在唯品会上的未支付订单最后是怎么处理的
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在唯品会上的未支付订单最后是怎么处理的相关的知识,希望对你有一定的参考价值。
如果会员在规定时间内没有成功结算,那么购物袋里的商品将被自动释放并重新上架。
当将喜欢的商品放进购物袋时,商品保留时间只有20分钟。超过20分钟还没有提交订单,商品将被自动释放并重新上架,供其他会员抢购。
扩展资料:
1、发货时效
在成功下单之后,唯品会将在12个小时内审核订单。订单通过审核后1-2天内安排发货。唯品会将通过品骏快递快递或第三方物流公司把商品送达。
2、货物追踪
当订单状态为“已发货”,此时商品已从唯品会或供应商仓库发出,并由物流公司进行配送。客户可在“订单管理"-"订单跟踪"中查看承运物流公司名称、运单号及订单处理信息,且可到物流公司网站进行追踪查询。
3、关于活动赠品
当订单满足促销活动赠送礼品的条件后,仍没有收到赠品,可能是由于出现以下三个情况:
(1)促销活动已结束,或赠品已派发完毕;
(2)每张订单最多享受3个活动优惠;
(3)使用优惠券后不能参加部分优惠活动,具体条款可以参考促销活动内容。
参考资料来源:唯品会-帮助中心> 常见问题
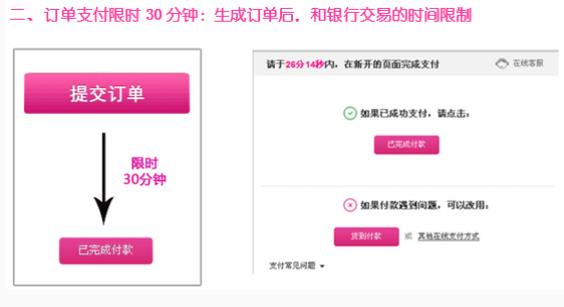
参考技术A1、在唯品会上下订单成功后一般60分钟没有完成支付,那么订单会自动失效。
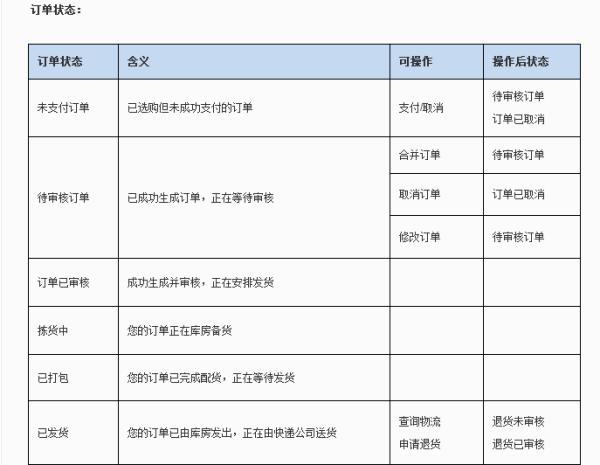
2、订单状态与操作如下:
Flink 在唯品会的实践
简介:Flink 在唯品会的容器化实践应用以及产品化经验。
唯品会自 2017 年开始基于 k8s 深入打造高性能、稳定、可靠、易用的实时计算平台,支持唯品会内部业务在平时以及大促的平稳运行。现平台支持 Flink、Spark、Storm 等主流框架。本文主要分享 Flink 的容器化实践应用以及产品化经验。内容包括:
- 发展概览
- Flink 容器化实践
- Flink SQL 平台化建设
- 应用案例
- 未来规划
GitHub 地址
https://github.com/apache/flink
欢迎大家给 Flink 点赞送 star~
一 、发展概览
平台支持公司内部所有部门的实时计算应用。主要的业务包括实时大屏、推荐、实验平台、实时监控和实时数据清洗等。
1.1 集群规模

平台现有异地双机房双集群,具有 2000 多的物理机节点,利用 k8s 的 namespaces,labels 和 taints 等,实现业务隔离以及初步的计算负载隔离。目前线上实时应用有大概 1000 个,平台最近主要支持 Flink SQL 任务的上线。
1.2 平台架构

