爬虫入门:Firefox 结合 Scrapy Shell 爬取网页数据
Posted DeveloperPython
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫入门:Firefox 结合 Scrapy Shell 爬取网页数据相关的知识,希望对你有一定的参考价值。




阅读本篇大概需要 4 分钟。
本来这篇是要接着之前 Python 基础的,但由于基础讲的太多,真的会很累。所以先暂停一两篇关于 Python 基础的分享。这篇分享一些有意思的东西。
今天我在 Github 上创建了一个组织,名叫「SpiderMan」
这个组织的目的是玩转 Python 爬虫,目前其中有一个项目就是昨天我提到的 “什么值得买” 这个平台的爬虫。
目前有三个读者联系到我了,我初步了解了下有一个是爬虫高手 A,另外两个 B 和 C 是有一定 Python 基础,但在爬虫方面还是初次。不过我对他们都是同样的看待,我们建了一个微信群他们有问题都会抛出来。其次我也会去主动问他们某个知识点是否了解,比如今天要提到的 Scrapy Shell。除了刚才提到的 A 会, B 和 C 对这个只是听到过。所以我就把这个知识点在这里安利下。(当然,有兴趣加入组织的可以在后台或者 Github Issues 里面联系我)
Scrapy Shell 是什么?
你可以把这个理解为 Python 爬虫的一个测试工具。提到爬虫,我们最常见就是提取 html 中某个标签下的数据,但在提取之前我们需要找到这个标签位置,这个位置在学术上就是 XPath。
大家都知道 HTML 的页面是 XML 格式的,在 XML 中需要定位到某个标签的话就需要有个路径。所以你就可以把 XPath 理解为 XML 中某个标签的路径,比如从 html 标签到 a 标签的内容。
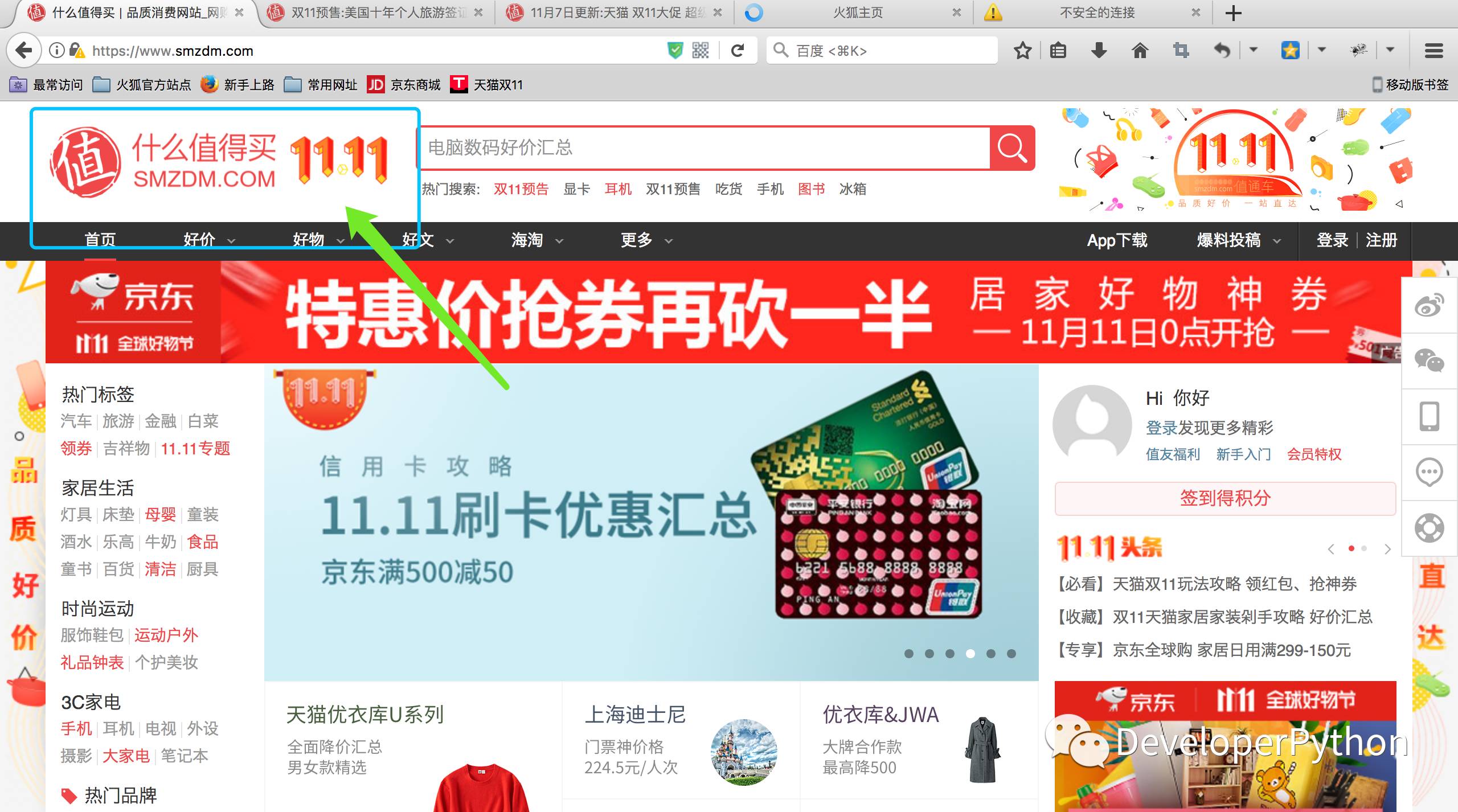
举个实际的简单例子,我们来找找 “什么值得买” 官网页面的 Logo 所在的 Xpath 路径:
1. 在 FireFox 中打开“什么值得买”的官网
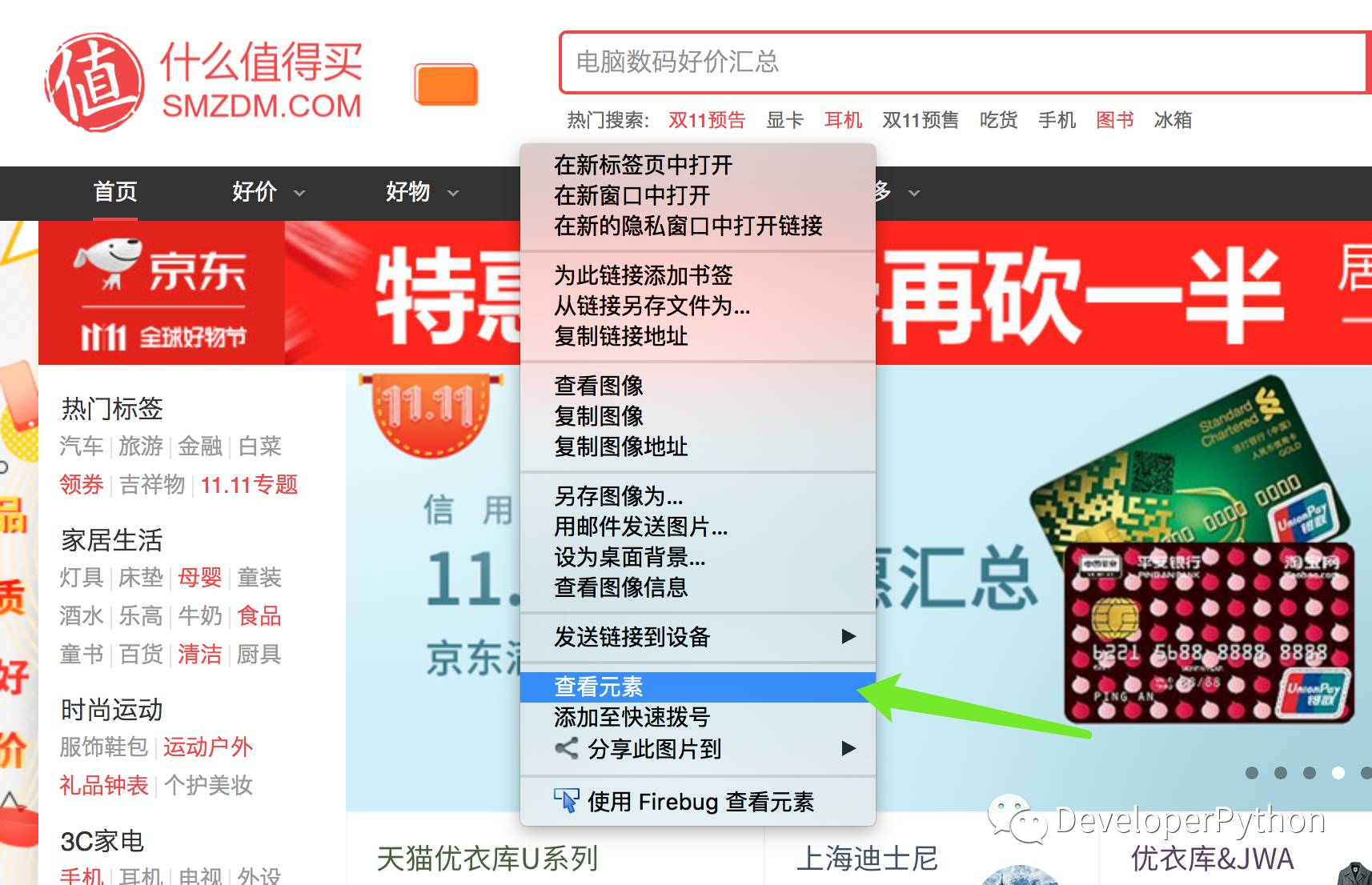
2.在当前页面点击鼠标右键,并选中 “查看元素”
3. 选中之后,会展示如下界面,然后选中工具栏的左上角 箭头按钮,选中之后就可以用鼠标点击页面上的任意内容,比如我这里点击 Logo
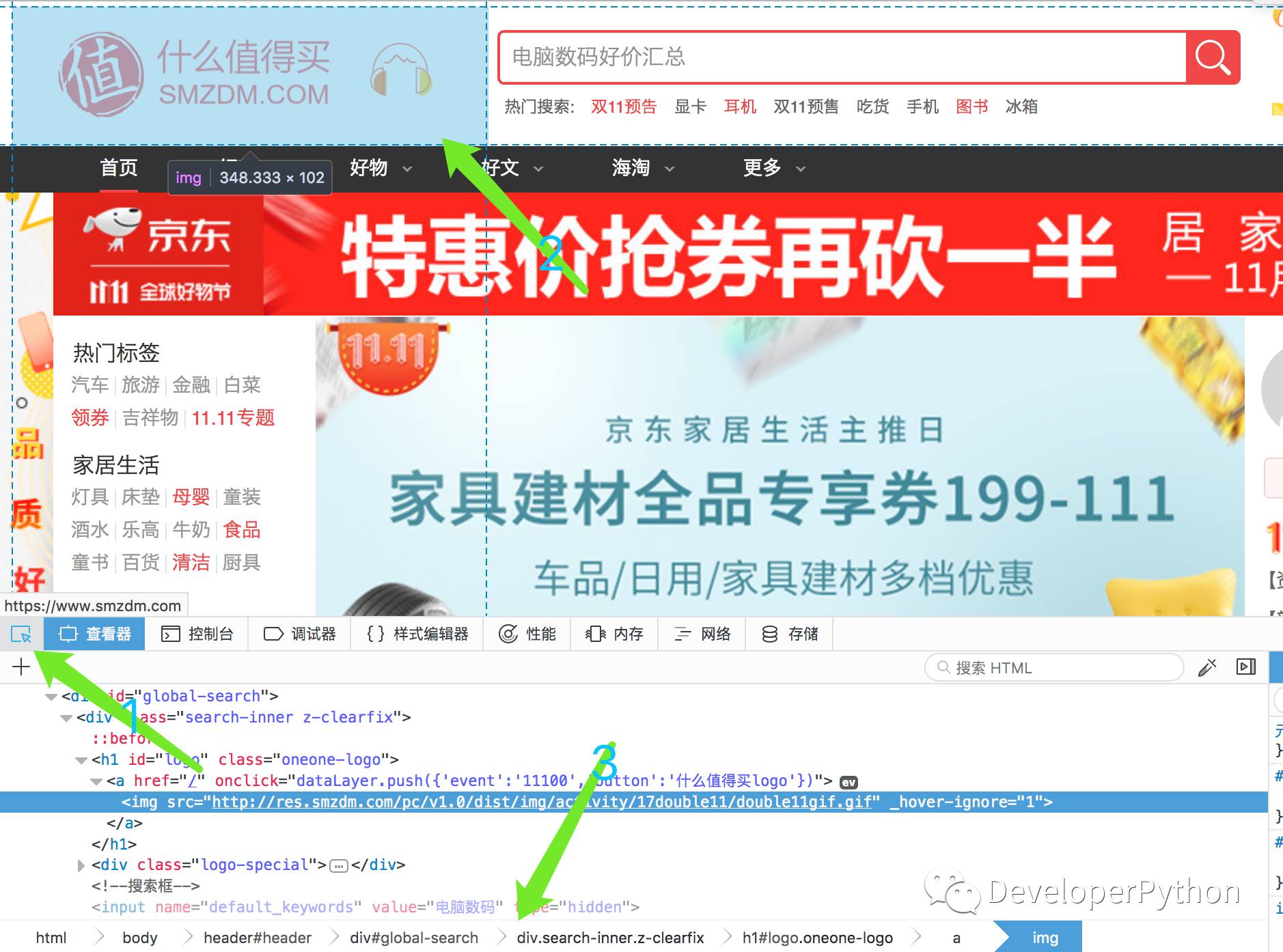
看到图片最底部会出现一个路径,这就是 Logo 在 xml 中的路径。可以看到 html->body......-> img 就是 这个 Logo 的 XPath。其中每个路径主要分为三段,第一段是标签名,第二段 # 后面的是当前标签的 id ,第三段 . 后面的是标签的 class 名。那么这个 XPath 就可以这么写:
