技术丨工业大数据挖掘的利器——Spark MLlib
Posted AI芯天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术丨工业大数据挖掘的利器——Spark MLlib相关的知识,希望对你有一定的参考价值。
一提到大数据,人们首先会想到在互联网和商业等环境中,利用大量的行为数据来分析用户行为和预测市场趋势等应用。但是对工业大数据的定义和应用却很难直观地理解和想象。
"

一提到大数据,人们首先会想到在互联网和商业等环境中,利用大量的行为数据来分析用户行为和预测市场趋势等应用。但是对工业大数据的定义和应用却很难直观地理解和想象。工业大数据的挑战和目的则要通过“3B” 和 “3C” 来理解。
工业大数据应用的“3B”挑战:
· Bad Quality——在工业大数据中,数据质量问题一直是许多企业所面临的挑战。
· Broken——工业对于数据的要求并不仅在于量的大小,更在于数据的全面性。
· Below the Surface——除了对数据所反映出来的表面统计特征进行分析以外,还应该关注数据中所隐藏的相关性。
工业大数据分析的“3C”目的:
· Comparison(比较性)——从比较过程中获取洞察,既包括比较相似性,也包括比较差异性。
· Correlation (相关性)——如果说物联网是可见世界的连接,那么所连接对象之间的相关性就是不可见世界的连接。
· Consequence (因果性)——数据分析的重要目的是进行决策支持,在制定一个特定的决策时,其所带来的结果和影响应该被同等地分析和预测。
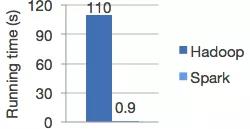
为此,我们发现Spark MLlib是一款非常优秀的工业大数据挖掘工具,拥有顶尖的数据处理、数据挖掘课数据可视化,是数据从业者必备的一把利器。Spark是一个开源集群运算框架,擅长迭代计算。最初是由加州大学柏克利分校AMPLab所开发。Spark使用了内存内运算技术,在内存上的运算速度比Hadoop MapReduce的运算速度快上100倍,即便是在磁盘上运行也能快10倍。Spark允许将数据加载至集群内存,并多次对其进行查询,非常适合用于机器学习算法。
Spark MLlib 主要包括以下几方面的内容:
学习算法:分类、回归、聚类和协同过滤;
特征处理:特征提取、变换、降维和选择;
管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
持久性:保存和加载算法,模型和管道;
实用工具:线性代数,统计,最优化,调参等工具。
上表总结了 Spark MLlib 支持的功能结构,可以看出Spark MLlib是一种高效、快速、可扩展的分布式计算框架;实现了常用的机器学习,如:聚类、分类、回归等算法。
大数据能够带来巨大的商业价值已经毋庸置疑,各行各业均已开展了一场无形的较量,数据提供商、服务提供商都想在这片蓝海强占先机。而目前,Spark已经成为了现在大数据领域最火的开源软件,Spark也被许多企业尤其是互联网企业广泛应用到商业项目中,在国内包括阿里、百度、腾讯、网易、搜狐等。
以上是关于技术丨工业大数据挖掘的利器——Spark MLlib的主要内容,如果未能解决你的问题,请参考以下文章
走进大数据丨Spark Streaming VS Flink