Clickhouse 在唯品会数据产品的实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Clickhouse 在唯品会数据产品的实践相关的知识,希望对你有一定的参考价值。
本文作者:邓刚,陈晨,周飞强,冯广远,严旭东
一、唯品会离线数仓模式
1.1 数据产品使用数仓数据的方式
公司的数据产品包括数据运营平台,自助分析,魔方(对接供应商),运营中台等。数据产品使用数仓数据主要是如下几种方式(整体的数据使用现状见图1):
| 使用方式 | 场景 | 优点 | 缺点 | 使用是否广泛 |
|---|---|---|---|---|
| 直接对接presto jdbc查询数仓数据 | 数据产品直接通过olap jdbc对接数仓数据 | 接入方便,数据准备完成后,就可以直接查询 | presto SLA 访问hdfs 数据难以保障且时延较大(> 15s 占比 5% ) | 是 |
| 数据出仓到mysql | 对于时延敏感<1s, 查询量大且总体数据量较小的情况 | 可以支持较高的qps (1w), 时延低 | 每个业务方都是自己申请mysql, 自己出仓,不方便数据整体管理 | 否 |
| 数据出仓到es | 对于时延敏感<1s, 整体数据量较大 | es 快速稳定 | es 对于sql支持不好。后端开发人员工作量巨大。HLL 跟其他系统共享存在问题 | 否 |
| 数据出仓到redis | 对于时延敏感<1s, QPS 需求很高 | redis qps sla 很高 | 使用场景较为单一,每个业务方都是自己申请redis | 否 |
表1:数仓数据使用方式
Presto 方案是公司数据产品使用的主流场景,主要基于以下几点:
presto 即插即用,方便sql 访问,可以通过sql 直接对接数据产品的页面,对于后端开发工作量小。
presto 作为olap engine时延相对有保障。
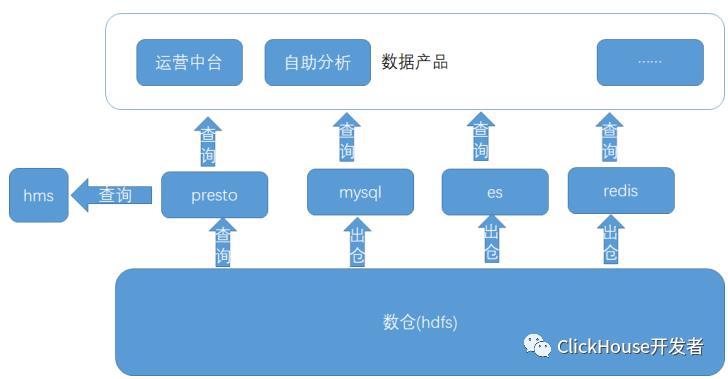 图1:数据产品使用数仓的数据流图
图1:数据产品使用数仓的数据流图
1.2 数仓数据的使用问题
在presto 对接数据产品的场景中,访问数仓数据的链路如下:
用户sql 请求到达presto 集群后,presto 会根据sql 访问hms;
hms 访问mysql 的存储的元数据信息(mysql 是主从架构,非分布式架构);
presto 拿到优化后的物理执行计划,访问hdfs, 这里我们的hdfs 基本都是ssd 作为存储介质;
执行返回用户查询结果。
在上述的4个步骤中,第2,3两步都存在访问抖动的问题,造成presto SLA变差。具体问题表现在以下几点:
当表分区数量很大的时候以及高并发查询的情况下,hms 的底层mysql响应延迟加大,影响presto SLA ,甚至出现presto 整体不可用的情况。
hdfs(ssd) 作为presto 访问的存储,数据产品的访问存在天然的数据访问热点,如魔方一个数据产品的访问量在200w/天。hdfs 集群rpc 的稳定性以及读取hdfs 文件bolck 的效率都对presto 的SLA存在很大的影响。
基于上述问题,决定采用clickhouse 作为数据产品olap SLA的解决方案(如图2),数据产品的表自动导出到clickhouse,供客服系统,供应商系统等数据产品使用。
