如何基于Raft绕过分布式算法一致性的那些痛?(有彩蛋)
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何基于Raft绕过分布式算法一致性的那些痛?(有彩蛋)相关的知识,希望对你有一定的参考价值。
本文根据DCOS联盟第6期线上分享整理而成,文末还有书送哦~

姚云
数人云研发工程师
目前负责Go语言分布式系统的相关研发,Linux社区成员,擅长Python,熟悉C#开发。
主题大纲:
1、点拨分布式系统和Raft算法要点
2、深入剖析Raft实现原理
3、干货:基于Raft的分布式系统实战经验
最近我们开源了一个运行在Mesos上的分布式调度器swan(https://github.com/Dataman-Cloud/swan),在研发过程中发现由于目前的分布式存储并不能满足我们所有需求,所以自己动手将Raft嵌入到swan中,以保证多节点之间的数据同步。在这个过程中我们积累了一些Raft相关的经验和教训,在这里与大家分享。
一、关于分布式系统
分布式系统具有可扩展性和高可用性强等特点,被越来越多的应用到各个应用场景中,但是在分布式系统中,各个服务器之间数据的一致性一直是无法绕过的难题。
所谓一致性,它是指分布式系统中,多个服务器的状态达成一致。但由于各种意外可能,某个服务器发生崩溃或变得不可靠,它就不能与其他服务器达成一致性状态。这样就需要一种Consensus协议,这个协议是为了确保容错性,也就是即使系统中有一两个服务器宕机,也不会影响其他的服务器正常提供服务。
在过去Paxos一直是分布式协议的标准,但是Paxos难于理解,更难以实现。较于Paxos,来自Stanford的新的分布式协议Raft更好用一些,它是一个为真实世界应用建立的协议,主要注重协议的可理解性和落地。
二、Raft如何在多个服务器之间实现数据的一致性
下面简单介绍一下Raft如何在多个服务器之间保证数据的一致性。为了达成一致性这个目标,首先Raft需要进行选举,在Raft中,任何时候一个服务器可以扮演下面角色之一:
Leader:处理所有客户端交互,日志复制等,一般一次只有一个Leader;
Follower:类似选民,完全被动;
Candidate候选人:类似Proposer律师,可以被选为一个新的领导人。参选者需要说服大多数选民(服务器)投票给他。
选举的过程大概分为以下几步:
任何一个服务器都可以成为一个候选者Candidate,它向其他服务器Follower发出要求选举自己的请求;
其他服务器同意了,发出OK。注意如果在这个过程中,有一个Follower宕机,没有收到请求选举的要求,候选者可以自己选自己,只要达到N/2 + 1 的大多数票,候选人还是可以成为Leader的;
因此该候选者就成为了Leader领导人,它可以向选民也就是Follower们发出指令,比如进行日志复制;
如果一旦Leader宕机崩溃了,那么Follower中会有一个成为候选者,发出选举邀请;
Follower同意后,其成为Leader;
