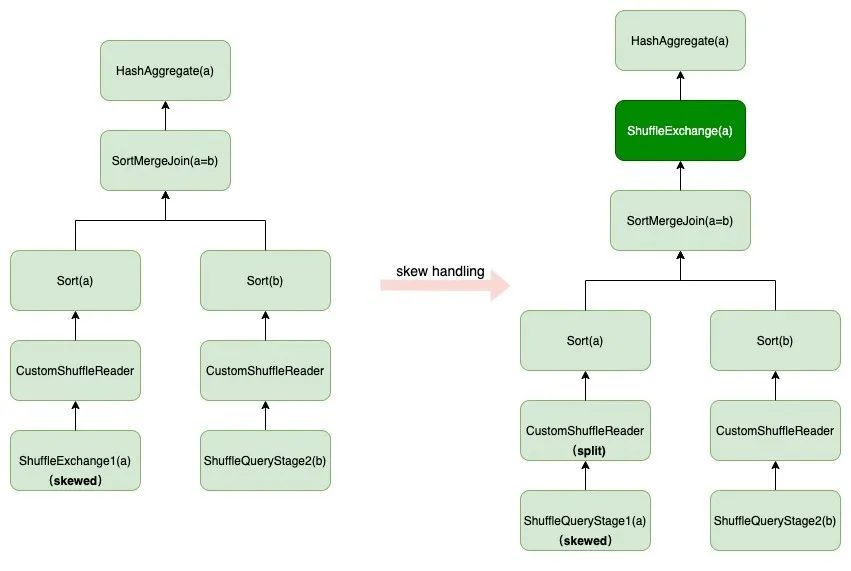
图5中给出了一个例子:两表join,两边表的join key分别是column a和column b,join完后再根据column a做聚合。由于在join之前,左表就会根据column a做一次shuffle,而join本身不改变输入数据的分布情况,因此join之后的结果分布还满足HashPartitioning,partition key为column a。这种分布满足HashAggregate的requiredChildDistribution,所以在SMJ之后不需要再做一次shuffle。但是,我们发现在ShuffleExchange1中出现了data skew。根据前面的介绍,如果要使用skew join,就要对ShuffleExchange1生成的RDD 的skewed partition进行拆分,同一个partition的数据在shuffle read时被分配到多个task中。
这可能导致一些column a相同的record被分配到不同的task中,从而不再满足column a做aggregation需要满足的条件,即“所有column a相同的record被分配到同一个task中”,因此在图中,需要在HashAggregate之前加上一次shuffle。
然而,我们在生产环境中发现,一些case由于data skew导致的性能下降要远比多一轮shuffle更严重。对于这些case我们倾向于采用skew join,哪怕会因此多出一些shuffle的开销。
针对以上提到的两点不足,我们对现有的skew join做了一些优化,使其能够覆盖到更多data skew的情况,主要包括以下三点。
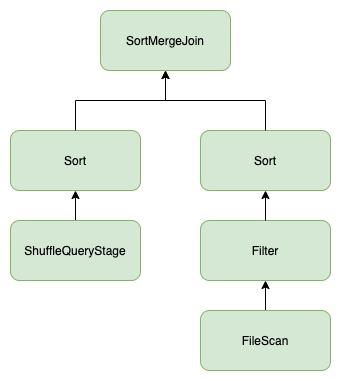
在ebay内部,bucket这一特性被广泛使用于各个核心表中。如此一来,这些表在和其他的表或者数据做join时,就可以通过bucket join来避免shuffle,其plan如图6所示。我们发现这里的 ShuffleQueryStage作为中间结果,时常会出现data skew的现象。现有的skew join还无法支持这种pattern的plan,如果要利用上skew join,只能在这些bucket表参与join时,不再走bucket join,强制做一轮shuffle。但很多bucket表作为核心表通常又比较大,做一次shuffle的开销也比较大。基于此,我们对现有的skew join做了一些改进,使其适用于这种pattern。
基于前文的介绍,skew join的核心是对join一边的RDD partition做split,另外一边的RDD 对应的partition做duplicate。在现有的实现中,split和duplicate的逻辑是通过CustomShuffleReaderExec来实现的,CustomShuffleReaderExec在shuffle read阶段对某些shuffle partition的数据做切分或者重复读。而对于我们这种case,因为一边没有shuffle,所以没法复用现有的逻辑。而且对这些bucket表,在建表时 bucket column选得通常比较合理,数据在各个bucket分布均匀,因此不需要处理bucket表这一边data skew的情况,而只需要考虑怎么对bucket表的某些partition进行duplicate。
