论文基于数据挖掘的医保欺诈预警模型研究
Posted 丁爸 情报分析师的工具箱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文基于数据挖掘的医保欺诈预警模型研究相关的知识,希望对你有一定的参考价值。
摘要:
为识别医疗保险中的欺诈行为,提出了一种基于数据挖掘的医保欺诈预警模型。首先运用ACCESS数据库软件和SQL查询语句,筛选出能运用于医保欺诈行为检测的数据;其次根据医保数据的特点,结合SPSS Modeler软件,采用聚类分析方法和分类决策树算法,建立预测判别模型,识别某位病人在一段时间内是否存在医保欺诈行为;最后通过数据映射关系来找到与嫌疑人有关的嫌疑科室、嫌疑医生等。从而为医疗保险机构的决策者和医保基金运营监管人员进行科学决策提供客观依据,提升社会预测力和科学决策力。
关键词:医保欺诈;SQL查询语句;聚类分析;C5.0决策树
中图分类号:TP311
文献标识码:A
文章编号:1009-3044(2016)11-0001-04
随着近年来参保覆盖面和基金规模的迅速扩大、定点服务机构的大量增加、社会对医疗保险的认知度增强以及信息管理的薄弱,导致了医疗保险欺诈问题日趋严峻。欺诈手段也开始呈现出复杂性与多样性。这些欺诈行为严重损害着广大参保人员的利益,制约医疗保险公平可持续发展。面对日益膨胀的医保基金数额,以及其广泛的影响力,仅靠人工检测已明显不能满足需求。目前,国内医疗保险信息化日渐完善,在医疗保险信息化过程中操作型数据库记录了大量详细的医保相关的交易信息,为数据挖掘的研究与应用提供了广阔的空间。因此通过选取医保数据中的相关属性特征,利用数据挖掘技术进行欺诈行为的识别和预警,建立合理的医保欺诈预警模型,是一项极其重要的研究,能为医保管理决策者提供支持。
1、医保数据的预处理
由于医疗保险数据的来源广泛和涉及内容多,其主要有四大特点:
(1)数据类型多、动态性、数据量大;
(2)存放数据的表繁多且关系复杂;
(3)数据相对完整,空缺值较少;
(4)存在大量不一致和没有价值的数据。
