生信数据挖掘的9分SCI也是灌水?
Posted 生信人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生信数据挖掘的9分SCI也是灌水?相关的知识,希望对你有一定的参考价值。
很多小伙伴们,看多了那些完全不动脑的灌水文章,还以为生信数据挖掘只能发一些lowbee的文章,然鹅,白介素2同学的答案是:非也,证据是以下分享的这篇文献,题为:Prognostic microRNA/mRNA signature from the integrated analysis of patients with invasive breast cancer(灌水气息浓重的标题)。 发表在大名鼎鼎的PNAS杂志,生物医学界的小伙伴们应该没有不知道的吧。看下影响因子变化就清楚了,稳定得害怕。
以下分享这样一篇基于TCGA及其它多数据集的数据挖掘做了哪些工作,话不多说了,先上摘要。

大概的内容就是用了TCGA数据库的一个包含466个病人的子集找到了mRNA/miRNA的预后标志模型,预测效果不错。在早期肿瘤表现更佳,而且更重要的是作者成功的在另外8个数据集中验证了这个模型。最最重要的是,作者还与现有模型进行比较,发现比现有的商业模型的表现都更好,就是这些工作了。
分析流程思路
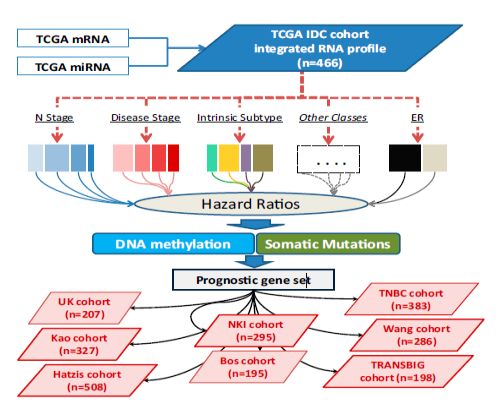
分析流程,作者给出了一张流程图,思路非常清楚,首先是整合TCGA的miRNA/mRNA表达矩阵,筛选预后标志,在各个亚型子集进行进一步筛选表现稳定的。然后再通过8个独立的数据集进行验证。

这是筛选标准,作者这里是在至少两个独立子集才被认为是有预后意义的基因,这个标准完全是自己可控的。

接下来又是进一步限制基因集的数量,突变和甲基化的限制,其实目的还是一个降维,直白点就是基因不能太多。
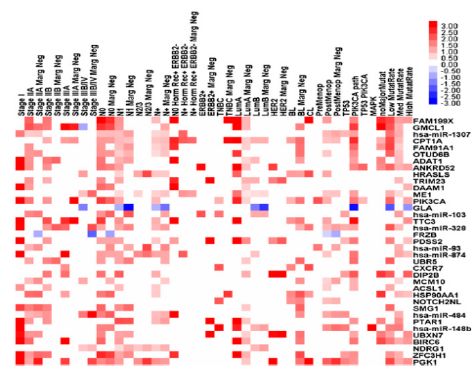
一个预后相关基因的热图展示,接下来就是构建自己的风险模型了,作者用的是这样一种方式:叫做监督的主成分方法

接下来就是常规的基于基因表达标志的高低风险的生存曲线,ROC曲线。
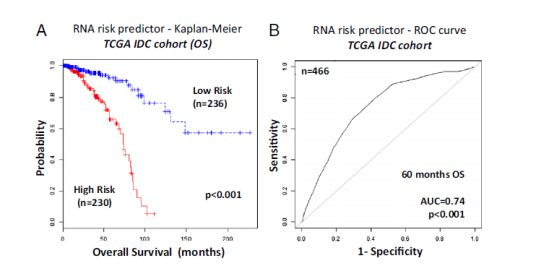
以及在独立数据集的验证:
当然,由于版面限制等原因,作者并不会像灌水般的把一些无关紧要的结果放上去,仅仅是关键结果。还有很多其它的结果可在原文官网找到,如需要可自行仔细研究,以下附上网址
https://www.pnas.org/content/110/18/7413.long
这样的思路,完全可以有很多种,千变万化,还是那句话数据挖掘的方法只是工具,如何使用还是看自己。
内容分享完了,有没有发PNAS的冲动?赶紧去留言呀,没准小编大大们看群众反响热烈,专门录制课程嘞!
总结陈词
总结一下,本文的思路其实并不新奇,但工作扎实。看到这,有些小伙伴可能会觉得这个看起来工作也不多嘛,应该不难吧? 这就好比曾经有人跟我说:“我知道你写文章,分析数据辛苦,那也没有我们做实验辛苦的呀,大部分的工作还是我们的,你们不能有通讯作者”。这时,白介素2同学只能呵呵一笑。
生信人曾经写过一句“套路虽易,分析不易,且行且珍惜”。今天白介素2同学要说的是:“说得虽易,分析不易,且说且珍惜”。一方面,要具备分析数据的能力本身就需要经过长期的积累,而不是有小伙伴想象中“他们只是点了几下鼠标,点点点”。另一方面分析的过程,虽然小编同学说起来指点江山,很快一篇讲完了,真正自己去实施的过程,其实会遇到很多问题,如何找到数据,不同数据如何整合,代码调试。举个栗子,这篇文献中自己构建的模型与其它模型的比较,需要获取其它模型的基因集,模型构建方法,而不同模型本身的构建又是有差异的,有些是基于芯片的,RT-PCR的,也有测序的,这样就会导致模型比较的困难。(只是一个小小的栗子)。
2019年,遇见更好的自己
更多套路咨询13120220117(微信同号)
以上是关于生信数据挖掘的9分SCI也是灌水?的主要内容,如果未能解决你的问题,请参考以下文章
GEO数据挖掘文章发到11分,是如何做到的?|(西安讲座场地调整通知)
我用R语言发了9篇SCI,附免费领取:R语言自学全套视频教程。