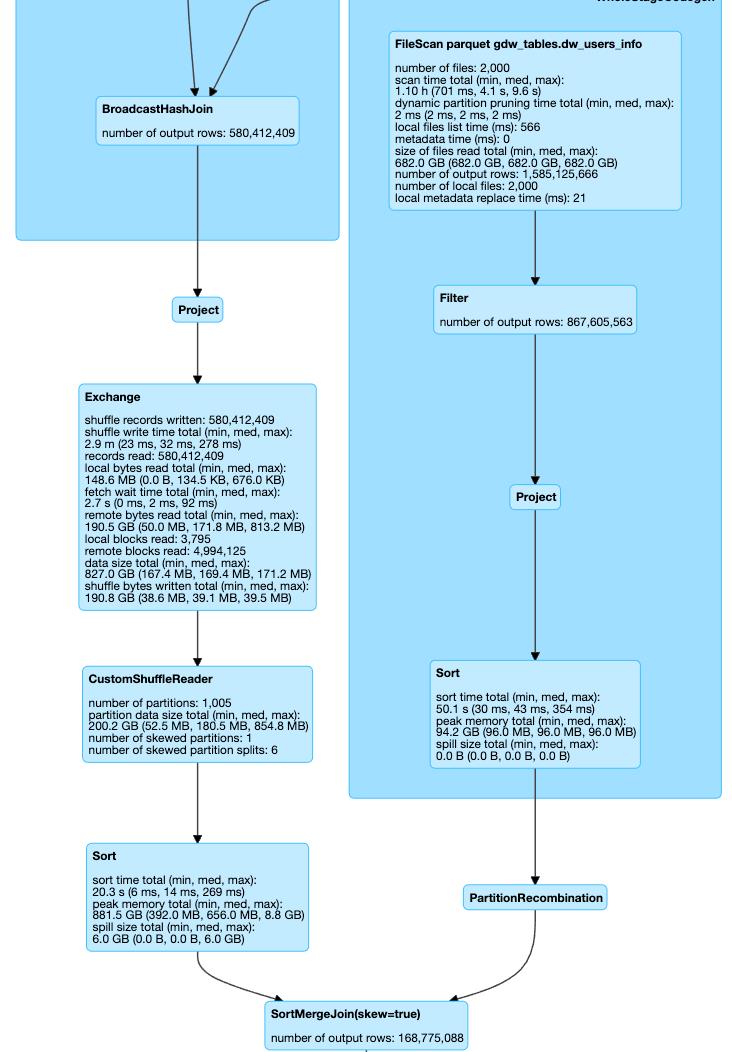
我们的做法是增加一种新的operator, PartitionRecombinationExec,其execute方法返回一个RecombinationedRDD。RecombinationedRDD实现如图7所示,它本身没有什么计算逻辑,只是对其parent RDD的partition做一些重新排列,duplicate出一些需要重复读的partition, 对partition做重排列是在方法getPartition中实现的。然后在生成执行计划阶段,把operator PartitionRecombinationExec添加到plan的合适的位置就可以了。其实现效果如图8所示。
这里不得不称赞一下Spark优雅的设计,让这些工作变得如此的简单。因为有了RDD这一层抽象,所有的operator都只需要在RDD上进行操作。当实现一个新的operator时,只需要编写对已有RDD的输出的每一条InternalRow的处理逻辑,然后返回一个新的RDD,最后把这个新的operator挂在logical/physical plan上,所有的工作就都完成了。剩下的一切就可以交给Spark框架去处理,从新建的RDD怎么去和已有的RDD串联,到这些RDD上的操作最终怎么转换成一个个task,再到这些task又怎么在一个复杂的分布式的环境中执行… 几乎包揽一切,大大提高了开发效率。
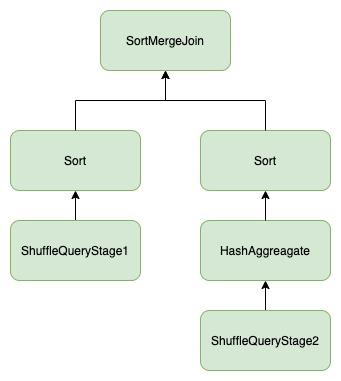
除了上述当有一边是bucket表的场景中,我们还在线上发现了很多patten,现有的skew join没能覆盖到。如图9所示,SMJ的一边有一个HashAggregate,根据前文的介绍,如果aggregation key和join key是一致的,在HashAggregate后也不需要加上ShuffleExchangeExec。
那么对于这种case,如果发生了data skew,我们是否也可以通过现有的skew join的方式去处理呢?这需要分两种情况进行讨论。
ShuffleQueryStage1出现了data skew。如果要apply skew join,就要把ShuffleQueryStage1对应的RDD的skewed partition做拆分,而ShuffleQueryStage2里与之对应的partition做duplicate。
这里面有个问题,做完duplicate后再执行HashAggregate,整个query的结果还正确么?做完duplicate后就不再满足“具有相同aggregation key的所有record分布到同一个RDD partition内”这一条件,那么最终执行的结果是正确的么?
