工业大数据处理领域的“网红”——Apache Spark
Posted 格创东智Getech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工业大数据处理领域的“网红”——Apache Spark相关的知识,希望对你有一定的参考价值。
生活离不开水,同样离不开数据,我们被数据包围,在数据中生活。当数据越来越多时,就成了大数据。
在“中国制造2025”的技术路线图中,工业大数据是作为重要突破点来规划的,而在未来的十年,以数据为核心构建的智能化体系会成为支撑智能制造和工业互联网的核心动力。而想要理解大数据,就需要理解大数据相关的查询、处理、机器学习、图计算和统计分析等。Apache Spark 作为新一代轻量级大数据快速处理平台,集成了大数据相关的各种能力,是理解大数据的首选。
简单来讲,Spark就是一个快速、通用的大规模数据处理引擎,各种不同的应用,如实时流处理、机器学习、交互式查询等,都可以通过Spark 建立在不同的存储和运行系统上。今天的格物汇,就带大家来认识一下如日中天、高速发展的大数据处理明星——Spark。
2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目,最开始Spark只是一个实验性的项目,代码量非常少,仅有3900行代码左右,属于轻量级的框架。
2010年,伯克利大学正式开源了Spark项目。
2013年6月,Spark成为了Apache基金会下的项目,进入高速发展期,第三方开发者贡献了大量的代码,活跃度非常高。
2014年2月,Spark以飞快的速度称为了Apache的顶级项目。
2014年5月底Spark1.0.0发布。
2016年6月Spark2.0.0发布
2018年11月 Spark2.4.0 发布
Spark作为Hadoop生态中重要的一员,其发展速度堪称恐怖,从诞生到成为Apache顶级项目不到五年时间,不过在如今数据量飞速增长的环境与背景下,Spark作为高效的计算框架能收到如此大的关注也是有所依据的。
Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,可以高性能地进行批量及流式处理。使用逻辑回归算法进行迭代计算,Spark比Hadoop速度快100多倍。
Spark目前支持多种编程语言,比如Java、Scala、Python、R。熟悉其中任一门语言的都可以直接上手编写Spark程序,非常方便。还支持超过80种高级算法,使用户可以快速构建不同应用。并且Spark还支持交互式的Python和Scala的Shell,这意味着可以非常方便的在这些Shell中使用Spark集群来验证解决问题的方法,而不是像以前一样,需要打包、上传集群、验证等。这对于原型开发非常重要。
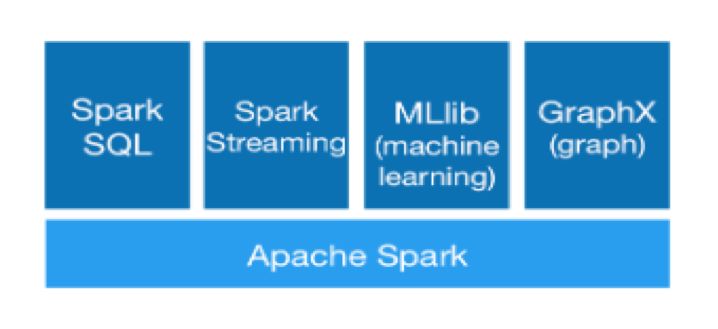
Spark 目前主要由四大组件,如下:
Spark SQL:SQL on Hadoop,能够提供交互式查询和报表查询,通过JDBC等接口调用;
Spark Streaming::流式计算引擎;
Spark MLlib:机器学习库;
Spark GraphX:图计算引擎。
拥有这四大组件,成功解决了大数据领域中,离线批处理、交互式查询、实时流计算、机器学习与图计算等最重要的任务和问题,这些不同类型的处理都可以在同一应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台处理问题,减少开发和维护的人力成本和部署平台的物理成本。当然还有,作为统一的解决方案,Spark并没有以牺牲性能为代价。相反,在性能方面Spark具有巨大优势。
Spark可以运行在standalone、YARN、Mesos、Kubernetes及EC2多种调度平台上。其中Standalone模式不依赖第三方的资源管理器和调度器,这样降低了Spark的使用门槛,使得所有人可以非常容易地部署和使用Spark。
Spark可以处理所有Hadoop支持的数据,包括HDFS、Apach HBase、Apach Kudu、Apach Cassanda等。这对于已部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark强大的处理能力。
Spark与MapReduce 同为计算框架,但作为后起之秀,Spark借鉴了MapReduce,并在其基础上进行了改进,使得算法性能明显优于MapReduce,下面大致总结一下两者差异:
1) Spark把运算的中间数据存放在内存,迭代计算效率更高;MapReduce的中间结果需要落地到磁盘,磁盘io操作多,影响性能。
2) Spark容错性高,它通过Lineage机制实现RDD算子的高效容错,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建;MapReduce的话容错可能只能重新计算了,成本较高。
3) Spark更加通用,Spark提供了transformation和action这两大类的多个功能算子,操作更为方便;MapReduce只提供了map和reduce两种操作。
4)Spark框架和生态更为复杂,首先有RDD、血缘lineage、执行时的有向无环图DAG、stage划分等等,很多时候spark作业都需要根据不同业务场景的需要进行调优已达到性能要求;MapReduce框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行。
工业互联网带来了工业数据的快速发展,对于日益增加的海量数据,传统单机因本身的软硬件限制无法应对海量数据的处理、分析以及深度挖掘,但作为分布式计算框架的Spark却能轻松应付这些场景。在工业互联网平台上,Spark 既能快速实现工业现场海量流数据的处理转换,又能轻松应对工业大数据平台中海量数据的快速批处理分析,自身集成的机器学习框架能够对海量工业数据进行深度挖掘分析,从而帮助管理者进行决策分析。
基于Spark框架自身的优良设计理念以及社区的蓬勃发展状态,相信未来Spark会在工业互联网平台扮演越来越重要的角色。
以上是关于工业大数据处理领域的“网红”——Apache Spark的主要内容,如果未能解决你的问题,请参考以下文章