因此,数据预处理是数据挖掘的极其重要的一部分,能剔除大量“脏数据”,提供更为干净、准确、具有针对性的数据。本研究采用的数据主要是某地区一个月的医保数据,包括病人资料、医疗费用明细、医嘱表等6个Excel表格约30余万条记录,数据量符合数据挖掘的要求。
1.1医保数据的清洗
基于课题的研究背景、研究意义和研究方向,并结合6个excel表格,进行数据清洗,删除大量对于本次数据挖掘没有意义的数据。
从这些表中选取的属性数目如表1所示。
1.2医保数据的转换
上面清洗得到的数据表中的数据并不能直接使用,还需要转换为需要的形式,首先将日期一律采用“年-月-日”格式;接着通过出生日期和就诊日期得到患者年龄;最后将医嘱ID号精简成数字型。
1.3医保数据的集成
由于数据分别储存在数据库的几个表中,因此需要将相关的表通过SQL查询语句进行连接,生成一个初步的集成表“医保数据表”。但是该表格的属性繁多,冗余较大,还需进一步的处理。下面这些情况都有可能是医保欺诈:单张处方药费偏高,就医次数偏多,多人合伙进行欺诈等。因此,可计算病人就诊时的单次账单费用、每一个病人所看病的总消费额和就医次数。生成两个新的表格分别为“账单费用表”和“综合费用表”。
2、医保欺诈模型的建立与求解
2.1参保人骗保行为识别
根据相关知识和文献可知,对参保人骗保行为的识别主要通过以下两种情况:
一是单次处方费用偏高的识别;
二是就医次数偏多的识别。然后结合医保数据的特点,本模型将采用聚类的方法对问题进行研究。具体的研究流程图如图1。
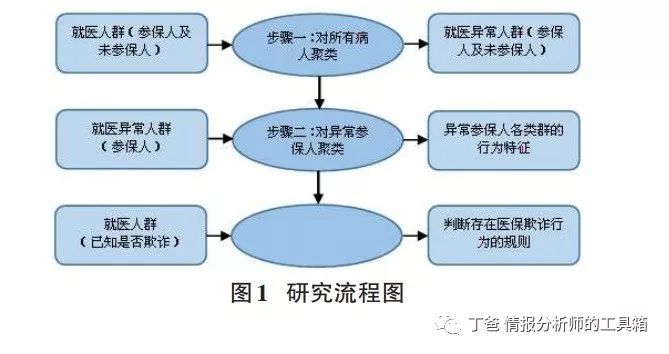
1)对所有病人聚类——Modeler的异常诊断方法
根据病人的就医特征,从“医保数据表”中选取病人ID号、医保手册号、年龄、性别、就医费用、就医次数6个相关属性,构建异常检测聚类模型,对就医人群进行聚类,判别出各类的异常点,从而找出就医行为存在异常的参保人,即Modeler的异常诊断方法。
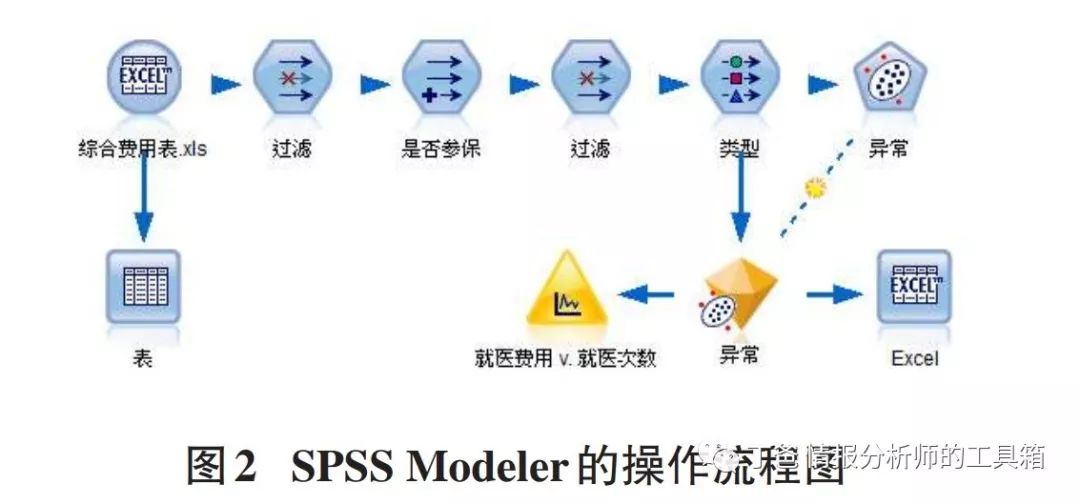
