数据挖掘是怎样动脑的?以一篇文献为例
Posted 小张聊科研
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘是怎样动脑的?以一篇文献为例相关的知识,希望对你有一定的参考价值。
大家好,这次白介素2同学分享一篇文献,讲一讲一篇数据挖掘文献是怎样动脑的。文献题为
Insilico analysis reveals a shared immune signature in CASP8-mutated carcinomas with varying correlations to prognosis

发表在 Peer J杂志, IF大约是2分+,,这是2019年2月发表的,时间比较距离现在比较近。通过标题大概知道就是通过生信分析找到CASP8突变的组肿瘤的免疫标记并且与与预后相关。
下面一步步看下作者都做了哪些工作:
一、方法学部分
文章的方法材料比较简单,主要就是包括:
• 差异分析
• GO 和GSEA分析
• 免疫浸润分析
• 生存分析
• 材料:TCGA数据库
二、差异分析
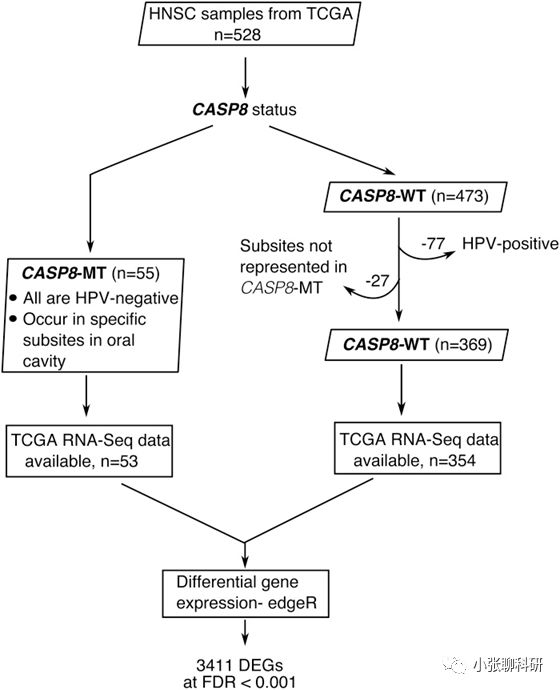
从流程图来看比较简单,就是从TCGA下载头颈部鳞癌的数据,分出突变组和非突变组然后做差异分析。白介素同学认为这里其实已经是一个值得学习的地方了,大家扪心自问下,差异分析是不是除了肿瘤组比正常组就再也想不到其它方式了。作者的这一步操作其实是引入了一个新的变量,就是是否突变的问题。下面看下结果:
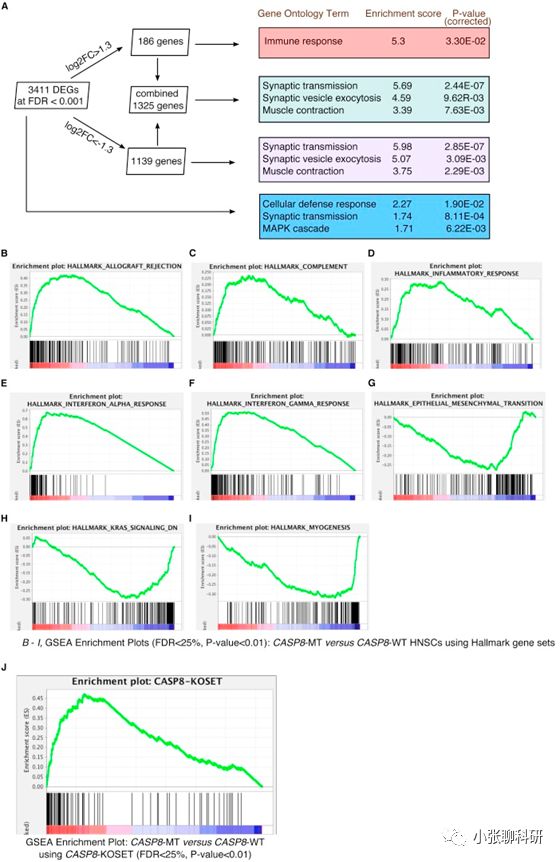
上图展示的就是GO 跟GSEA的部分分析结果,这些就是大概汇报下得到哪些结果。然后选中了免疫反应的基因集,
三、免疫浸润分析
进一步分析免疫浸润,免疫浸润怎么分析呢?此前白介素2同学写过一篇推文,介绍了免疫浸润的数据挖掘工具,(不知道的可以点这里) 。
重要的是,这里作者用的就是白介素同学特别介绍的 TIMER科研神器 https://cistrome.shinyapps.io/timer/,不信你看看图:

四、生存分析
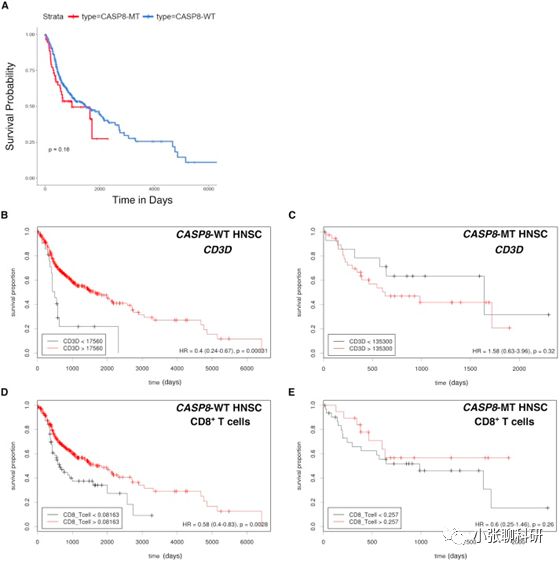
然后就做了一个生存分析,发现是个阴性结果,值得注意的是这里作者用的生存分析又是一个网页工具,叫做Cutoff Finder附个链接给大家:http://molpath.charite.de/cutoff/example.jsp。

按理说这个结果有点尴尬,这个时候作者突然又做了个子宫内膜癌UCEC,作者说这个 CASP8基因在UCEC里面也是突变比较多,相当于这里作者又做了一遍这个UCEC肿瘤,把前面步骤重复一遍,做了个比较。
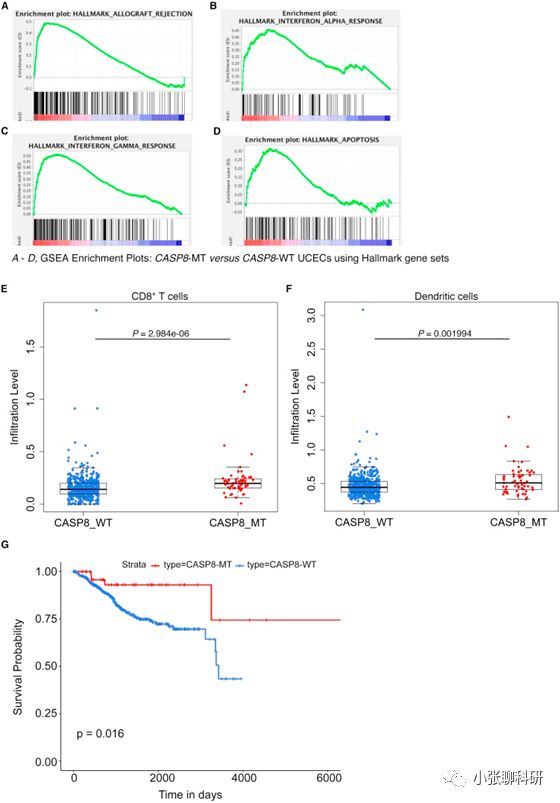
然后就是讨论比较一下,这个基因突变组在两种肿瘤里面的基因富集情况,免疫浸润情况,预后关系。基本上内容就到这里结束了。后面当然会有大段讨论,分析下各种情况嘛,你懂的。
白介素同学特地看了下作者信息,作者印度的,个人觉得倒是有些骨骼惊奇了,至少比那些太庸俗套路要好的多了,作者在分析问题呢。用到的分析技术又不复杂,还充分用的一些网页工具。
五、如何动脑的总结
总结一下,总的来看着篇文章值得学习的地方包括,差异分析的模式,作者引入了新的变量,比常规的肿瘤比正常深入一层了,解答的问题不再是万年不变了。其次,引入了免疫浸润这个热点,操作起来又不难。再者,遇到生存分析的阴性结果,作者又想到了分析另外一种肿瘤,来做比较,提升了文章本身的意义。
这次就分享到这吧,白介素同学祝大家周末愉快。
参考资料:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6375258/#ref-21
长按二维码识别关注“小张聊科研”
关注后获取《科研修炼手册》1、2、3、4、5、6、7,8。
以上是关于数据挖掘是怎样动脑的?以一篇文献为例的主要内容,如果未能解决你的问题,请参考以下文章
课后作业02-2-课程中的所有动手动脑的问题以及课后实验性的问题,整理成一篇文档。