 图2:统一的指标服务提供数据产品查询服务
图2:统一的指标服务提供数据产品查询服务
二、clickhouse在唯品会的使用
2.1 集群规模
离线集群
32节点 80c 320G SDD 1.92T * 3 HDD 8T * 10
集群表数量:37(目前还在快速的扩张)
集群数据量:15.5T
查询耗时:95%在1s以内,部分hll的查询在2s左右
实时集群
20节点 24c 128G SDD 1.92T*3
集群表数量:23
实时集群数据量:11.12T
单表分区最大行数:50亿---160亿
查询耗时:90%查询在2s以内,部分大表join耗时在10s以上
集群部署
 图3: 整体部署框架
图3: 整体部署框架
2.2 表引擎选择
平台的主要业务方的使用场景目前都不是很复杂。因此使用的是 分布式表(Distributed) + 本地复制表(ReplicatedMergeTree)。为了保障CK集群的高可用,目前使用的一个分片使用两副本的机制,来做数据冗余备份。
2.3 业务使用方式
目前我们提供2种方式查询,如图3所示:
通过 Hera (数据服务) Client API 来查询,业务自己写SQL,并选择CK引擎来查询。
通过 Chaos (指标服务) Client API 来查询,业务传入查询条件,指标服务来构建业务SQL。指标服务中支持了 Engine 下推的功能,即如果业务查询的SQL数据日期已经出仓到CK,那么指标服务在查询的时候,就使用CK引擎,如果业务使用的数据没有出仓到CK,那么就使用 Presto 来查询。这样既保证了服务SLA,又可以提高某些场景下的SQL查询速度。如图4所示。
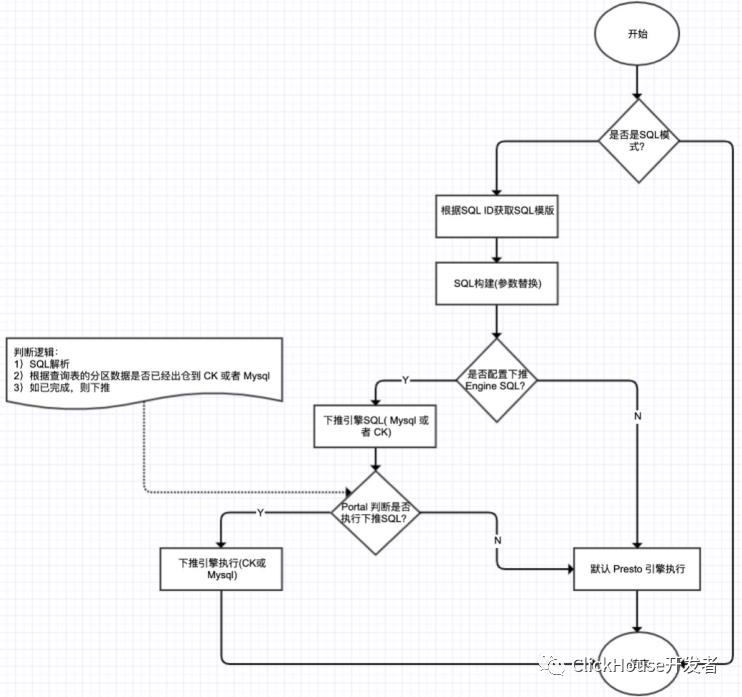 图4:Engine 下推流程
图4:Engine 下推流程
2.4 遇到的问题
2.4.1 问题1:跳数索引(skipping index) 优化
问题描述:
一般情况下,SQL查询时使用跳数索引可以过滤掉部分数据(表的数据量单个分区1000万+左右)。当表的单个分区到了1亿+,SQL查询时,发现跳数索引没有过滤部分数据,并且随着表数据量增加,查询会更慢,跳数索引好像没有效果一样。如下面日志所示:
2020.12.22 08:46:34.580970 [ 125699 ] {b4afef28-3c35-4c1c-a450-af60c05dbf0e} <Debug> vipscene.ads_scene_goods_from_expose_mid_1d_local (92eed744-179a-4345-a355-a8d1c32d778e) (SelectExecutor): Index `idx_app_platform` has dropped 0 / 23 granules.
2020.12.22 08:46:34.581074 [ 205320 ] {b4afef28-3c35-4c1c-a450-af60c05dbf0e} <Debug> vipscene.ads_scene_goods_from_expose_mid_1d_local (92eed744-179a-4345-a355-a8d1c32d778e) (SelectExecutor): Index `idx_app_platform` has dropped 0 / 35 granules.