选出leader之后,所有的操作都需要在leader上进行,leader把所有的操作下发到集群中的其他服务器(follower),follower收到消息,完成操作commit之后需要向leader汇报状态;如果leader处于不可用的状态,则需要重新进行选举。
为了与容错方式达成一致性,Raft不要求所有的服务器100%达成一致,只要超过半数的服务器达成一致就可以了,假设有N台服务器,N/2+1超过半数,也就是说一个3节点的Raft集群允许一个节点宕机,一个5节点的Raft集群可以允许2个节点宕机,所以为了更有效的利用服务器,一般Raft集群里服务器的数量都是奇数,建议配置运行3或5节点的Raft集群, 最大限度的提高可用性, 而且不会牺牲很多性能。
三、实践:如何自己动手写一个内置Raft集群的分布式服务
下面结合swan中的具体代码,介绍如何启动RaftNode,以及处理数据和有关Raft状态的相关实践,swan的分布式存储的设计草图如下:
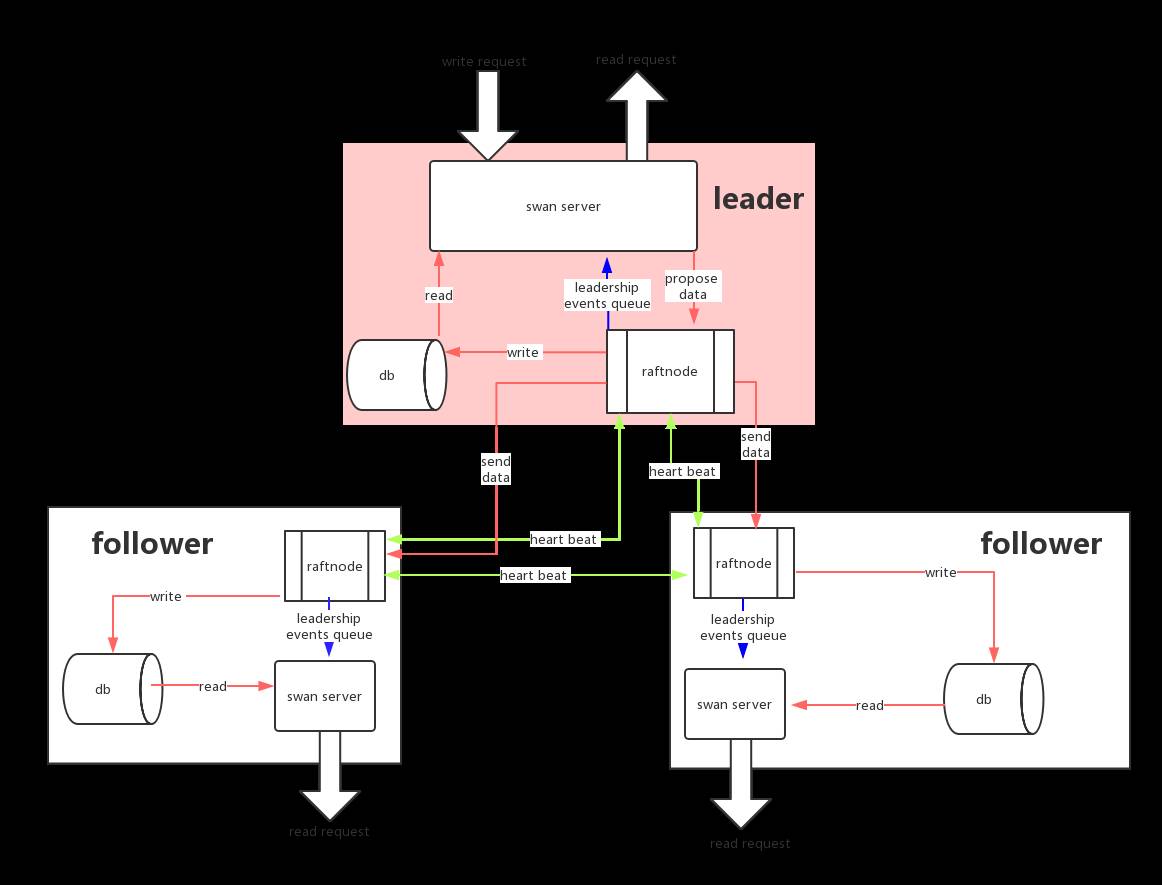
如何启动一个RaftNode
先分享下如何自己动手写一个内置Raft集群的分布式服务,由于是使用Go语言开发,所以选用etcd/raft。
在Raft集群中最重要的概念就是一个RaftNode,多个互相连通的RaftNode组成了一个RaftCluster,可以通过以下代码快速启动/重启一个RaftNode。

该方法是在RaftNode启动时已经知道集群未来的规模,将集群的其他节点ID写入到配置中,如果要实现节点的Auto Join,则需要在Start的Peers参数处传入空值;另外,如果服务之前已经运行了一段时间,在启动服务时就需要从WAL中读取上一次服务停止时的状态和数据,然后在这些数据的基础上继续运行。
RaftNode启动成功后,各个节点之间的通信需要借助一个Transport,同样还是使用etcd提供的httptransport ,当然,也可以基于grpc实现所有的通信方法(参考swarmkit的实现),以下是启动transport的代码实现。

至此,一个简单的RaftNode就算启动起来了,依据同样的方式再启动其他两个节点,3节点的RaftCluster也运行起来了,不过,只是服务启动成功还远远不够。
数据提交及事件处理
1、 将数据提交到RaftNode,使用Propose方法将数据提交到leader节点
注:只能讲数据Propose到leader节点, 因为只有leader才有能力让follower复制自己的操作。
2、leader节点接收到数据会根据集群的状态判断是否已经能接受数据的提交,leader确定能接收数据后会负责将数据发送到follower。
注:如果是集群节点的改动需要调用ProposeConfChange方法。
3、RaftNode节点数据提交是一个异步的过程,通过Propose方法往RaftNode中提交数据,而RaftNode则在经过一系列的状态判断从另一个线程中通过 Ready()方法通知,此外,集群状态的变化也会通过这个channel来通知,所以当Propose数据之后不知道数据是否提交成功,如果服务的数据有高可用性的要求,这里可能需要进行额外的处理,将异步的提交变成同步的(可以参考swarmkit ProposeValue)。