- 上图是唯品会实时计算平台的整体架构。
- 最底层是计算任务节点的资源调度层,实际是以 deployment 的模式运行在 k8s 上,平台虽然支持 yarn 调度,但是 yarn 调度是与批任务共享资源,所以主流任务还是运行在 k8s 上。
- 存储层这一层,支持公司内部基于 kafka 实时数据 vms,基于 binlog 的 vdp 数据和原生 kafka 作为消息总线,状态存储在 hdfs 上,数据主要存入 redis,mysql,hbase,kudu,clickhouse 等。
- 计算引擎层,平台支持 Flink,Spark,Storm 主流框架容器化,提供了一些框架的封装和组件等。每个框架会都会支持几个版本的镜像满足不同的业务需求。
- 平台层提供作业配置、调度、版本管理、容器监控、job 监控、告警、日志等功能,提供多租户的资源管理(quota,label 管理),提供 kafka 监控。在 Flink 1.11 版本之前,平台自建元数据管理系统为 Flink SQL 管理 schema,1.11 版本开始,通过 hive metastore 与公司元数据管理系统融合。
最上层就是各个业务的应用层。
二、Flink 容器化实践
2.1 容器化实践

上图是实时平台 Flink 容器化的架构。Flink 容器化是基于 standalone 模式部署的。
- 部署模式共有 client,jobmanager 和 taskmanager 三个角色,每一个角色都由一个 deployment 控制。
- 用户通过平台上传任务 jar 包,配置等,存储于 hdfs 上。同时由平台维护的配置,依赖等也存储在 hdfs 上,当 pod 启动时,会进行拉取等初始化操作。
- client 中主进程是一个由 go 开发的 agent,当 client 启动时,会首先检查集群状态,当集群 ready 后,从 hdfs 上拉取 jar 包向 Flink 集群提交任务。同时,client 的主要功能还有监控任务状态,做 savepoint 等操作。
- 通过部署在每台物理机上的 smart - agent 采集容器的指标写入 m3,以及通过 Flink 暴漏的接口将 metrics 写入 prometheus,结合 grafana 展示。同样通过部署在每台物理机上的 vfilebeat 采集挂载出来的相关日志写入 es,在 dragonfly 可以实现日志检索。
■ Flink 平台化
在实践过程中,结合具体场景以及易用性考虑,做了平台化工作。
- 平台的任务配置与镜像,Flink 配置,自定义组件等解耦合,现阶段平台支持 1.7、1.9、1.11、1.12 等版本。
- 平台支持流水线编译或上传 jar、作业配置、告警配置、生命周期管理等,从而减少用户的开发成本。
- 平台开发了容器级别的如火焰图等调优诊断的页面化功能,以及登陆容器的功能,支持用户进行作业诊断。
■ Flink 稳定性
在应用部署和运行过程中,不可避免的会出现异常。以下是平台保证任务在出现异常状况后的稳定性做的策略。
- pod 的健康和可用,由 livenessProbe 和 readinessProbe 检测,同时指定 pod 的重启策略。
- Flink 任务异常时:
1.Flink 原生的 restart 策略和 failover 机制,作为第一层的保证。
2.在 client 中会定时监控 Flink 状态,同时将最新的 checkpoint 地址更新到自己的缓存中,并汇报到平台,固化到 MySQL 中。当 Flink 无法再重启时,由 client 重新从最新的成功 checkpoint 提交任务。作为第二层保证。这一层将 checkpoint 固化到 MySQL 中后,就不再使用 Flink HA 机制了,少了 zk 的组件依赖。
3.当前两层无法重启时或集群出现异常时,由平台自动从固化到 MySQL 中的最新 chekcpoint 重新拉起一个集群,提交任务,作为第三层保证。 机房容灾:
- 用户的 jar 包,checkpoint 都做了异地双 HDFS 存储
- 异地双机房双集群
2.2 kafka 监控方案
kafka 监控是我们的任务监控里相对重要的一部分,整体监控流程如下所示。