有了这个 Xpath,我们就可以通过写 Python 的代码去拿到这个标签的数据,一般我们会用到 Scrapy 框架来做这件事。这篇文章暂不分享 Scrapy 框架,不了解的可以看 。
那么,我们如何在不写代码的情况下去校验这段 XPath 是否能拿到标签数据呢?
命令:
scrapy shell 'url 地址'➜ /Users/xiyouMc > scrapy shell 'https://www.smzdm.com'
>>> response.xpath('/html/body/header[@id="header"]/div[@id="global-search"]/div[@class="search-inner z-clearfix"]/h1[@id="logo"]/a/img/@src')
[<Selector xpath='/html/body/header[@id="header"]/div[@id="global-search"]/div[@class="search-inner z-clearfix"]/h1[@id="logo"]/a/img/@src' data=u'https://res.smzdm.com/pc/v1.0/dist/img/a'>](看不清的,可以在浏览器打开)
然后我们通过 reponse.xpath() 来拿到这个路径下的标签数据。不过这时候拿到的还是一个 Selector 对象,要拿到准确的数据我们在后面加上 extract()
>>> response.xpath('/html/body/header[@id="header"]/div[@id="global-search"]/div[@class="search-inner z-clearfix"]/h1[@id="logo"]/a/img/@src').extract()
[u'https://res.smzdm.com/pc/v1.0/dist/img/activity/17double11/double11gif.gif']
>>>这样我们就通过Scrapy Shell 来拿到了 XPath 的标签数据。当然,这只是爬虫的第一步,不过这也算是爬虫中最关键的一步。
预告下,下周我可能会在某天晚上直播一场从零开始的一个爬虫项目,敬请期待。
https://github.com/xiyouMc/SmzdmSpider
以上是关于爬虫入门:Firefox 结合 Scrapy Shell 爬取网页数据的主要内容,如果未能解决你的问题,请参考以下文章