注:由于数据提交只有一个Propose接口,所以需要对不同的数据进行不同的操作,提前定义好对哪些数据(比如app, cluster)进行什么样的操作(比如Add, Update, Delete),这种情况下就要先在Propose的对象里加上数据和操作之后再进行序列化。
着重注意从 Ready()中收到数据之后的处理,先看代码:

以上代码可以看到最主要的三个处理:
检查RaftCluster的状态是否已经改变,如果该节点已经从follower升级成为leader,需要通知外部的服务这个变化,以便外部服务做出相应的调整
publishEntries,其实就是讲rd。CommittedEntries持久化或者存到相应的地方,可以认为这些CommittedEntries就是已经被RaftCluster接收了的可靠消息。
关于节点状态的变化,需要在外部服务中监听RaftNode的leadershipChange event,由于RaftNode只有在leader上才能Propose数据(相当于写操作),所以cluster中的所有节点地位并不是对等的,比如有的提交数据的功能可能需要等RaftCluster leader election完成后再leader上启动;至于其他的follower节点如果对外想提供和leader一样的服务,则需要自己实现一个proxy,将请求proxy到leader节点, 或者通过grpc来远程调用leader上相应的接口,相关的代码如下所示:
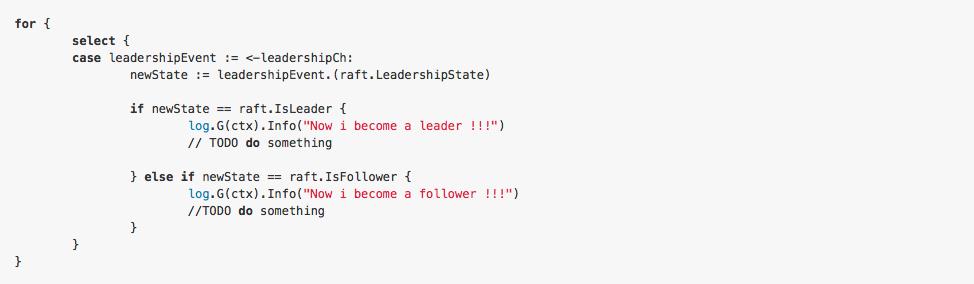
3、以上关于接受Ready()消息的处理代码中,除了之前提到的两点外,剩下的就是关于WAL(Write Ahead Logging 预写式日志多用于实现数据库原子性事务)和snapshot的相关处理了。
通过代码看到Ready()里收到的每一条消息都会先调用wal。Save,由wal。Save将相关的信息保存到WAL中,当操作积累到一定的数量时,则会通过saveSnapshot将目前的全量数据(包括状态和已经接受到的所有数据)保存到snapshot中, 然后调用wal。ReleaseLockTo释放掉已经存入snapshot中的操作。
这点与许多数据库实现的WAL原理( WAL机制的原理,是修改并不写入到数据库文件中,而是写入到另外一个称为WAL的文件中;如果事务失败,WAL中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改)是一样的。
注:最后别忘了调用RaftNode。Advance()。
关于日志压缩
之前提到WAL会将RaftNode的每次操作记录下来,而且在RaftCluster中leader不删除日志,仅追加日志,因此随着系统的持续运行,WAL中内容越来越多,导致日志重放时间增长,系统可用性下降。快照(Snapshot)是用于“日志压缩”最常见的手段,Raft也不例外。
具体做法如下所示(图片来自网络):