平台提供监控 kafka 堆积,消费 message 等配置信息,从 MySQL 中将用户 kafka 监控配置提取后,通过 jmx 监控 kafka,写入下游 kafka,再通过另一个 Flink 任务实时监控,同时将这些数据写入 ck,从而展示给用户。
三、Flink SQL 平台化建设
基于 k8s 的 Flink 容器化实现以后,方便了 Flink api 应用的发布,但是对于 Flink SQL 的任务仍然不够便捷。于是平台提供了更加方便的在线编辑发布、SQL 管理等一栈式开发平台。
3.1 Flink SQL 方案

平台的 Flink SQL 方案如上图所示,任务发布系统与元数据管理系统完全解耦。
■ Flink SQL 任务发布平台化
在实践过程中,结合易用性考虑,做了平台化工作,主操作界面如下图所示:
- Flink SQL 的版本管理,语法校验,拓扑图管理等;
- UDF 通用和任务级别的管理,支持用户自定义 UDF;
- 提供参数化的配置界面,方便用户上线任务。


■ 元数据管理
平台在 1.11 之前通过构建自己的元数据管理系统 UDM,MySQL 存储 kafka,redis 等 schema,通过自定义 catalog 打通 Flink 与 UDM,从而实现元数据管理。1.11 之后,Flink 集成 hive 逐渐完善,平台重构了 FlinkSQL 框架,通过部署一个 SQL - gateway service 服务,中间调用自己维护的 SQL - client jar 包,从而与离线元数据打通,实现了实时离线元数据统一,为之后的流批一体做好工作。在元数据管理系统创建的 Flink 表操作界面如下所示,创建 Flink 表的元数据,持久化到 hive里,Flink SQL 启动时从 hive 里读取对应表的 table schema 信息。

3.2 Flink SQL 相关实践
平台对于官方原生支持或者不支持的 connector 进行整合和开发,镜像和 connector,format 等相关依赖进行解耦,可以快捷的进行更新与迭代。
■ FLINK SQL 相关实践

- connector 层,现阶段平台支持官方支持的 connector,并且构建了 redis,kudu,clickhouse,vms,vdp 等平台内部的 connector。平台构建了内部的 pb format,支持 protobuf 实时清洗数据的读取。平台构建了 kudu,vdp 等内部 catalog,支持直接读取相关的 schema,不用再创建 ddl。
- 平台层主要是在 UDF、常用运行参数调整、以及升级 hadoop3。
- runntime 层主要是支持拓扑图执行计划修改、维表关联 keyBy cache 优化等
■ 拓扑图执行计划修改
针对现阶段 SQL 生成的 stream graph 并行度无法修改等问题,平台提供可修改的拓扑预览修改相关参数。平台会将解析后的 FlinkSQL 的 excution plan json 提供给用户,利用 uid 保证算子的唯一性,修改每个算子的并行度,chain 策略等,也为用户解决反压问题提供方法。例如针对 clickhouse sink 小并发大批次的场景,我们支持修改 clickhouse sink 并行度,source 并行度 = 72,sink 并行度 = 24,提高 clickhouse sink tps。

■ 维表关联 keyBy 优化 cache
针对维表关联的情况,为了降低 IO 请求次数,降低维表数据库读压力,从而降低延迟,提高吞吐,有以下几种措施:
- 当维表数据量不大时,通过全量维表数据缓存在本地,同时 ttl 控制缓存刷新的时候,这可以极大的降低 IO 请求次数,但会要求更多但内存空间。
- 当维表数据量很大时,通过 async 和 LRU cache 策略,同时 ttl 和 size 来控制缓存数据的失效时间和缓存大小,可以提高吞吐率并降低数据库的读压力。
- 当维表数据量很大同时主流 qps 很高时,可以开启把维表 join 的 key 作为 hash 的条件,将数据进行分区,即在 calc 节点的分区策略是 hash,这样下游算子的 subtask 的维表数据是独立的,不仅可以提高命中率,也可降低内存使用空间。