①SPSSModeler的操作过程先将医保数据表导入到SPSSModeler中,并将除病人ID号、医保手册号、年龄、性别、就医费用、就医次数外的字段过滤掉;接着从表中的医保手册号这个字段中可看出,有一部分人在医院的记录中使用了医保卡,而一部分人没有使用,具体表现为:未使用医保卡的人医保手册号为1,因此将“医保手册号”属性转换成“是否参保”属性,且将该“医保手册号”属性过滤;然后选择字段类型;最后利用Modeler的异常诊断方法,构建异常检测聚类模型,找出就医行为存在异常值。并设定训练集中异常的记录百分比为5%,SPSSModeler的具体操作过程如下图2。
② 运行结果如表2
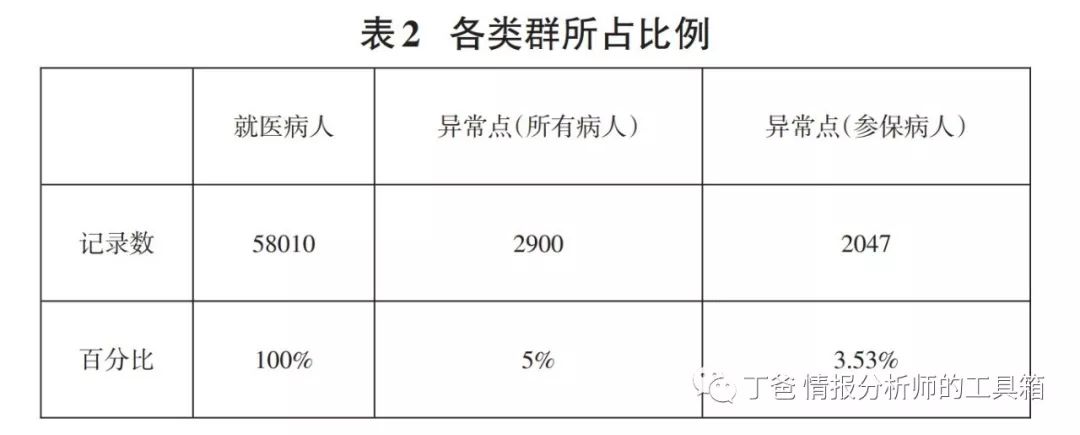
通过表5可以筛选出就医行为存在异常的病人,并将研究的对象从58010名病人缩小到2047名异常的参保病人。为了方便之后的研究,在医保数据库的综合费用表中新增一列“异常情况”,并导入“异常情况”这一属性,得到“新综合费用表”,通过该表,就可以很容易的查找出就医行为存在异常的参保病人。
2)对异常参保人聚类——Modeler的K-means聚类
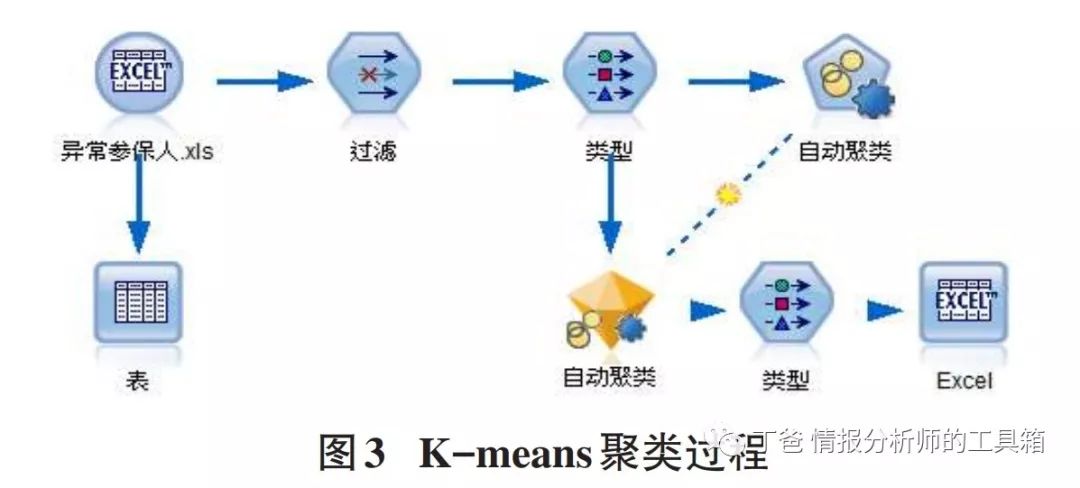
通过步骤一的Modeler异常诊断方法,可以得到异常参保人有829人,但这并不代表就医行为存在异常的参保病人都会进行医保欺诈,因此本文将对这些异常参保病人进行K-means聚类分析,找出不同类群的异常就医行为的病人行为特征,并定义医保欺诈手段,从而识别出存在医疗保险欺诈的类群,再从中找出可能存在医保欺诈的参保人员。
①SPSSModeler的操作过程
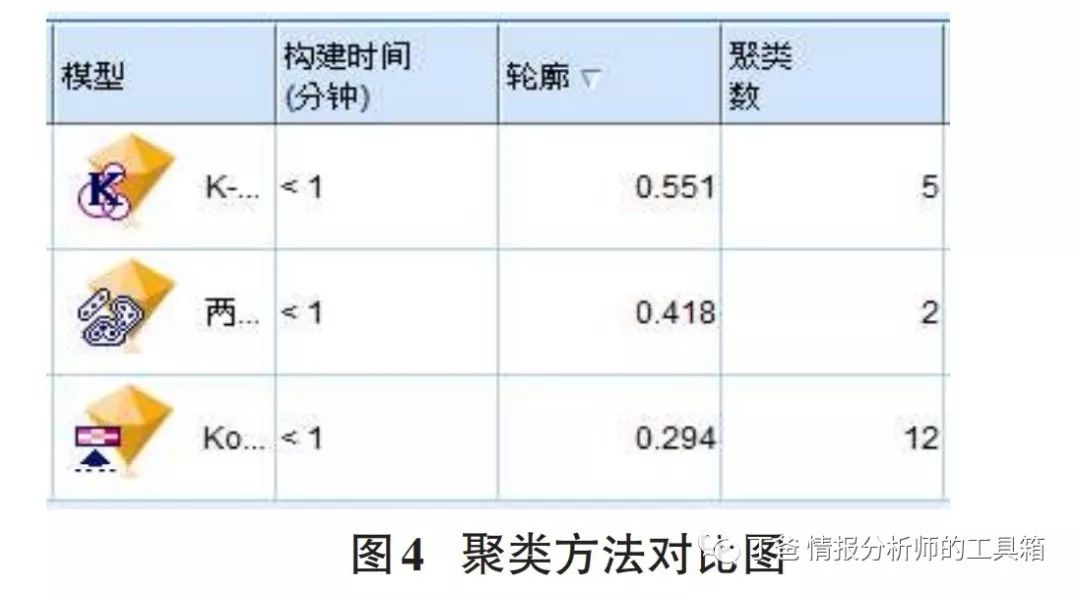
首先由于利用Modeler的K-means聚类方法时,首先需要给出聚类的类数,但是聚类的类数难以确定,因此选择Modeler的自动聚类方法。Modeler的自动聚类方法主要是Kohonen聚类、两步聚类、K-means聚类,综合本文实际情况、数据的特点以及聚类的质量,对比情况如图4所示。因此最终选择K-means聚类方法,从而找出不同类群的异常就医行为的病人行为特征。
