浅谈分布式一致性算法raft
Posted 架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈分布式一致性算法raft相关的知识,希望对你有一定的参考价值。
本篇博客的目录:
一:raft的状态
二:选主过程
三:如何保证集群一致性
四:如何处理脑裂问题
五:总结
一:raft的状态
①:follower
②:candidate
③:leader
任期:
下面是几种角色的流转图:
二:raft的选主
2.1:leader负责处理客户端的请求
所有对日志的添加或者状态变化的操作都是通过leader来完成,当leader接收请求之后会将日志分发到集群的所有follower节点,日志的数据流是从leader到其他的节点,而不会产生follower流向日志的情况,raft会保证流向所有follower节点的日志副本都是一致的:
选举leader发生在以下两种情况:
①当一个raft集群初始化的时候 ②当选举出来的主节点宕机、崩溃的时候
2.2:接下来谈一谈raft是如何选主的:
Raft集群开始,集群中的节点所有的初始状态都是
Follower,然后设置任期(term为0),并启动计时器发起选举(Election),开始选举之后每个参与方都会有一个随机的超时时间(
Election Timeout),这里的关键就是随机 T
imeout(150ms 到 300ms之间
),最先走完
timeout时间的一个节点开始发起投票,向还在
timeout 中的另外节点请求投票(Reuest Vote)并等待回复,此时它就只能投给自己,然后raft会统计得票数,在计数器时间内,得票最多的会成为leader.这样的结果就是最先发起投票的节点会有大概率成为主节点,选出
Leader 后,term值会+1,并且
Leader通过定期向所有
Follower 发送心跳信息(官方称之为:Append Entries,Append Entries是一种RPC协议)保持连接。

两个节点同时发起选举
2.3:当选举完成之后考虑以下几个情形:
情形一:leader宕机
Leader的心跳,follower会认为
Leader 可能已经挂了,此时第一个超时的follower会发起投票,注意这个时候它依然会向宕机的原leader发出Reuest Vote,但原leader不会回复。raft设计的
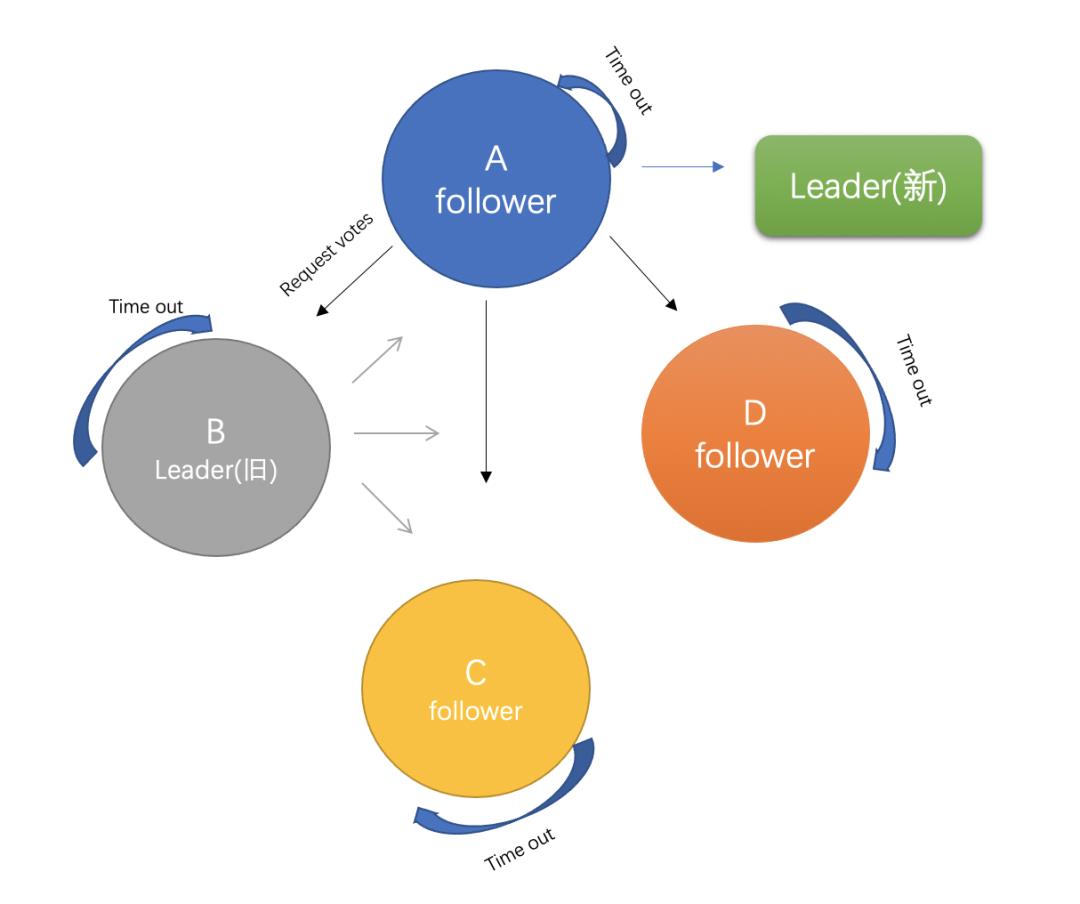
ps:后期leader恢复正常之后,加入到raft集群,初始化的角色是follower,而并非leader。因为任何时刻leader只有一个,如果是两个,就会发生"脑裂"问题
情形二:follower宕机
三:raft如何保证集群的一致性
3.1:Raft 协议由leader节点负责接收客户端的请求,leader会将请求包装成log entry分发到从节点,所以集群强依赖 Leader节点的可用性,以确保集群 数据的一致性。数据的流向只能从 Leader 节点向 Follower 节点转移,这个过程叫做日志复制(Log Replication):
① 当 Client 向集群 Leader 节点 提交数据 后,Leader 节点 接收到的数据 处于 未提交状态(Uncommitted)。
② 接着 Leader 节点会并发地向所有Follower节点复制数据并等待接收响应ACK
③ leader会等待集群中至少超过一半的节点已接收到数据后, Leader 再向 Client 确认数据 已接收。
④ 一旦向 Client 发出数据接收 Ack 响应后,表明此时 数据状态 进入 已提交(Committed),Leader 节点再向 Follower 节点发通知告知该数据状态已提交