2020.12.22 08:46:34.581283 [ 125699 ] {b4afef28-3c35-4c1c-a450-af60c05dbf0e} <Trace> vipscene.ads_scene_goods_from_expose_mid_1d_local (92eed744-179a-4345-a355-a8d1c32d778e) (SelectExecutor): Used generic exclusion search over index for part b3c1358079be3c5b02c2f93b0a50716d_58313_58345_4 with 46 steps
2020.12.22 08:46:34.581383 [ 205320 ] {b4afef28-3c35-4c1c-a450-af60c05dbf0e} <Trace> vipscene.ads_scene_goods_from_expose_mid_1d_local (92eed744-179a-4345-a355-a8d1c32d778e) (SelectExecutor): Used generic exclusion search over index for part b3c1358079be3c5b02c2f93b0a50716d_58346_58382_5 with 49 steps
原因和解决方案 经分析发现,CK 跳数索引并不是跟我们理解中的索引是一个概念(如mysql索引),原因是正常的索引都是让数据按照索引字段进行聚集,或者把行号按照索引字段聚集起来。而CK中的跳数索引并不会做任何聚集的事情,它只是加速筛选Block的一种手段。所以随着表数据量不断增大,且在跳数索引字段无序的情况下,跳数索引只会增多SQL查询时间,却无法过滤掉一些不相关的数据。
要想使用跳数索引字段生效的话,需要将跳数索引字段加到 order by 排序字段中,将索引字段加上排序。这样SQL查询的时候,使用到了跳数索引字段,就会起到过滤部分一些不相关的数据,如下日志所示
2020.12.24 14:02:53.398769 [ 14660 ] {51322208-1183-4144-a57c-db5ed032e60c} <Trace> vipscene.ads_scene_goods_from_expose_mid_1d_local (e90e70e7-4390-4c5f-9545-6847e8e0bb96) (SelectExecutor): Used generic exclusion search over index for part b3c1358079be3c5b02c2f93b0a50716d_58150_58193_3 with 57 steps
2020.12.24 14:02:53.399022 [ 93810 ] {51322208-1183-4144-a57c-db5ed032e60c} <Trace> vipscene.ads_scene_goods_from_expose_mid_1d_local (e90e70e7-4390-4c5f-9545-6847e8e0bb96) (SelectExecutor): Used generic exclusion search over index for part b3c1358079be3c5b02c2f93b0a50716d_4704_4974_3 with 141 steps
2020.12.24 14:02:53.398964 [ 18694 ] {51322208-1183-4144-a57c-db5ed032e60c} <Trace> vipscene.ads_scene_goods_from_expose_mid_1d_local (e90e70e7-4390-4c5f-9545-6847e8e0bb96) (SelectExecutor): Used generic exclusion search over index for part b3c1358079be3c5b02c2f93b0a50716d_5342_5614_3 with 140 steps
2020.12.24 14:02:53.399129 [ 14660 ] {51322208-1183-4144-a57c-db5ed032e60c} <Debug> vipscene.ads_scene_goods_from_expose_mid_1d_local (e90e70e7-4390-4c5f-9545-6847e8e0bb96) (SelectExecutor): Index `idx_app_platform` has dropped 2 / 12 granules.
2.4.2 问题2:本地表重建异常
问题描述:
本地表删除重建异常
File not found: /home/vipshop/hard_disk/2/ck_data/store/c81/c817b68e-8529-418c-9a16-a970d3a8ebb0/format_version.txt (version 20.12.5.14)
原因和解决方案:
经分析以下情况(只是官方的错误提示不太友好)可能导致表重建异常:
部分分片节点配置文件错误,导致一个节点注册到多个分片上。这种情况下,需要检查 macros.xml 配置和zookeeper注册的CK 节点。
当前节点表结构跟其他节点不一致,如表新增某个字段,但是没有同步所有节点上,导致表结构不一致。那么使用最新的表结构创建即可。
老的表meta文件路径删除有延迟,导致重新建表异常(我们机器采用的是 3块 ssd 存储热数据,单盘raid0)。这种情况下,要么等待一下,预计10分钟左右,或者手动删除掉这个路径也行(前提确定一下这个路径是否有其他表使用,避免误删)。
2.4.3 问题3:Zookeeper 问题
Zookeeper 上“无效”副本数据
问题描述:
CK集群一个分片中某个副本节点硬件有问题,需要下线替换新机器,但是在新节点上线后,发现CK数据量不一样(CK跟Hive)。
原因和解决方案:
查看CK监控,发现某个CK节点数据merge太慢。分析对应节点的日志,发现数据分片中副本还一直尝试将数据同步已经下线的CK节点上,导致该节点一直很繁忙,数据 part merge 慢了。
2021.04.23 08:53:28.467903 [ 73764 ] {} <Warning> vipcube.dm_sup_vendor_industry_trade_day_local (ReplicatedMergeTreePartCheckThread): Checking part dfc5acac111aaac0eafc9d9123c58d02_0_4_1
2021.04.23 08:53:28.468076 [ 73764 ] {} <Warning> vipcube.dm_sup_vendor_industry_trade_day_local (ReplicatedMergeTreePartCheckThread): Checking if anyone has a part covering dfc5acac111aaac0eafc9d9123c58d02_0_4_1.
