分布式-Raft协议的理解与分析
Posted 架构之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式-Raft协议的理解与分析相关的知识,希望对你有一定的参考价值。
Paxos是最早的分布式一致性算法,虽然出来了很多年,但因其不容易理解,且实现难度较大,目前比较成熟的Multi-Paxos实现依然比较少。Raft算法是近几年很火的一个分布式一致性算法,旨在提供分布式一致性的前提下,提高算法的可读性,降低实现的难度。它提供了和Paxos算法相同的功能和性能,但是它的算法结构和 Paxos不同,使得 Raft算法更加容易理解并且更容易构建实际的系统。为了提升可理解性,Raft将一致性算法分解成了几个关键模块,例如领导人选举、日志复制和安全性。
一、相关介绍
Raft集群服务器的状态有三种:领导人 (Leader)、候选人(Candidate)、跟随者(Follower)。跟随者都是被动的,他们不会发送任何请求,只是简单的响应来自领导者或者候选人的请求。领导人处理所有的客户端请求(如果一个客户端和跟随者联系,那么跟随者会把请求重定向给领导人),当跟随者长时间没接收到领导人的心跳包或候选人的请求投票RPC时(超时),便会成为候选人发起投票,直到成为领导人或收到新领导人的心跳包。
Raft相关特性:
Raft 算法中服务器节点之间通信使用远程过程调用(RPCs),并且基本的一致性算法只需要两种类型的RPCs。请求投票(RequestVote)RPCs和附加条目(AppendEntries)RPCs 。
请求投票(RequestVote)RPCs:由候选人在选举期间发起。
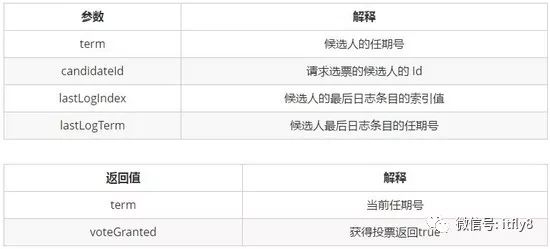
获得投票的条件:
跟随者投票后,则更新当前任期号,并记录投票候选人id,同一个任期,服务器最多只会投一次票[ 选举安全特性]。
term(候选人任期号)> currentTerm(服务器当前任期号)[ 选举安全特性]
比较候选人最后日志条目的索引值和任期号,候选人的日志至少和自己一样新,才会投票
附加日志RPC:由领导人发起,用来复制日志和提供一种心跳机制。

处理要点:
如果 term < currentTerm 就返回false。
如果日志在prevLogIndex位置处的日志条目的任期号和prevLogTerm不匹配,则返回false。
如果已经存在的日志条目和新的产生冲突(索引值相同但是任期号不同),删除这一条和之后所有的。
如果 leaderCommit > commitIndex(Follower节点已提交日志条目的索引值),令commitIndex等于leaderCommit和新日志条目索引值中较小的一个,commitIndex更新会将相应的日志条目应用到状态机。
一旦Candidate成为Leader,会立即发送空的附加日志 RPC(心跳)给其他所有的服务器,来阻止其他Follower超时发起选举。
二、领导人选举
Raft 通过选举一个领导人,然后全权交给它来管理复制日志来实现一致性。领导人从客户端接收日志条目,把日志条目复制到其他服务器上,并且当保证安全性的时候告诉其他的服务器应用日志条目到他们的状态机中。拥有一个领导人大大简化了对复制日志的管理。
选举的流程:当Follower(服务器程序启动时,都是Follower)长时间未接受到有效的Leader或者Candidate的RPCs时,发生超时则会增加自身任期号,成为Candidate,然后并行的向集群中的其他服务器节点发送请求投票的RPCs,候选人会继续保持着当前状态直到以下三件事情之一发生:(a) 获得大多数投票成为Leader,(b) 其他的服务器成为Leader,(c) 一段时间之后没有Leader产生。
每一次选举都是一个任期(term),任期由整数表示,单调递增。每次选举都会分配一段随机的超时时间选举超时时间(eg:150~300ms),若这段时间内未完成选举,则任期加1,开启新一轮的选举。(问题1:为什么分配一段”随机的”超时时间?文末统一回答☺)