答案是肯定的。这其实就是skew join实现的巧妙之处,
skew join并不保证在整个处理过程中每一个算子的结果的正确性,而只保证join后结果的正确性。如果我们再看图4中的例子,其中有一个CustomShuffleReaderExec会做duplicate read。因此,如果只看该CustomShuffleReaderExec输出的结果,那显然也是不正确的,但是根据join执行的原理,在join之后那些duplicate的record会自动去重。而图9的例子跟图4的例子本质上没什么不同,即使aggregation的输出结果看起来不正确,但是经过上层的SMJ,就确保了结果的正确性(当然重复的计算也会带来一些额外开销)。
ShuffleQueryStage2出现了data skew。如果要apply skew join,那么HashAggregate读的数据将是经过split的数据,仍旧不再满足“具有相同aggregation key的所有record分布到同一个RDD partition”这一条件。那这次查询返回的结果还正确么?
答案是否定的。现有的skew join中SMJ可以做到对那些duplicate的record去重,而对那些分布在不同task中的具有相同aggregation key的record不能起到聚合的作用,这些record只有全部分配到同一个task中才能被完全聚合起来,因此SMJ输出的结果也将不再正确。
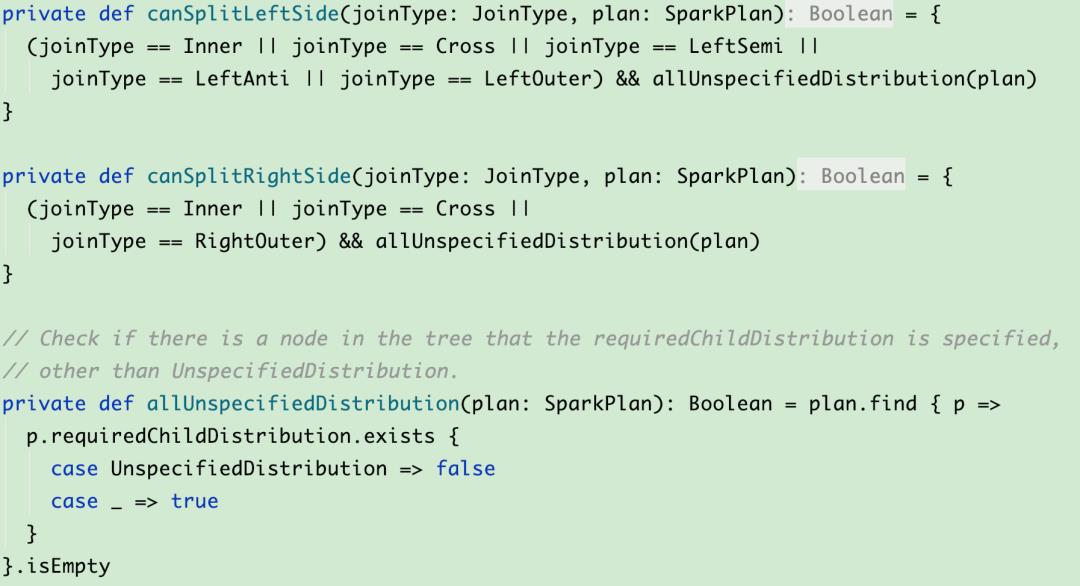
经过上述讨论,我们会发现,在SMJ中,只有所有子节点对input的数据分布情况没有要求的一边出现了data skew时,我们才可以对其进行拆分,进而apply skew join。于是我们对rule OptimizeSkewedJoin做了一些改进,一方面放宽了其能够匹配到的plan的范围,如图10所示,另一方面在判断某一边能不能split时加了条件,如图11所示。
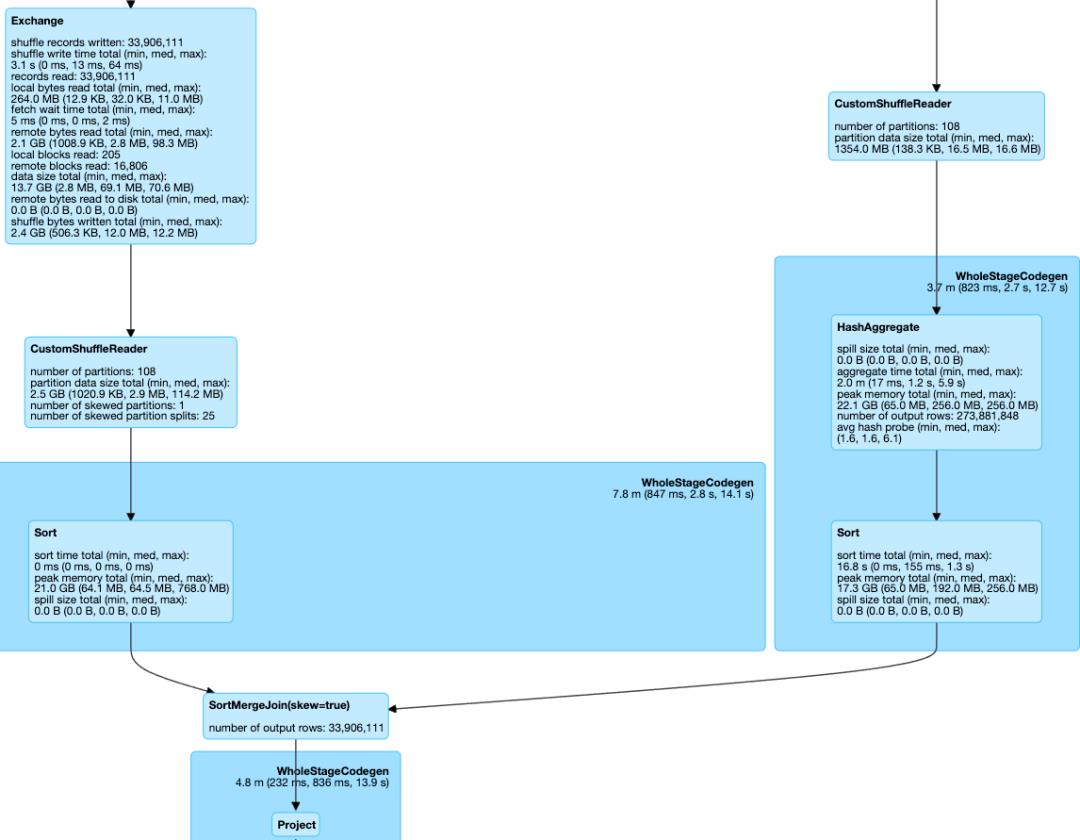
经过这一改进,skew join支持了更多种情况,如图12所示。SQL及其执行的DAG为图13。
在shuffle开销可以接受的情况下,尽可能应用skew join
前文讲到Spark在决定是否要apply skew join时会判断是否会因此引入新的shuffle,如果发现会引入新的shuffle,则停止apply skew join。之所以这样做,一个原因是现有的skew join的实现还不能正确处理这样的case。因为在apply skew join后,框架并不会再去执行rule EnsureRequirements,去添加一些必要的shuffle。于是我们去掉了这个check,并尝试在执行完OptimizeSkewedJoin后,再去执行一遍EnsureRequirements,但也因此引发了不少问题。