优化之前维表关联 LookupJoin 算子和正常算子 chain 在一起。

优化之间维表关联 LookupJoin 算子和正常算子不 chain 在一起,将 join key 作为 hash 策略的 key。采用这种方式优化之后,例如原先 3000W 数据量的维表,10 个 TM 节点,每个节点都要缓存 3000W 的数据,总共需要缓存 3000W * 10 = 3 亿的量。而经过 keyBy 优化之后,每个 TM 节点只需要缓存 3000W / 10 = 300W 的数据量,总共缓存的数据量只有 3000W,大大减少缓存数据量。
■ 维表关联延迟 join
维表关联中,有很多业务场景,在维表数据新增数据之前,主流数据已经发生 join 操作,会出现关联不上的情况。因此,为了保证数据的正确,将关联不上的数据进行缓存,进行延迟 join。
最简单的做法是,在维表关联的 function 里设置重试次数和重试间隔,这个方法会增大整个流的延迟,但主流 qps 不高的情况下,可以解决问题。
增加延迟 join 的算子,当 join 维表未关联时,先缓存起来,根据设置重试次数和重试间隔从而进行延迟的 join。
四、应用案例
4.1 实时数仓
■ 实时数据入仓

- 流量数据一级 kafka 通过实时清洗之后,写到二级清洗 kafka,主要是 protobuf 格式,再通过 Flink SQL 写入 hive 5min 表,以便做后续的准实时 ETL,加速 ods 层数据源的准备时间。
- MySQL 业务库的数据,通过 VDP 解析形成 binlog cdc 消息流,再通过 Flink SQL 写入 hive 5min 表。
- 业务系统通过 VMS API 产生业务 kafka 消息流,通过 Flink SQL 解析之后写入 hive 5min 表。支持 string、json、csv 等消息格式。
- 使用 Flink SQL 做流式数据入仓,非常的方便,而且 1.12 版本已经支持了小文件的自动合并,解决了小文件的痛点。
- 我们自定义分区提交策略,当前分区 ready 时候会调一下实时平台的分区提交 api,在离线调度定时调度通过这个 api 检查分区是否 ready。
采用 Flink SQL 统一入仓方案以后,我们可以获得的收益:可解决以前 Flume 方案不稳定的问题,而且用户可自助入仓,大大降低入仓任务的维护成本。提升了离线数仓的时效性,从小时级降低至 5min 粒度入仓。
■ 实时指标计算

- 实时应用消费清洗后 kafka,通过 redis 维表、api 等方式关联,再通过 Flink window 增量计算 UV,持久化写到 Hbase 里。
- 实时应用消费 VDP 消息流之后,通过 redis 维表、api 等方式关联,再通过 Flink SQL 计算出销售额等相关指标,增量 upsert 到 kudu 里,方便根据 range 分区批量查询,最终通过数据服务对实时大屏提供最终服务。
以往指标计算通常采用 Storm 方式,需要通过 api 定制化开发,采用这样 Flink 方案以后,我们可以获得的收益:将计算逻辑切到 Flink SQL 上,降低计算任务口径变化快,修改上线周期慢等问题。切换至 Flink SQL 可以做到快速修改,快速上线,降低维护成本。
■ 实时离线一体化 ETL 数据集成

Flink SQL 在最近的版本中持续强化了维表 join 的能力,不仅可以实时关联数据库中的维表数据,现在还能关联 Hive 和 Kafka 中的维表数据,能灵活满足不同工作负载和时效性的需求。
基于 Flink 强大的流式 ETL 的能力,我们可以统一在实时层做数据接入和数据转换,然后将明细层的数据回流到离线数仓中。
我们通过将 presto 内部使用的 HyperLogLog ( 后面简称 HLL ) 实现引入到 Spark UDAF 函数里,打通 HLL 对象在 Spark SQL 与 presto 引擎之间的互通,如 Spark SQL 通过 prepare 函数生成的 HLL 对象,不仅可以在 Spark SQL 里 merge 查询而且可以在 presto 里进行 merge 查询。具体流程如下:

UV 近似计算示例:
Step 1: Spark SQL 生成 HLL 对象
insert overwrite dws_goods_uv partition (dt='${dt}',hm='${hm}') AS select goods_id, estimate_prepare(mid) as pre_hll from dwd_table_goods group by goods_id where dt = ${dt} and hm = ${hm}
Step 2: Spark SQL 通过 goods_id 维度的 HLL 对象 merge 成品牌维度
insert overwrite dws_brand_uv partition (dt='${dt}',hm='${hm}') AS select b.brand_id, estimate_merge(pre_hll) as merge_hll from dws_table_brand A left join dim_table_brand_goods B on A.goods_id = B.goods_id where dt = ${dt} and hm = ${hm}
Step 3: Spark SQL 查询品牌维度的 UV
select brand_id, estimate_compute(merge_hll ) as uv from dws_brand_uv where dt = ${dt}
Step 4: presto merge 查询 park 生成的 HLL 对象
select brand_id,cardinality(merge(cast(merge_hll AS HyperLogLog))) uv from dws_brand_uv group by brand_id
所以基于实时离线一体化ETL数据集成的架构,我们能获得的收益:
- 统一了基础公共数据源;
- 提升了离线数仓的时效性;
- 减少了组件和链路的维护成本。
4.2 实验平台(Flink 实时数据入 OLAP)
唯品会实验平台是通过配置多维度分析和下钻分析,提供海量数据的 A / B - test 实验效果分析的一体化平台。一个实验是由一股流量(比如用户请求)和在这股流量上进行的相对对比实验的修改组成。实验平台对于海量数据查询有着低延迟、低响应、超大规模数据(百亿级)的需求。整体数据架构如下:

通过 Flink SQL 将 kafka 里的数据清洗解析展开等操作之后,通过 redis 维表关联商品属性,通过分布式表写入到 clickhouse,然后通过数据服务 adhoc 查询。业务数据流如下:

我们通过 Flink SQL redis connector,支持 redis 的 sink 、source 维表关联等操作,可以很方便的读写 redis,实现维表关联,维表关联内可配置 cache ,极大提高应用的 TPS。通过 Flink SQL 实现实时数据流的 pipeline,最终将大宽表 sink 到 CK 里,并按照某个字段粒度做 murmurHash3_64 存储,保证相同用户的数据都存在同一 shard 节点组内,从而使得 ck 大表之间的 join 变成 local 本地表之间的 join,减少数据 shuffle 操作,提升 join 查询效率。
五、未来规划
5.1 提高 Flink SQL 易用性
当前我们的 Flink SQL 调试起来很有很多不方便的地方,对于做离线 hive 用户来说还有一定的使用门槛,例如手动配置 kafka 监控、任务的压测调优,如何能让用户的使用门槛降低至最低,是一个比较大的挑战。将来我们考虑做一些智能监控告诉用户当前任务存在的问题,尽可能自动化并给用户一些优化建议。
5.2 数据湖 CDC 分析方案落地
目前我们的 VDP binlog 消息流,通过 Flink SQL 写入到 hive ods 层,以加速 ods 层数据源的准备时间,但是会产生大量重复消息去重合并。我们会考虑 Flink + 数据湖的 cdc 入仓方案来做增量入仓。此外,像订单打宽之后的 kafka 消息流、以及聚合结果都需要非常强的实时 upsert 能力,目前我们主要是用 kudu,但是 kudu 集群,比较独立小众,维护成本高,我们会调研数据湖的增量 upsert 能力来替换 kudu 增量 upsert 场景。
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

活动推荐:
仅需99元即可体验阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版!点击下方链接了解活动详情:https://www.aliyun.com/product/bigdata/sc?utm_content=g_1000250506

原文链接:https://developer.aliyun.com/article/783782?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
以上是关于在唯品会上的未支付订单最后是怎么处理的的主要内容,如果未能解决你的问题,请参考以下文章