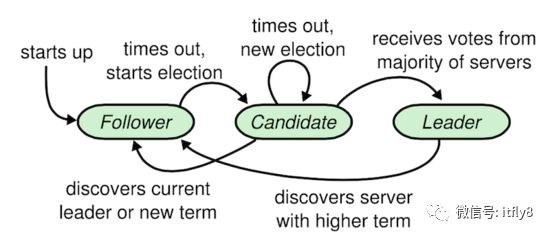
Raft节点状态变迁图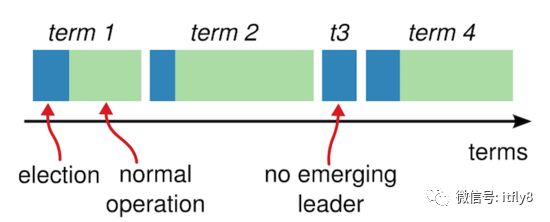
Raft任期变化图
三、日志复制
Raft是强Leader机制,日志只能从Leader复制到其他节点。日志项LogEntry包括index,term,command三个元素。其中index为日志索引,term为任期,而command为具体的日志内容。日志格式如下图所示:
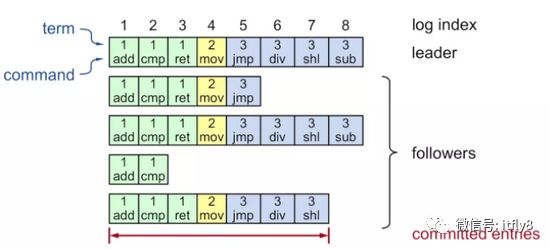
通常的日志复制流程是这样的:
客户端发送请求给Leader。
Leader接收客户端请求,先将请求命令作为一个日志项(LogEntry)append到自己的log中。
Leader发送 Append Entries RPC给Follower节点,当过半节点添加log成功后,则Leader提交该日志给状态机(此时日志条目的状态为已提交),返回给客户端写入成功。
在接下来的Append Entries RPC中通知其他节点提交该日志,Follower节点提交日志到自己的状态机中。
关于日志复制的几个要点:
不同的服务器上面的提交的相同的索引和任期的日志项的command一定相同,而且这个日志项之前的所有日志项都相同。
如果一个日志项被提交,则它之前索引的所有日志项也肯定已经提交。
Leader从来都不覆盖自己的日志。
Leader提交过的日志一定会出现将来新的Leader中。
若有Follower宕机或响应很慢怎么办?Leader会不断重试 RPC 请求直到成功,并且不会影响系统的正常运转,Leader只需要收到大部分Follwer的响应即可。
若Follower节点与Leader节点日志出现不一致怎么办?(问题2,文末统一回答☺)
在正常的操作中,领导人和跟随者的日志保持一致性,然而,领导人崩溃的情况会使得日志处于不一致的状态(老的领导人可能还没有完全复制所有的日志条目)。这种不一致问题会在领导人和跟随者的一系列崩溃下加剧。如下图:每一个格子表示是一个日志条目,里面的数字表示任期号。
当一个领导人成功当选时,跟随者可能是任何情况(a-f):
跟随者可能会缺少一些日志条目(a-b)。
可能会有一些未被提交的日志条目(c-d)。
或者两种情况都存在(e-f)。
场景 f 可能会这样发生,某服务器在任期 2 的时候是领导人,已附加了一些日志条目到自己的日志中,但在提交之前就崩溃了;很快这个机器就被重启了,在任期 3 重新被选为领导人,并且又增加了一些日志条目到自己的日志中;在任期 2 和任期 3 的日志被提交之前,这个服务器又宕机了,并且在接下来的几个任期里一直处于宕机状态。
四、安全性
前面描述了Raft是怎么选举和复制日志的,到目前为止描述的机制并不能充分的保证每一个状态机会按照相同的顺序执行相同的指令。因此,Raft增加了一些限制来保证安全性。有一些前面可能已经提过。
1.选举限制
请求投票 RPC 实现了这样的限制: RPC 中包含了候选人的日志信息,然后Follower会拒绝掉那些日志没有自己新的投票请求。Raft 通过比较两份日志中最后一条日志条目的索引值和任期号来定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
成为Leader需要获得大多数的投票,意味着需要比大多数节点的日志要新,而已提交的日志条目需要复制到大多数的节点,Leader能获得大多数的投票就意味着一定包含已提交的日志。
2.之前任期未提交日志处理
Raft永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导人当前任期里的日志条目才会通过计算副本数目去提交。下面举例说明为什么:
如图的时间序列展示了为什么领导人无法决定对老任期号的日志条目进行提交:
在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。
在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。