⑤ follower开始commit自己的数据,此时raft集群达到主节点和从节点的一致
 3.2:在进行一致性复制的过程中,假如出现了异常情况,raft都是如何处理的呢?
3.2:在进行一致性复制的过程中,假如出现了异常情况,raft都是如何处理的呢?
1.数据到达 Leader 节点前,这个阶段 Leader 挂掉不影响一致性
2.数据到达 Leader 节点,但未复制到 Follower 节点。这个阶段 Leader 挂掉,数据属于 未提交状态,Client 不会收到 Ack 会认为 超时失败 可安全发起 重试。
3.数据到达 Leader 节点,成功复制到 Follower 所有节点,但 Follower 还未向 Leader 响应接收。这个阶段 Leader 挂掉,虽然数据在 Follower 节点处于 未提交状态(Uncommitted),但是 保持一致 的。重新选出 Leader 后可完成 数据提交。
4.数据到达 Leader 节点,成功复制到 Follower 的部分节点,但这部分 Follower 节点还未向 Leader 响应接收。这个阶段 Leader 挂掉,数据在 Follower 节点处于 未提交状态(Uncommitted)且 不一致。
Raft 协议要求投票只能投给拥有 最新数据 的节点。所以拥有最新数据的节点会被选为 Leader,然后再 强制同步数据 到其他 Follower,保证 数据不会丢失并 最终一致。
5.数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在 Leader 处于已提交状态,但在 Follower 处于未提交状态。
这个阶段 Leader 挂掉,重新选出 新的 Leader 后的处理流程和阶段 3 一样。
6.数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在所有节点都处于已提交状态,但还未响应 Client。这个阶段 Leader 挂掉,集群内部数据其实已经是 一致的,Client 重复重试基于幂等策略对 一致性无影响。
四:如何解决脑裂问题
当raft在集群中遇见网络分区的时候,集群就会因此而相隔开,在不同的网络分区里会因为无法接收到原来的leader发出的心跳而超时选主,这样就会造成多leader现象,见下图:在网络分区1和网络分区2中,出现了两个leaderA和D,假设此时要更新分区2的值,因为分区2无法得到集群中的大多数节点的ACK,会复制失败。而网络分区1会成功,因为分区1中的节点更多,leaderA能得到大多数回应
当网络恢复的时候,集群不再是双分区,raft会有如下操作:
①: leaderD发现自己的Term小于LeaderA,会自动下台(step down)成为follower,leaderA保持不变依旧是集群中的主leader角色
②: 分区中的所有节点会回滚roll back自己的数据日志,并匹配新leader的log日志,然后实现同步提交更新自身的值。通知旧leaderA也会主动匹配主leader节点的最新值,并加入到follower中
③: 最终集群达到整体一致,集群存在唯一leader(节点A)
五:总结
·END·
来源:www.cnblogs.com/wyq178/p/13899534.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
我们都是架构师!
关注架构师(JiaGouX),添加“星标”
获取每天技术干货,一起成为牛逼架构师
技术群请加若飞:1321113940 进架构师群
投稿、合作、版权等邮箱:admin@137x.com
以上是关于浅谈分布式一致性算法raft的主要内容,如果未能解决你的问题,请参考以下文章