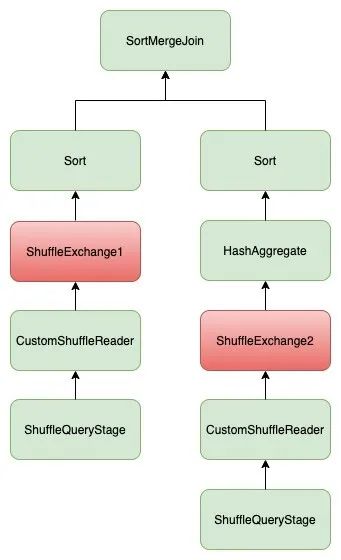
首先,AQE引入了rule CoalesceShufflePartitions,用来合并shuffle partition,从而减少shuffle read task的数量。而合并shuffle partition这一过程是在operator CustomShuffleReaderExec里实现的,因此在执行完CoalesceShufflePartitions后,会在一些shuffle 之后加上一个CustomShuffleReaderExec。而由于CustomShuffleReaderExec会合并不同的shuffle partition,它会改变input数据的分布情况,所以CustomShuffleReaderExec的outputPartitioning是UnknownPartitioning。在这种情况下,再执行一遍EnsureRequirements会引入新的ShuffleExchangeExec,如图14所示。
我们先关注ShuffleExchange2,HashAggregateExec需要的数据分布是“具有相同aggregation key的所有record分布到同一个RDD partition内”,这里CustomShuffleReaderExec做的事情只是把多个shuffle partition合成一个partition,合并之后的数据分布还满足这一条件,因此ShuffleExchange2是没有必要的。为了解决这个问题,我们加入了一种新的Partitioning CoalescedPartitioning,其实现如图15所示。除了HashPartitioning,我们还考虑了现有的所有Partitioning经过coalesce后满足的效果。而如果CustomShuffleReaderExec只是合并了一些partition(没有拆分partition),它的outputPartitioning就是CoalescedPartitioning。
接下来考虑SMJ。经过rule CoalesceShufflePartitions后,SMJ两边引入了CustomShuffleReaderExec,而CustomShuffleReaderExec的outputPartitioning是我们前面新加的Partitioning CoalescedPartitioning。在上文中我们讲过,对SMJ来说,两边的input只满足“具有相同join key的record分布在RDD的同一个partition”是不够的,还要保证join两边的input按照相同的规律分布。因此SMJ两边的input 如果经过了coalesce的话,我们还需要保证两边coalesce的方式是一致的。于是我们在EnsureRequirements中又加了一些逻辑来保证这一点,如图16所示。SMJ两边input的outputPartitioning如果是CoalescedPartitioning的话,还必须保证coalesce spec一致,否则至少会有一边再加shuffle。