② 运行结果
聚类结果显示:聚类数为5类时最为适合,且聚类质量较好,操作结果如表3所示。
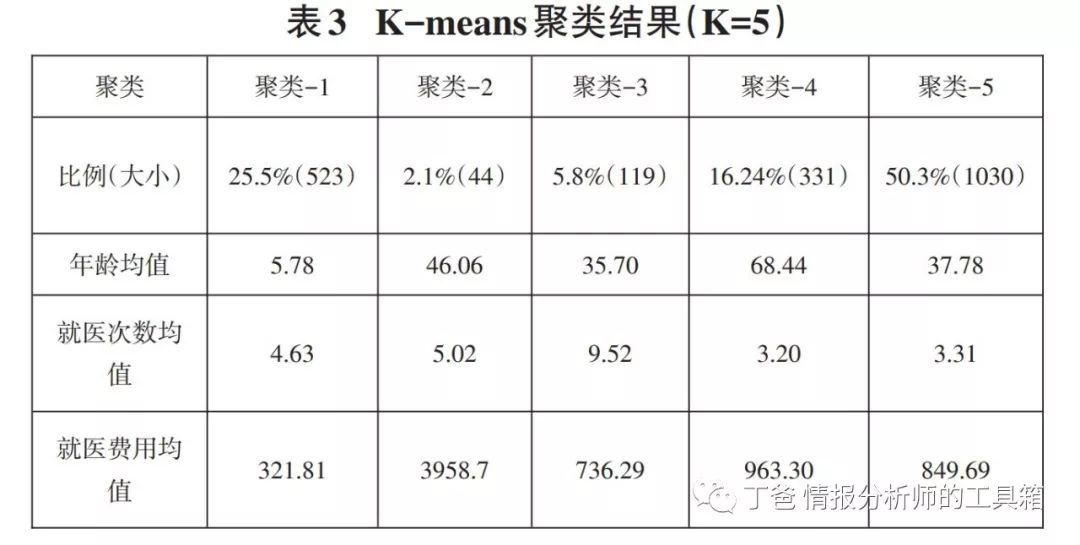
根据表3聚类结果可以初步得知:
对于聚类-1,该类参保异常人平均年龄为5.78,属于少年群体,平均就医次数6次,平均单次就医费用69.5元,此费用较低,属于正常范围,这与少年本身身体素质有关,治疗费用并不需要太高,因此认为这类人群不存在医保欺诈的行为;
对于聚类-2,该类参保异常人的平均年龄为46.06,属于中年群体,平均就医次数5次左右,平均单次就医费用达到788.6元,与正常就医行为特征相差十分大,因此认为该类人群存在医保欺诈的行为;
对于聚类-3,该类参保异常人的平均年龄为35.70,也属于青年群体,虽然平均单次就医费用仅77.34元,但其平均就医次数达到9.52,由于就医频次过高,因此认为该类人群存在医保欺诈的行为;
对于聚类-4,该类参保异常人的平均年龄为68.44,已属于老年群体,该类人群平均就医次数3.42,平均单次就医费用301.03;就医费用较高,这与老年人体弱多病有关,一旦患病则需要较长的治疗周期,因此本文认为该类人群不存在医保欺诈的行为;
对于聚类-5,该类参保异常人的平均年龄为37.78,属于青年群体,该类人群平均就医次数3.31,平均单次就医费用256.7元;可认为该类人群不存在医保欺诈的行为。
根据以上的聚类结果和对各类人群的就医行为特征进行归纳分析,可发现,参保人就医行为存在异常的病人中有医保欺诈行为的仅163人,占参保异常人总数的7.96%,符合实际情况。
本文将要探讨的医保欺诈行为定义为以下三类:
a.参保人频繁到医院就医,超量购药,导致就医次数偏高和就医费用偏高;
b.若干参保人同一时间到医院频繁刷卡,开取昂贵药,且开取的药物药效相似。
c.参保人购买的药物类型与所属的年龄段不相符;
3)建立预测决策树模型——Modeler的C5.0决策树
