近距离了解木兰开源社区项目——Apache IoTDB:支持云边端一体化的轻量级高性能时序数据库
Posted 中国开源云联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近距离了解木兰开源社区项目——Apache IoTDB:支持云边端一体化的轻量级高性能时序数据库相关的知识,希望对你有一定的参考价值。
木兰开源社区推广项目Apache IoTDB
Apache IoTDB 项目负责人
王建民,清华大学软件学院院长,主要研究领域为大数据管理、分析与过程数据管理。国家支撑计划制造业信息化科技工程专家组成员;国家863计划先进制造技术领域专家组成员;国家重大科技专项“核高基”基础软件方向实施专家组成员;中国计算机学会大数据专委会委员、数据库专委会委员。工业互联网联盟工业大数据特设组组长。
黄向东,清华大学软件学院助理研究员。主要研究领域为时序数据管理与分布式系统建模。

引 言
物联网诞生于1999年,在其理念和技术的不断革新下,无处不在的设备和设施正在被越来越多的通过网络连接起来,并不断向云端发送实况数据。
近些年,工业4.0和工业互联网成为发展焦点。在这次工业革命中,工业生产和运维过程中机械设备产生的数据成为了新的核心资产。
随着Devops的兴起,运维人员开始追求对IT基础设施、各种服务的运行情况了如指掌的境界,从而开始大量采集对这些设施、进程、用户的监控数据。
上述这些场景中产生的数据,主要都是用来描述一个对象在时间维度上的变化的数据,这类数据就被称为时间序列数据。
时间序列数据其实离我们很近。例如,用苹果手机可以看到手机的电量变化情况,谷歌地图的“时间线”功能(用于记录个人的位置服务)记录的个人位置移动,安装了健康应用的每小时步数统计,佩戴的智能手表检测的心率变化都是时序数据;家里安装的温湿度传感器采集到的家里的温湿度变化,空气净化器采集的PM2.5变化,智能插线板显示的用电功率变化,都是时序数据;每天使用的各种网站服务记录的个人行为信息也是时序(文本)数据。
时间序列数据也可能离我们更远,但时刻影响着我们的衣食住行。机房的每台服务器的CPU、内存、网络带宽占用情况的实时变化,气象观测站观测的每刻气象情况变化,汽车、飞机行驶过程中采集的位置、速度、油耗等各种指标值,发电厂、光纤制造塔里的惰性气体含量变化都是时序数据。可见,时序数据无处不在。
时序数据的定义
研究时序数据的人很多。美国国家标准化委员会NIST将时序数据定义为一系列等时间间隔到达的某个变量的值。TKDE上对时序数据的定义则放松了等时间间隔的约束:一系列时间戳递增的数据点。事实上,通过研究实际场景,我们可以得到更确切的时间序列数据的定义。