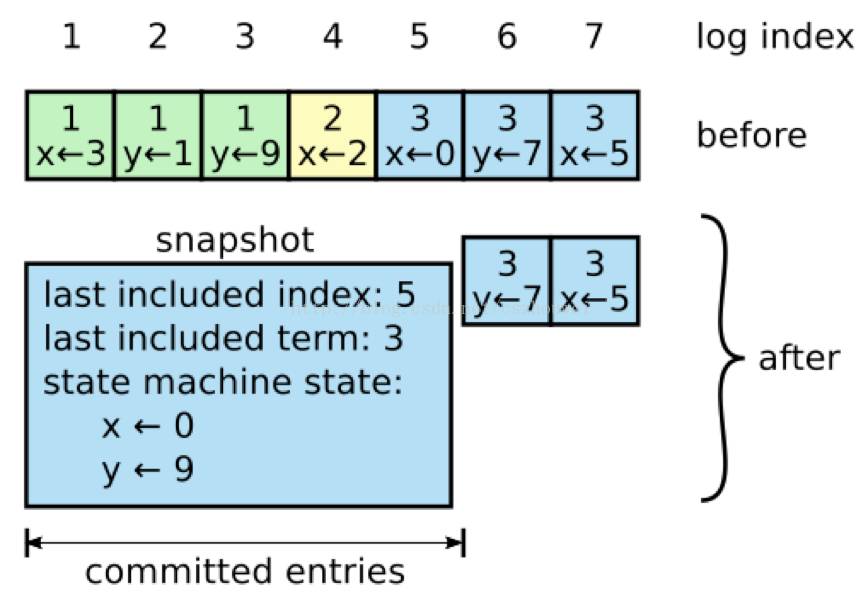
与Raft其它操作Leader-Based不同,snapshot是由各个节点独立生成的。除了日志压缩的功能,snapshot还可以用于同步状态。
四、总结
以上仅仅只是跑起来一个简单的RaftCluster,关于服务怎么和嵌入的RaftCluster结合,以及leader切换,节点的增删等等还是有不少的问题等着我们一起去探讨和解决。有关Raft的更多资料可以参考:
Raft动画演示
http://thesecretlivesofdata.com/raft/
Raft论文
https://ramcloud.stanford.edu/wiki/download/attachments/11370504/raft.pdf
Q1:抛砖引玉问一下,swankit 的典型部署是跨数据中心部署吗?如果是的话,raft 的心跳时间你们的经验值是? 在网络抖动的情况下,如何避免 follower 频繁发起新 Term 的选举?
A1:由于目前我们的项目还没有大规模的应用到生产所以心跳和选举的间隔参考的swarmkit和etcd分别设置的1秒和10秒。目前我们的实现方式是不支持跨数据中心的部署的。至于如何避免follower频繁发起新的term选举目前还只有设置选举间隔这一条了。
Q2:Raft和Multi-Paxos的区别?
A2:Raft可以说是从Paxos 中发展出来的,答:简单来说就是 Raft 在理解和实现都要比 Multi Paxos 要简单,主要体现在两阶段的限制。Paxos 出现的太早了,严格的证明,非常的学术,有兴趣的可以去看 Lamport 老的论文,包括最早那篇和 make simple,make live。我也不敢说理解透彻,只是了解到谷歌的 Chubby 是基于Multi Paxos 实现的。至于实践上的区别可以参考http://bingotree.cn/?p=614。
Q3:第一张图里,显示了3个raft节点,一个leader,两个follower,那律师节点是随机的么?另外,图中显示,心跳是两两节点完成的,而不是用连到一个交换机,这种方式会不会有什么问题?
A3:由于在Raft节点中任何一个节点都可以成为候选者向其他节点请求投票所以需要 两两之间互相通信, 所以如果不是连到同一交换机导致节点之间无法互相通信是有问题的。
Q4:请问这次采用了哪个raft的开源实现?还是自己实现了raft协议?
A4:用的是 coreos 的 etcd/raft 库 https://github.com/coreos/etcd/tree/master/raft。
好书相送
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,并在本文发布后32小时之内成为点赞数最多的一名,可获得以下书籍一本~
特别鸣谢清华大学出版社为本次活动提供图书赞助。
◆ 近期热文 ◆
◆ MVP专栏 ◆
丨丨丨丨
丨丨丨丨
以上是关于如何基于Raft绕过分布式算法一致性的那些痛?(有彩蛋)的主要内容,如果未能解决你的问题,请参考以下文章