根据步骤一、二,已识别出存在医保欺诈行为的病人。因此,通过结合存在医保欺诈行为病人的就医行为和不存在医保欺诈行为病人的就医行为特征,运用C5.0决策树算法,建立了一个识别某位病人在一段时间内是否存在医保欺诈行为的判别分类模型。
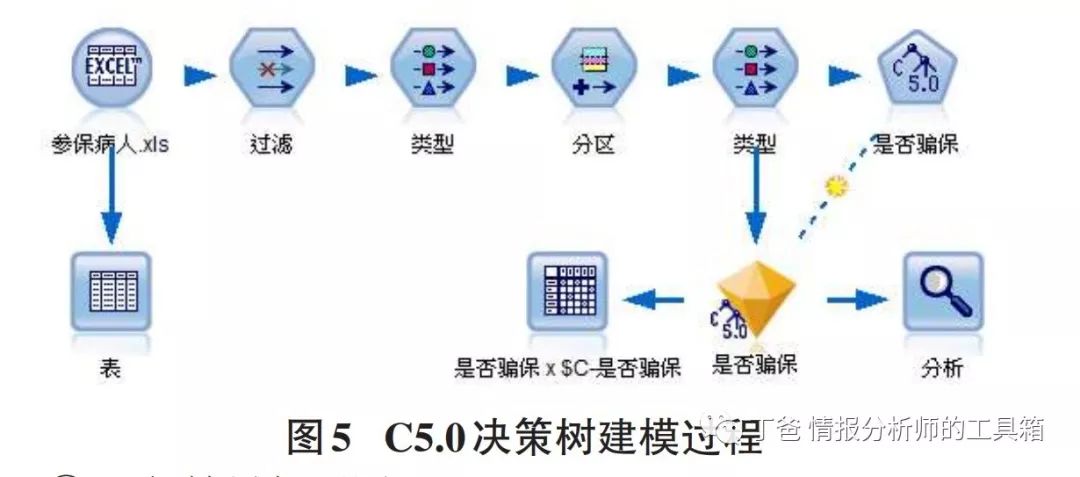
①SPSSModeler的操作过程首先通过筛选建立参保病人表,确定决策树的输入变量为就医次数、就医费用以及年龄,输出变量为“是否骗保”,其中将存在医保欺诈的病人变量赋值为1,其余病人赋值为0;然后,将所有的样本随机划分为两个数据集,其中70%的参保病人作为决策树的训练集,用于进行决策树的训练,30%的参保病人作为决策树的测试集,用于检验决策树的正确率。具体的操作步骤如图5。
② 运行结果如下图6。

根据图6所示,可以得到以下几条判断某位参保人在一个月内存在医保欺诈行为的5条规则:
A.如果就医次数>10,则存在医保欺诈行为;
B.如果就医次数>8并且年龄>55,则存在医保欺诈行为;
C.如果就医次数>7并且55>=年龄>15,则存在医保欺诈行为;
D.如果就医费用>2097.38并且57>=年龄>32,则存在医保欺诈行为;
E.如果就医费用>3305.02,则存在医保欺诈行为。
为验证建模结果的准确性,通过对模型添加矩阵节点和分析节点,可以得到模型的准确率和损失率。结果见如表3和表4。
通过表4可知:在训练集里该决策树的准确率高达100%,在测试集里准确率也高达99.94%,准确率极高。再通过表8的损失矩阵中可知:本来不存在医保欺诈行为但是被该决策树误判为存在医保欺诈行为的人数仅有1人;本来存在医保欺诈行为但是被该决策树误判为不存在医保欺诈行为的人数也只有5人。因此,该模型的准确率是非常高的,存在医保欺诈行为的人数仅有163人,则该决策树的适用范围还是比较小的,具有可信度。
2.2数据映射查找相关欺诈信息
通过对参保人骗保行为进行识别,找出了参保病人中可能进行医保欺诈行为的病人。由医保欺诈的欺诈对象来看,欺诈除了参保人还有医生。因此,将继续根据骗保人信息表的数据映射关系来找到与嫌疑人员有关的嫌疑科室、嫌疑医生以及高频医嘱子类、核算分类。从而可以确定协助作案的科室医生以及医保诈骗事故高发的医嘱项、医嘱子类以及核算类,便于以后的重点监督和排查。