以国家级气象观测站为例,全国有近6万个气象观测站,每个气象观测站有70种气象物理量需要采集。某市地铁每列列车拥有3200个指标需要测量,全市列车数达300列。服务器运维监控中,一台服务器需要同时监测IOPS、CPU、网络等十余项指标,而服务器中的重要进程还需要监测CPU占用率、存活时间等指标。这些例子中展现出两个概念:设备与度量指标。所谓度量指标(又被称为工况、测点)是指用户关心的能反映目标的某种状况的数据项,例如CPU利用率、温度、湿度等等。设备是指一个拥有一系列度量指标的实体,例如一台服务器、一个进程、一列车、一个气象观测站等等。一个设备的一个度量指标形成了一条时序数据的唯一标识。随着时间推移,这条时序数据会产生一系列(时间戳,值)的二元组数据点,构成了时间序列数据集。因此,我们定义一条时间序列是由一个时间序列标识(设备和度量指标),一系列时间戳和数据值对组成的无限集。一个时间序列数据库将管理百万甚至千万条这样的时间序列。
如图所示,在对汽车的状态监控中,汽车可以作为设备(国家、地区、车牌号组成了设备ID),而剩余油量、车速则是两个度量指标。因此该图中有4条时间序列(2个设备,2种度量指标),其中3个序列有2个点,一个序列没有数据。
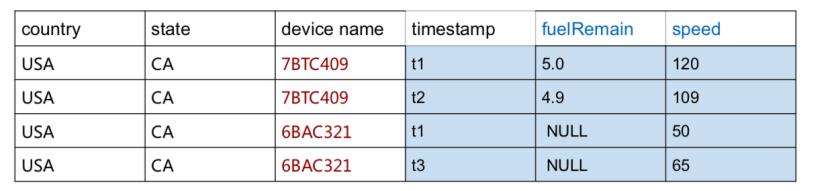
时序数据的管理需求
在此基础上,工业中的时间序列数据还具有低质乱序传输的特点。在一些实 际应用场景中,时间序列数据存在乱序的问题。例如:在物联网与工业传感网中, 因为基础设施或者网络的不稳定,数据的采集和回传会出现中断,在这类情况下数据会出现一定范围的乱序;还有一些比较严重的情况,数据在进入存储系统之前需要经过 kafka等流式处理系统的处理,同一条时间序列数据可能会被 kafka 的多个 partition 消费,从而导致数据在写入存储系统的时候出现乱序。此外,由于 PLC 与 DTU 模块的衔接或网络等问题,一些数据点会在回传前或者回传过程中丢 失,造成数据缺失等质量低下问题。
此外,工业中的时间序列数据具有高质全序查询的特点。时序数据虽然在写 入过程中存在乱序现象,但用户在查询过程中,大多都是要求按照时间维度顺序读取数据。此外,工业互联网中设备的每个传感器会产生一条甚至多条时间序列数据,这些时序数据最有效的存储方式是采用列式存储。然而,实际应用中需要对一个设备的多个度量指标数据,或多个设备的数据同时进行分析,这就要求必须将多条列式存储的时序数据进行连接查询(即按时间戳对齐查询)。该查询的性能对数据分析的效率起到了决定性作用。
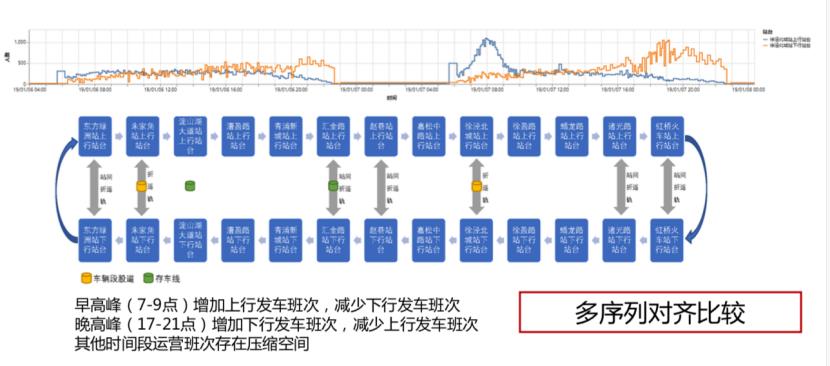
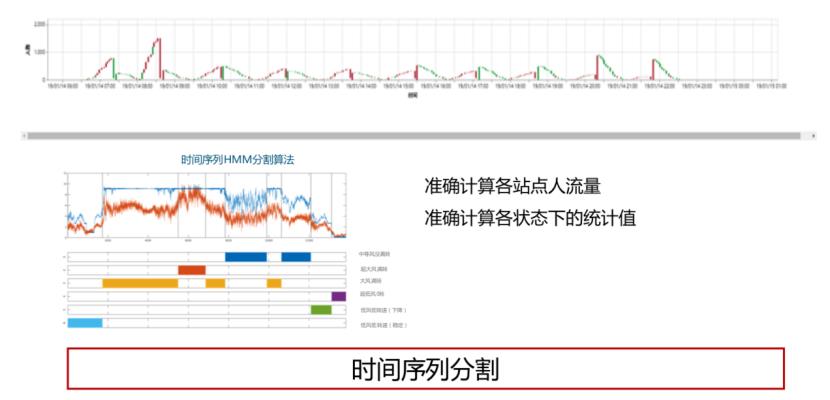
时序数据的分割也是面向时间序列数据的一种典型查询应用。由于某些设备往往是在怠速和带负荷工作两种状态之间频繁切换,而怠速状态下的数据也有可能会被持续采集。这时候若将整条时序数据看做一体,则会对平均值、趋势等分析造成影响,因此将一条时序拆分成若干子序列,是时序数据特有的高级查询。
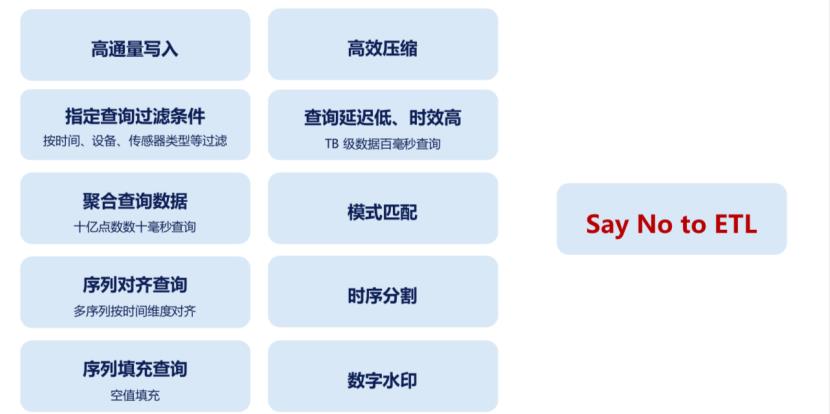
最后,工业应用不仅对时间序列数据的管理提出了高要求,还对时间序列数 据的分析效率提出了需求。由于工业时序数据具有体量大的特点,在分析时将数据从 OLTP 型数据库中经过数据重组织、进而 ETL 到支持 OLAP 的系统或者大数 据计算平台上是一个费时费力的过程。因此,如何实现系统的查询分析一体化,也是亟待解决的问题之一。
