不可不知的分布式协议:Raft算法
Posted 码农小麦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不可不知的分布式协议:Raft算法相关的知识,希望对你有一定的参考价值。
Raft算法
Raft是由斯坦福大牛提出的更加便于理解的分布式共识算法,共识就是大部分节点对某个数据达成一致的看法。因为作者认为Paxos算法并不易于理解,很多人都是一知半解。原文请参见:
https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
Raft角色
Follower:跟随者,接收来自Leader的信息并保持心跳,如果一段时间没有收到Leader的心跳,就推荐自己成为Candidate。
Candidate:候选者,发起投票选举,如果获得majority的投票(自己肯定要投给自己),就升级成为Leader。
Leader:领导者,处理所有客户端请求,并同步日志到跟随者,当majority跟随者同步成功时,响应客户端。
Raft选举
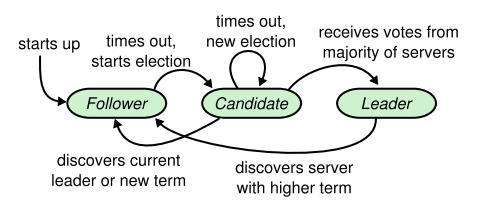
开始的时候所有节点都是Follower,每个节点都有一个随机超时时间(通常150ms~300ms),超时时间内没有收到来自Leader的心跳,Follower就升级为Candidate开始选举,每个节点都有一个term标识(表示当前任期通常为数字)。
正常选举开始,Candidate首先增加任期(比如1表示第一届),由于节点有随机超时时间,首先超时的节点会向其他节点发起RPC vote request,其他节点一看term大于自己,投票给发起Candidate(每次只能投一票),收到majority的投票后,发起者Candidate升级为Leader。
任期(term)
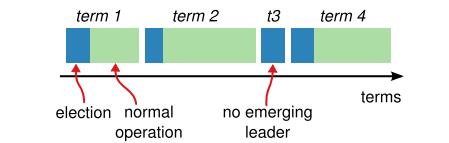
领导都是有任期的,任期的递增相当于逻辑上的时钟,每一个任期都会经历或长或短的任期,发生意外后(如Leader crash,Leader和Follower不可通信)造成Leader和Followers之间心跳断开时,Followers就会开始下一届选举,选举机制同上。
选举阶段所有Candidate会自增自己的term;收到比自己大的term时会更新自己的term为较大者并为较大者投票;当故障Leader恢复服务,发现自己term小于下一届Leader发来的请求,自动变为Follower;收到比自己小的term的请求时,Follower拒绝服务。
日志复制
Leader应对所有的对外请求,由Leader负责调度请求并按顺序同步给Follower,保证节点之间状态一致。简单来讲,Leader将请求wrap到log中,并严格按顺序同步给Followers,相同的初始状态+相同的输入=>相同的输出。由于网络原因,Leader和Follower可能并不是实时一致的,但保证了最终一致性。
总结
Raft是一种易于理解的分布式一致性、高可用协议,相比Paxos更容易理解。Raft将共识问题分解为选举和日志同步,本文只是简单阐述Raft算法,关于在任何情况下保证系统不出错,Raft论文中有更详细的规约,请参见原论文。大概流程可以参见以下链接,图文并茂的展示了Raft算法。
http://thesecretlivesofdata.com/raft/
图|码农小麦
文|码农小麦
排版|菩提无树
长按二维码
获取更多信息
以上是关于不可不知的分布式协议:Raft算法的主要内容,如果未能解决你的问题,请参考以下文章