1)查找嫌疑科室
根据医保欺诈的欺诈方式来看,在某些情况下,科室可以通过伪造病历、票据医保等方式欺诈,以骗取医保资金。显然,通过这种操作方式会造成某些患者费用和频率较高。因此,可以通过骗保人信息表筛选出与嫌疑参保人有关的科室,并且统计他们与嫌疑参保人进行操作的次数。本研究将采用医保手册号来统计下医嘱科室与嫌疑参保人进行操作的次数。
最终由条形图可知,前5个科室的交易次数明显高于其他科室,并且和与其相邻的科室样本突然发生较大变化,因此将下医嘱科室为173、124、133、203、143的认为是嫌疑科室。
2)查找嫌疑医生与嫌疑科室
同理,嫌疑医生可以通过伪造病历、票据医保等方式通过欺诈,以骗取医保资金。因此根据同样的方法查询出嫌疑医生,条形图显示,前2个医生的交易次数明显高于其他医生,并且和与其相邻的科室样本突然发生较大变化,因此将开嘱医生ID号为1180、794的认为是嫌疑医生。
3)查找高频医疗作案项目
医保欺诈通常选择效率高、收益高、周期短的医疗项目作为作案目标,因此可以通过查找记录中高频医嘱项、高频医嘱子类、高频核算分类来确认医保欺诈高发的作案项目。为更直观地看到各高频类在项目中所占的比例,将绘制成饼图来统计。
由饼图结果可以将医嘱项为6886、16428、5462等前十名,医嘱子类ID号为6、1、23,核算分类ID号为1的三个高频项目认为是参保人极易选择的作案项目,其内容具体意义为医嘱项:89SrCL2注射液[4mci]、重组人红细胞生成素[5000IU/瓶]、0.9%氯化钠注射液(直软)[100ml]等,医嘱子类:针剂、口服药、成药口服,核算分类:西药费。对于这几种效率高、收益高、周期短的医疗项目要重点监督,防止医保欺诈。
3、研究结论
本文的研究结果表明:基于聚类分析和决策树的数据挖掘方法对医保欺诈行为能够进行较为准确的预警,无论是学习还是最后实践的识别准确率都达到了99%,可信度强。这种预警方法可以大大减少人工检测,提高识别效率,为医疗保险机构的决策者和医保基金运营监管人员进行科学决策提供客观依据,提升社会预测力和科学决策力。但在取得一些研究成果的同时,还存在一些不足:
1)本研究所使用的费用相关数据都是只与药物消费有关,因此研究的医保欺诈行为也只局限在与药物方面异常的有关情况,这使医保欺诈主动发现的模型缺乏普遍性;
2)在建立决策树模型时,只利用到数据库中的几个相关属性,具有局限性。若再进一步研究,可以将更多的信息用于建立决策树模型,使得模型更具有普遍性;
3)由于数据中没有给出病人是否存在医保欺诈的属性指标,因此对模型的检验存在一定的缺陷。
参考文献:
[1]甘枥元.基于数据挖掘医保系统的研究[J].信息安全与技术,2013(10):67-68.
[2]陈真,秦伟,徐绪堪,房道伟.大数据环境下医保数据监测和预警模型构建[J].现代商业,2014(20):101-102.
[3]朱攀.基于人工神经网络的医保定点医疗机构信用等级评价模型[D].国防科学技术大学,2010.
[4]高宇彤.基于离群点检测的新农合医保欺诈识别的研究[D].哈尔滨商业大学,2015.
[5]楼磊磊.医疗保险数据异常行为检测算法和系统[D].浙江大学,2015.
[6]沈培,张吉凯.聚类分析在医疗费用数据挖掘中的应用[J].华南预防医学,2012(1).
[7]冯丽芸.数据挖掘在我国医保方面应用综述[J].电脑知识与技术,2014(05):880-881.
[8]孙晶晶,魏俊丽,万昊,赵冠宏.数据信息在医院医疗保险管理中的应用[J].中国医院,2015(12).
[9]刘江超.数据挖掘算法在医保数据上的应用研究[D].国防科学技术大学硕士论文,2009(11).
[10]薛薇.基于SPSSModeler的数据挖掘[M].北京:中国人民大学出版社,2014.
文章来源:《电脑知识与技术》第12卷第11期 (2016年4月) 数据库与信息管理
基金项目:本项目受国家级大学生创新创业训练计划项目(201510876019) 资助。
以上是关于论文基于数据挖掘的医保欺诈预警模型研究的主要内容,如果未能解决你的问题,请参考以下文章
论文研读1.1 基于 DeepFM 模型的广告推荐系统研究(郁等)