在(c)中,S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。
在(d)中,S1又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。
反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (e) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为S5 就不可能选举成功)。而且这样也同时保证了,之前的所有老的日志条目也会被提交。
所以,若之前任期的日志已复制到大多数节点,即使未提交,Raft也能保证最终会提交,并且,为了保证及时提交,新Leader上任后会立即往日志中追加一个空节点。
3.Follower和Candidate崩溃
之前我们只讨论了Leader崩溃的情况,当Follower和Candidate崩溃时,Raft 会不断的重试,如果崩溃的机器重启了,那么这些 RPC 就会完整的成功。如果一个服务器在完成了一个RPC,但是还没有响应的时候崩溃了,那么在他重新启动之后就会再次收到同样的请求。Raft 的 RPCs 都是幂等的,所以这样重试不会造成任何问题。
4.与客户端的交互问题
与客户端的交互过程中,Leader可能会崩溃,或网络超时,客户端未收到响应而发起重试,这可能会引起指令重复执行等问题。所以,客户端对于每一条指令都赋予一个唯一的序列号。然后,状态机跟踪每条指令最新的序列号和相应的响应。如果接收到一条指令,它的序列号已经被执行了,那么就立即返回结果,而不重新执行指令。
5.Raft稳定运行的要求和特性
在所有的非拜占庭将军条件下保证安全,包括网络延迟,分区,丢包,乱序等。
集群中的服务器超过半数可用。
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
广播时间指的是从一个服务器并行的发送 RPCs 给集群中的其他服务器并接收响应的平均时间;选举超时时间就是选举时的超时时间限制。广播时间必须比选举超时时间小一个量级,这样领导人才能够发送稳定的心跳消息来阻止跟随者开始进入选举状态。
问题1:Leader选举,为什么要分配一段”随机的”超时时间?
Raft 算法使用随机选举超时时间的方法来确保很少会发生选票瓜分的情况,就算发生也能很快的解决。因为超时时间相同的话,一旦两个Candidate选举发生选票瓜分情况而无法选出Leader,并且后续也很可能继续发生选票瓜分。影响Raft的正常运行。而随机时间是最简单也最容易理解的解决方式。
问题2:若Follower节点与Leader节点日志出现不一致怎么办?
最后用看到的一段话结尾:Raft就是一个在随机时间Leader选举基础上叠加了各种补丁的方案。从理论上来看,和简洁漂亮没有半毛钱关系。如果说Paxos是以不变应万变,告诉你一个究极真理,只要你有办法实现它告诉你的步骤,任何问题都有解,那么Raft就是一个手把手的构建指南,每一步都告诉你怎么具体怎么做,哪一步有漏洞,没关系,后续解法我也帮你想好了,没有究级的“道”,只有完善的“术”。
参考资料
一个形象的动画演示 http://thesecretlivesofdata.com/raft/
英文论文 https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf
中文翻译 https://github.com/maemual/raft-zh cn/blob/master/raft-zh cn.md
Raft相关实现 https://raft.github.io/#implementations
https://toutiao.io/posts/hdufp0/preview
https://juejin.im/entry/5b74e1f0f265da283479709f
出处:https://www.tuicool.com/articles/JB7jieR
以上是关于分布式-Raft协议的理解与分析的主要内容,如果未能解决你的问题,请参考以下文章