浅析日志模式识别技术(Spark)原理
Posted FCC30+
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析日志模式识别技术(Spark)原理相关的知识,希望对你有一定的参考价值。
22
星期五
2021年1月
验“金”室
近年来,随着金融业务交易量不断上涨,业务交易系统出现生产问题风险的概率也大大增加,给应用的运维、监控、报警带来很大的挑战。在此背景下,智能运维概念逐渐火热,实时分析交易日志进行故障预测和根因定位已是通用方案,并以“日志模式识别”之名大行其道。据悉,很多业界公司是基于Spark、Elasticsearch等技术框架,进行海量日志数据实时分析处理,实现“日志模式识别”。本文旨在概述Spark的技术原理,着重分析技术特点,对技术细节不做过多描述。
一、 Spark的概念及特点
1.Spark的概念
Spark是一种快速、通用、可扩展的大数据分析引擎,是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。另外,以Spark为中心的开源生态系统,将在应用程序、运行环境和数据源等方面得到巨大的发展,包括与所有系统相关的基本数据,如图1所示。
图1 Spark的开源生态系统
2.Spark的特点
Spark具有快、易用、通用、兼容性好四大特点:
快
与Hadoop的MapReduce相比,Spark基于内存的运算速度要快100倍以上,基于硬盘的运算也要快10倍,Spark实现了高效的DAG执行引擎,从而可以通过内存来高效处理数据流;
易用
Spark不仅支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用,除此之外,Spark支持交互式的Python和Scala的shell,可以十分便捷地在这些shell中使用Spark集群来验证解决问题的方法;
通用
Spark提供了统一的解决方案,可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX),这些不同类型的处理都可以在同一个应用中无缝使用。另外,Spark还可以很好地融入Hadoop的体系结构中,可以直接操作HDFS,并提供Hive on Spark、Pig on Spark的框架集成Hadoop;
兼容性好
Spark可以十分便捷地与其他开源产品融合。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
二、Spark的体系结构及运行机制
1.Spark的体系结构
Spark主要包括Spark Core和在Spark Core基础之上建立的应用框架Spark SQL、Spark Streaming、MLlib和GraphX。
Core库中主要包括上下文(Spark Context)、抽象数据集(RDD、DataFrame和DataSet)、调度器(Scheduler)、洗牌(shuffle)和序列化器(Serializer)等。Spark系统中的计算、IO、调度和shuffle等系统基本功能都在其中。
Core库之上根据业务需求分为用于交互式查询的SQL、实时流处理Streaming、机器学习Mllib和图计算GraphX四大框架,除此外还有一些其他实验性项目如Tachyon、BlinkDB和Tungsten等。Spark体系结构如图2所示。
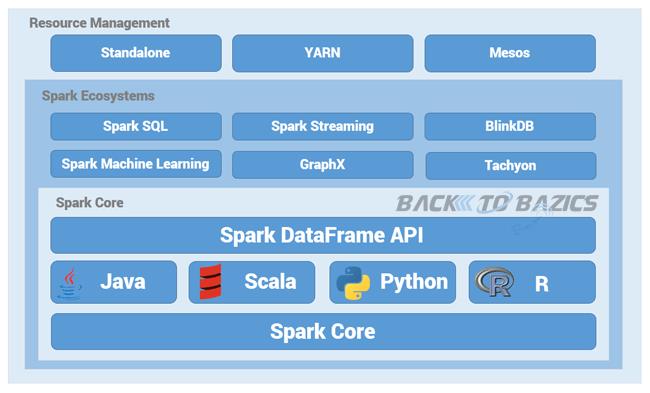
图2 Spark的体系结构
2.Spark的运行机制
Spark集群的运行机制如图3所示。