2021.04.23 08:53:28.468704 [ 73764 ] {} <Warning> vipcube.dm_sup_vendor_industry_trade_day_local (ReplicatedMergeTreePartCheckThread): Found part dfc5acac111aaac0eafc9d9123c58d02_0_4_1 on IP that covers the missing part dfc5acac111aaac0eafc9d9123c58d02_0_4_1
查看zookeeper上节点数据,发现部分表 replicas节点上还存在之前下线的节点,手动删除掉无效的副本节点后,CK服务快速恢复。如下图所示:
[zk: localhost:2181(CONNECTED) 20] ls /clickhouse/tables/ck-clickhouse-011/dm_sup_vendor_industry_trade_day_local/replicas
[IP1, IP2, IP3]
(按照我们生产配置,一个表正常是2个节点,但是 dm_sup_vendor_industry_trade_day_local 却出现了3个节点)。
 图5:Zookeeper 节点数目变化
图5:Zookeeper 节点数目变化
Zookeeper Node节点暴增
问题描述:
目前平台有2个CK集群,一个离线CK集群,通过 开源 Waterdrop 来导数。还有一个是实时CK集群,通过Flink实时写入CK,实时CK集群最近频繁的收到zookeeper的告警,如下面所示:
Zookeeper节点告警信息
[zookeeper]队列积压数超过200 zookeeper.outstanding_requests lookup(#4,5)>300, 当前值:502
[[zookeeper]快照数据文件大小超过1G] zookeeper.approximate_data_size all(#5)>=1073741824, 当前值:2251050072
原因和解决方案
经过排查发现,业务数据增长很快,最开始接入点的时(去年10月份),最大表的数据量从 100亿+ 到 现在 400亿+,最大的表数据翻了4倍。而且最开始申请时,由于存储资源不是很足,所以机器存储空间较小(单机3T SSD), 导致部分CK节点磁盘空间使用率到了94%。
同时这个业务本身特殊性, 数据通过Flink写入分布式表,都知道通过分布式表写入比通过本地表写入需要多一倍的磁盘空间。这样在数据量很大的时候,而且磁盘空间使用率接近90%时,会导致部分节点写入失败问题。这样写入失败的节点,写入的任务事件还是会在zookeeper上保留,无法消费,进而导致Zookeeper Node堆积越来越多。最终 queue子节点堆积到 180W+。
解决方案:
重新部署一套新CK集群,使用标准机型(单机32T),避免存储导致写入失败
实时CK集群使用多套Zookeeper集群,根据表数据量来拆分到不同Zookeeper上,减轻zookeeper集群的读写压力
针对分布式表写入磁盘空间不足的问题,可以调整一下 config.xml old-parts-lifetime 参数。
参考链接:
https://github.com/ClickHouse/ClickHouse/issues/11247
https://github.com/ClickHouse/ClickHouse/issues/11724
 图6:zookeeper节点暴增
图6:zookeeper节点暴增
Zookeeper节点queue节点过多问题
[zk: localhost:2181(CONNECTED) 9] get -s /clickhouse/tables/ck-clickhouse-013/dw_log_reco_abservice/replicas/xxx/queue
cZxid = 0xc105b072e
ctime = Mon Apr 12 18:24:35 CST 2021
mZxid = 0xc105b072e
mtime = Mon Apr 12 18:24:35 CST 2021
pZxid = 0x113e4f601d
cversion = 15391508
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1804470
三、数据出仓改造
3.1 Waterdrop clickhouse plugin改造
数仓数据需要同步到clickhouse表,同步方式我们采用clickhouse jdbc方式,通过spark计算引擎读取hive表数据构建DataFrame,每个Partition建立一个JDBC连接按批次写入,该方案有开源实现(waterdrop,一个使用spark/flink做为计算引擎的统一数据同步解决方案)。

图7:原waterdrop写入clickhouse流程图
3.1.1 Waterdrop同步方案存在几个问题