前面只谈到通过rule CoalesceShufflePartitions引入的CustomShuffleReaderExec,而skew join本身也是通过CustomShuffleReaderExec来做shuffle partition的duplicate和split的。这里的CustomShuffleReaderExec做的事情不止是合并多个shuffle partition,因此其outputPartitioning也不再是CoalescedPartitioning。那么如何避免EnsureRequirements在这些OptimizeLocalShuffleReader之后加上ShuffleExchangeExec呢?这里的情况比较复杂,由于篇幅有限,我在这里就不做过多介绍,基本思路有两个:
-
对于一个SMJ operator,如果发现其已经apply skew join,改变它的requiredChildDistribution,让其对子节点的outputPartitioning不再有特殊要求,从而避免引入不必要的shuffle。
-
在执行完EnsureRequirements后,再通过模式匹配来去掉一些不必要的shuffle。
图17是一个示例SQL,其执行的DAG如图18所示。
现有的skew join是在AQE的框架内实现的。而自从引入AQE后,Spark查询优化器的复杂度提升了很多,从以往容易理解的平铺直叙式的展开的方式,变成了如今这种往返迭代,动态调整的方式。这一转变带了不少挑战,在AQE中添加的逻辑可能会在意想不到的时刻被触发,而且很可能触发多次。同时,由于我们线上分析型的SQL千变万化,动辄上百近千行的SQL,生成的plan都异常复杂。对这样的plan做调整必须异常谨慎,因为你很难想到这些调整正作用于一个什么样的plan上。而更严重的是,对这些核心的rule,如EnsureRequirements的改动,稍有不慎就会导致漏加shuffle或者sort,最终导致查询结果不正确,这是不能接受的。
那在对现有的skew join做改动时,应该如何尽量去降低这些风险呢?我想,首先需要我们对AQE框架的实现有比较深刻的理解。其次,对于skew join,需要考虑三个问题:skew join的原理和实现都是什么样的?它能够支持的pattern有哪些?它支持的边界又在哪里?当把这些问题都想清楚后再去做改动,基本上就能够保证这些改动逻辑上的正确性。尽管这些改动可能会生成一个不够优的plan(前期我们经常会发现生成的plan多了一些没必要的shuffle或者sort),但基本不会生成错误的plan。在做优化的同时,我们也加深了对Spark和AQE的理解,这项工作充满挑战又富有乐趣!