现在有很多种数据库可以用于管理时序数据,包括关系数据库和NoSQL数据库和时序数据库,但是他们都存在或多或少的问题。以关系数据库为例,其 schema是有限制的:比如mysql InnoDB中单表的列数上限为1017列,PostGreSQL的列数上限是1400多列。然而,一个设备可能拥有上千个测点甚至上万个测点,一张关系表的列数是不够的。此外,在关系数据库中若单表的行数超过千万量级,性能往往会大幅下滑。因此就需要DBA进行复杂和精细的水平垂直分库分表。带来了使用上的不便。此外,关系数据库的写入性能也远远达不到时序数据的要求。对于以键值为代表的NoSQL数据库而言,其高速的写入性能在一定程度上解决了关系数据库的性能问题,灵活的schema也解决了关系数据库的表行、列数量的限制,但是其能够支持的查询往往没有关系数据库丰富。前文提到的时序数据时间维度的查询、值查询、多序列聚合、多序列时间对齐等查询都存在较大的挑战。TimescaleDB、OpenTSDB、KairosDB等基于关系数据库或NoSQL数据库的系统在一定程度上解决了上述的问题,但难以根本上解决,例如TimescaleDB随着导入时间的增加其导入速度速率会不断地下降。KairosDB在压缩、查询和写入性能上表现都不够突出。一些原生的时序数据库如InfluxDB针对时间序列数据进行了专属的文件结构优化和专属查询优化,然而在一些工业场景下仍然存储无法存储全量数据、性能不足的问题。
综上,我们认为时序数据库应该具有以下功能。
Apache IoTDB时序数据库
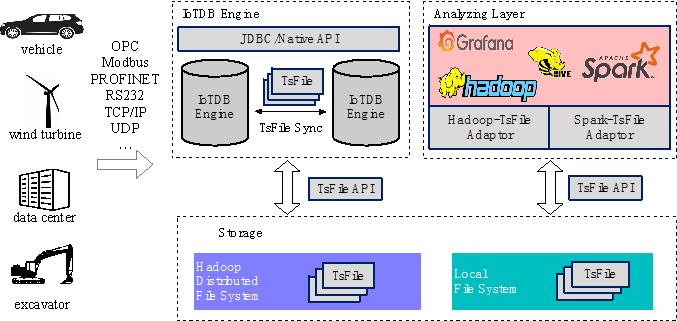
IoTDB具有以下特点:
Committer情况
IoTDB社区的发起人来自于清华大学,由清华大学软件学院王建民教授立项,黄向东等前后三十余名博士生、硕士生一直参与其中进行的初期开发。这些开发者们毕业后继续在清华大学、微软、头条等企业仍然保持着对项目的贡献。
在德国和欧洲地区,在工业4.0的热潮下,IoTDB社区吸引了Julian等许多欧洲开源人士的关注。目前,在PLC4X、Karaf等社区开源贡献者的帮助下,IoTDB已经与这些项目进行了集成,并正在与StreamPipes、Prometheus等项目展开集成。
在国内,阿里等大型IT企业对时序数据库的关注也来越高,IoTDB社区目前与Flink、RocketMQ社区紧密合作,大量这些社区的开发者们同时也是IoTDB社区的贡献者。
国内的主要工业互联网企业,如海尔、联想、东方国信、深信服等,也都纷纷参与到了IoTDB的贡献中。

更多木兰开源社区项目详情,请点击“阅读原文”
以上是关于近距离了解木兰开源社区项目——Apache IoTDB:支持云边端一体化的轻量级高性能时序数据库的主要内容,如果未能解决你的问题,请参考以下文章
超好用的OpenStack管理界面skyline进入木兰社区孵化
IoT+Blockchain开源项目μNEST亮相东京新加坡柏林,完成全球首轮社区见面会