clickhouse没有事务的概念,我们使用的ReplicatedMergeTree很难做到Exactly Once,spark的task失败重试或者task的推测执行会导致某一批次数据重复导入,最终导致数据重复。
如果要按照指定的分片规则写入clickhouse,只能通过写clickhouse分布式表,但是写分布式表存在写入放大的问题,如果要写入本地表需要实现自定义分片规则。
clickhouse的所有写入和删除操作都是异步的,从写入日志到数据文件是异步的Merge过程,数据写入完成到数据可查询有一定的Delay。
clickhouse没有insert overwrite操作,不能覆盖分区数据,当Hive表数据重刷时,需要先手动drop掉clickhouse原分区再执行导入。
3.1.2 解决方案
对于上面存在的几个问题我们做了几点改造,以及探索了一些实践方案。通过Spark参数控制禁止Spark Task重试,禁止推测执行:
关闭推测执行
set spark.speculation=false;
将Application级别的重试次数设置为1
set spark.yarn.max.executor.failures=1
将stage级别的失败重试次数设置为1
set spark.stage.maxConsecutiveAttempts=1
将Task级别的失败重试次数设置为1
set spark.task.maxFailures=1
通过写本地表来解决写分布式表写入放大的问题,同时在waterdrop程序中对写入数据的分片规则做相应的修改。除了本身实现的Radom写入,我们实现了 Hash 分片规则写入,轮训分片写入,加权随机写入。
需要特别介绍的是Hash分片规则写入,因为按照指定key分片的正确性直接影响clickhouse local join的正确性,在我们的A/B Test实验平台的业务场景涉及到两个表需要Join的场景(虽然官方并不建议使用clickhouse的join).
我们按照配置的需要分片的字段通过spark的repartition算子按照指定key重分区,将分区ID按照clickhouse的shard_num 取模决定写入的分片。
clickhouse数据同步任务我们集成了离线统一调度平台,根据读取的表自动依赖上游输入表的ETL任务,上游ETL任务刷新表数据之后,调度运行同步任务,将最新数据刷入到clickhouse;
针对clickhouse不能执行insert overwrite 的操作,我们在waterdrop同步工具增加了pre_sql配置,可以根据需要先drop 已经存在的分区(如果是非分区表则truncate表数据),然后再执行数据导入,并且直接集成到调度平台的导出任务中,可以由上游ETL任务重刷数据时拉起clickhouse同步任务重跑,不会导致数据质量问题。
异步merge的问题我们需要避免读取的时候是未Merge完成的中间过程的数据,因此我们增加了一步check_sum操作,检查到clickhouse表的数据总数和hive表相同时,才认为同步成功,clickhouse数据可使用,否则同步任务失败;
我们开发了一些其他的监听器插件:
例如TimeOutListerner为了避免由于数据倾斜(需要同步的hive表根据特定倾斜的key重分区),或者内存不足,或者executor_num * core_num 数量与实际task数量配置不合理,或者关闭推测执行之后某些Task夯住不动的情况,可配置超时失败;
HttpCallListener为了解决数据可查询标记的写入,可以通过此插件在clickhouse同步数据成功之后将此表的数据标记为可查询。

图8:改进之后的waterdrop写入流程图
改造之后的数据同步方案,集成在ETL调度系统中,可以由数据产品业务方自助配置使用,极大的减轻了平台的压力。
3.2 airlift hyperloglog 数据兼容
数据产品对接的数仓表中存在大量使用HLL进行非精确统计,以及利用细粒度的HLL数据进行group by 得到粗粒度的数据的使用场景(如流量明细数据(PV),统计商品的浏览UV(HLL)表A,基于表A的商品的浏览UV(HLL)汇总到品牌的UV (merge(uv) group by brand)。此时需要使用binary 数据再次进行merge。因为在spark,presto 底层的airlift 都是使用同一套算法体系,数据产品通过presto 方案hll 数据进行计算没有格式问题。但是我们需要将hive 的hll binary 数据直接导入到clickhouse, 利用clickhouse的查询engine来解决数据产品的SLA 问题,那么我们需要将数据产品的使用场景在clickhouse 得到解决,因此我们需要解决的问题是hive airlift的HLL 数据怎么导入clickhouse 以及导入后在clickhouse 中怎么使用hive airlift hll 数据(如图9)。

图9:clickhouse HLL 与 hive HLL 互通问题
spark/presto 跟clickhouse HLL中间数据不兼容和估算结果差异的原因:
底层存储结构的不同:ClickHouse大体上分为两种结构来保存中间结果,小数据量下使用Map结构保存原始值,能得到精确统计结果;而在大数据量场景下,则使用标准的稠密存储结构,即长度为(bucket_count * content_width + 7) / 8的字节数组,表示所有从Hash值计算得到的桶索引及其值。airlift库中的实现有两种,小数据量场景下使用自义的Sparse数组结构;大数据量场景下,使用优化的、标准的Dense存储结构。这两种结构都是对Hash值计算得到的桶索引及其值的不同表示形式,统计结果理论上都是非精确的。
Hash算法和估算公式不同:虽然两个系统都实现了相同的、基于HLL思想的估算算法,但不同之处也不少,如不同字段类型的使用Hash算法不同,计算桶索引及值的方式不同(airlift中的实现基于前导0,而CK中的实现基于尾部0),求和公式不同(airlift中使用更精确地误差偏移量表)等。
3.2.1 聚合函数实现思路
解决方案分为如下两种:
基于ClickHouse中存储结构的实现:实现过程可简单地理解为在Presto侧自定义UDF/UDAF,将中间表的HLL数据转换成可以被CH直接读取的稠密格式,而在CH侧要做的仅仅是兼容Binary数据格式,同时也忽略了估算公式上的差异,最终解决数据格式不兼容问题。基于此方案,我们完成了第一版的改造,但这种方式明显在小数据量场景下(如在性能测试章节提到的小时表),处理速度不及预期,毕竟这种转换方式会将Sparse结构转换为Dense结构,在空间及时间损耗更大,实际测试结果佐证了这个结果。
基于airlift库中存储结构的实现:实现过程可简单地理解为在ClickHouse侧自定义UDAF函数,支持直接读写airlift中的HLL算法产生的中间结果(即Sparse、Dense格式的Binary数据),同时为了得到误差更小的估算结果,用airlift中使用的误差偏移量表替换CH中的定义,最终解决数据格式不兼容问题。基于此方案,我们完成了第二版的改造,最终的测试性能相比于第一版,有至少1倍的提升。
3.2.2 数据聚合性能测试
下面是在两种场景下,基于第二版的UDAF实现(自定义uniqHLLMixed聚合函数),分别在Presto和ClickHouse集群上测试的结果,很容易看到,在相同条件下CK比Presto快出至少一倍。
| 引擎 | 表类型 | 运行耗时 | 测试环境 |
|---|---|---|---|
| Presto | Hive表 | 8.3 ~ 13 | 6节点 48C/128G/SSD |
| ClickHouse | Cluster表 | 4.2s | 6节点 48C/128G/SSD |
| ClickHouse | 物化视图表 | 2.3s | 6节点 48C/128G/SSD |
表2:天表性能对比表(记录数在 200 ~ 300W之间)
Query统计:
12 rows in set. Elapsed: 4.295 sec. Processed 2.32 million rows, 92.88 GB (539.36 thousand rows/s., 21.62 GB/s.)
经过几十次测试查询,基于ClickHouse上的分布式表,对天表中的10个字段数据进行聚合计算的执行速度,要比Presto快1倍左右。如果配合使用Materialized View,则查询速度又会提升约40%
| 引擎 | 表类型 | 运行耗时 | 测试环境 |
|---|---|---|---|
| Presto | Hive表 | 27s~34s | 6节点 48C/128G/SSD |
| ClickHouse | Cluster表 | 4.417s ~ 4.568s | 6节点 48C/128G/SSD |
| ClickHouse | 物化视图表 | 2s ~ 3s | 6节点 48C/128G/SSD |
表3:小时表性能对比表(记录数约 2,700,000)
Query统计:
(11 rows in set. Elapsed: 4.414 sec. Processed 2.66 million rows, 2.36 GB (603.45 thousand rows/s., 535.47 MB/s.)
四、后续思考
clickhouse 作为公司数据产品的SLA 解决方案。能够解决数据产品SLA的诉求。但是clickhouse 在使用过程中,还是有许多问题需要解决:
如何优雅的做到exactly once的写。
clickhouse 数据导入存在一定的时延,如何减少时延。
clickhouse hyperloglog 作为plugin 如何merge 到社区。
存储与计算分离。
人群计算在clickhouse 中的使用探索。
未来的计划:
集群读写分离,解决导入数据对查询性能的影响。
引入kafka等组件,解决数据一致性的问题。
容器化部署,解决集群弹性扩缩容以及新节点数据自平衡的问题。
集群更好的平台化,故障自愈能力提升。
以上是关于Clickhouse 在唯品会数据产品的实践的主要内容,如果未能解决你的问题,请参考以下文章
资源消耗降低2/3,Flink在唯品会实时平台的应用(有彩蛋)