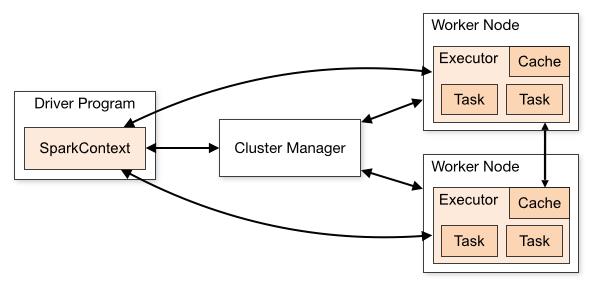
图3 Spark的运行机制
Spark应用在集群上作为独立的进程组来运行,在应用程序的main进程中通过SparkContext来协调(称之为driver进程)。
具体地说,为了运行在集群上,SparkContext可以连接至几种类型的Cluster Manager(一般称为Master,既可以用Spark自己的Standlone Cluster Manager或者Mesos,也可以使用YARN),它们会分配应用的资源。一旦连接上,Spark获得集群节点上的Executor,这些进程可以运行计算并且为你的应用存储数据。接下来,它将发送应用代码(通过JAR或者Python文件定义传递给SparkContext)至Executor。最终,SparkContext将发送Task到Executor进行运行。
三、Spark的两种高可用实现
1. 基于文件系统的单点恢复
基于文件系统的单点恢复主要用于开发或测试环境。当Spark提供目录保存Spark Application和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程,恢复已运行的Spark Application和worker的注册信息。
2. 基于Zookeeper的Standby Masters
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然Spark集群存在多个Master,但是只有一个是Active的,其他的都是Standby。加入ZooKeeper的集群整体架构如图4所示。
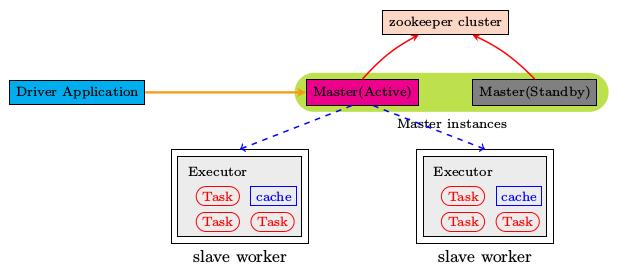
图4 Spark的高可用(基于Zookeeper)
四、Spark的应用
Spark能够一次处理PB级的数据,也可以分布在数千个协作的物理或虚拟服务器集群中,同时有一套广泛的开发者库和API,支持多种编程语言的灵活性特点,能够适合各种环境。
Spark有以下两种最常见的应用场景:
一是离线场景,可以以时间为维度,几年累积的数据集,或者以业务为维度,某个领域的大数据集等,这种数据我们一般叫做离线数据或者冷数据。
二是实时场景,网站埋点、实时从前端页面传输过来的数据、业务系统或物理硬件实时传输过来的数据、硬件信号或者图像数据等,需要实时去计算处理并且返回结果的数据。
1.Spark的业界应用
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前,百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模(2014年),是当时已知的世界上最大的Spark集群。Spark的大规模应用示意如图5所示。

图5 Spark的大规模应用
2.Spark在金融行业的应用
近年来,金融交易系统的复杂度呈指数级增长,带巨大来的运维挑战。采用Spark、Elasticsearch技术框架并结合机器学习算法实现“日志模式识别”,能够协助生产运维解决日志分析慢、根因定位难的问题,逐步实现智能运维,保障生产系统的平稳有序和金融交易的高效可靠。基于Spark的日志模式识别系统架构如图6所示。
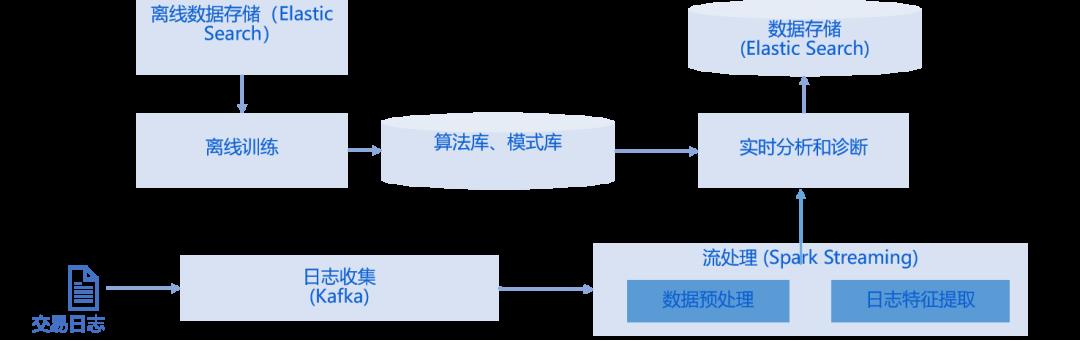
图6 基于Spark的日志模式识别系统架构
往期推荐
FCC30+
长按左边二维码
以上是关于浅析日志模式识别技术(Spark)原理的主要内容,如果未能解决你的问题,请参考以下文章