机器学习应用设计阶段的 10 个陷阱和 11 个最佳实践
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习应用设计阶段的 10 个陷阱和 11 个最佳实践相关的知识,希望对你有一定的参考价值。
本文最初发表于 Towards Data Science 博客,经原作者 Bruce H. Cottman 授权,InfoQ 中文站翻译并分享。
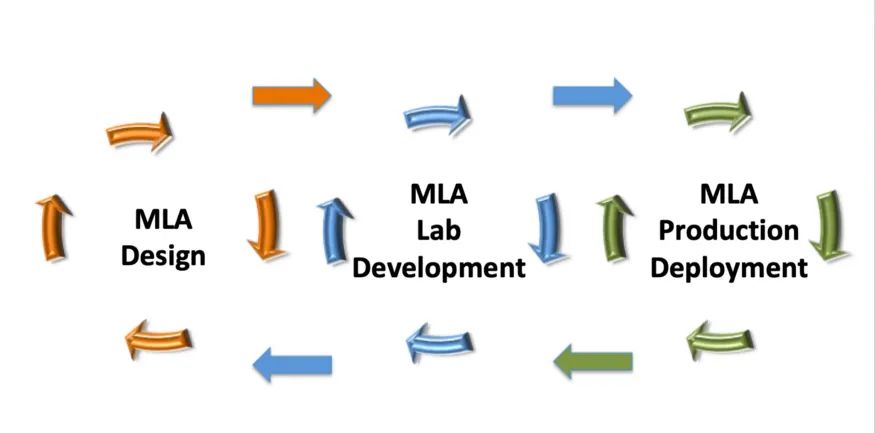 图 1:机器学习应用的迭代生命周期
图 1:机器学习应用的迭代生命周期
你是否成功设计、训练和测试了一个机器学习应用(Machine Learning Application,MLA)?虽然经过了实验室的审核,但机器学习应用的表现却是不能令人接受的,甚至可能在生产中失败?
如果是这样,请继续阅读本文,我将详细介绍我的同事和我遇到过的陷阱。接下来我将详细讨论最佳实践,其中一些是我们已经开发的可避免这些陷阱的解决方案。
降低机器学习应用设计、开发和部署的高成本和负担,是 DataOps、DevOps、MLOps、GitOps、CloudOps......xOps 的方法论领域,其中,Ops 代表运营(Operations)。
我们认为,你应该按照这个顺序,先学会爬行,再学会行走,再学会跑步,然后也许是再学会飞行。
在我们看来,xOps 就相当于机器学习应用生命周期中的行走、跑步和飞行。
我们从爬行开始。
本文重点讨论项目启动时的陷阱和最佳实践:机器学习应用设计阶段。
项目管理可以布置成一个步骤图(边和节点)。按特定顺序执行的任务就是瀑布式项目管理方法。一个例子是按设计、开发、测试和最后部署的顺序排列。
机器学习应用项目管理被想象成一种连续的任务循环图(参见图 1)。我们也可以把一个应用项目看作是一个任务清单,其中每个任务都是部分完成的。这些任务中有些可以并行执行,有些依赖于其他任务,有些重复执行,直到应用变成“垃圾箱”。
但愿以上就是我们需要讨论的关于机器学习应用项目管理方法的全部内容。从现在开始,我们将重点介绍一些在机器学习应用设计阶段所遇到的比较多的陷阱。这些陷阱来自于 40 多年的综合经验和大约 18 个机器学习应用项目。
对于本文所列举的任何陷阱,都会详细说明一种或多种最佳实践的变通办法或解决方案。每个最佳实践通常都是一个组件任务,它只有尽可能少的先验输入。你会注意到,有些任务有不可避免的启动依赖性。
在机器学习应用项目生命周期中,我们也陷入了开发和生产过程中的陷阱。我们(通常)用最佳实践来发现自我。
我们之所以把这个陷阱放在第一个位置,是因为作为一家咨询集团,主要是在 2016 年及更早的时候,在业务问题不需要机器学习解决方案的时候,我们常常将精力投入到机器学习方案。
对所有这些客户来说,他们想要说他们正在使用机器学习应用,无论他们是否需要机器学习,还是没有为机器学习做好准备。
请不要笑,但在 2017 年之前的早些时候,我们受雇于客户,却没有发现任何数据或问题。
我们发现,第 1 个陷阱和第 2 个陷阱都需要解决,然后才能继续。
不要与那些不能或不愿意让你定义可行的机器学习解决方案的公司合作。
你的第一个项目应该增加功能,而不是替换和改进现有功能。
要证明机器学习的增值,首先要避免将机器学习应用于组织的遗留(现有)系统。说起来容易做起来难!
关键绩效指标(Key Performance Indicators,KPI)被组织视为重要指标。组织可以衡量各部门、流程和项目的健康指标。
另外,对利益相关者进行调查,找出最让他们失望的地方。
举例来说,一家连锁酒店衡量房间的可用性,或者一家餐厅衡量桌子的可用性。机器学习可以根据过去的预订情况预测未来的预订情况。但是,更有价值的机器学习会降低可用性。
一旦确定了业务用例问题,就可以提出一个机器学习应用解决方案。在第一个机器学习应用取得可衡量的成功之后,你就可以启动其他的机器学习应用项目了。
这种最佳实践是突出的。但不那么明显的是,在第一个机器学习应用项目投入生产之前,你的赞助商可能希望启动更多的机器学习应用项目。
你的赞助者(或你)可能会因为实验室中训练、测试和验证的漂亮结果而非常兴奋。提醒自己和他们要对过去的灾难保持警觉。
创建单体应用会导致瀑布式开发过程。不同的步骤和应用的各个部分是高度相关的。
将机器学习应用设计成组件或微服务的管道。在这种情况下,每个组件都是一个可分离的机器学习微服务。每个组件都是完全可执行的,彼此独立,需要明确定义的输入和输出。
设计的第一部分规定了机器学习应用的功能性和非功能性需求。确定的需求构成了机器学习应用的架构设计。此外,需求将决定生产策略,并对机器学习应用进行具体测试。
在机器学习中运用软件开发项目的经验。
由于输入数据和调整参数对随机机器学习的应用比确定性应用有更大的影响,因此机器学习就不同。然而,你将会发现你过去的大部分软件工程方法和最佳实践都适用于你的机器学习项目。
我们看到了很多因为前期工作研究不到位而不得不重新启动项目的例子。
对于较小规模的项目,一个开箱即用的解决方案可能就足够了。不幸的是,为了确保在竞争中的领先优势,可能需要定制功能或多个机器学习模型组合。
由于自然语言处理应用在近两年发生了显著的变化,我们决定在本文中加入孤立的最佳实践。
我们曾在 2017 年部署了基于 GLOVE 的自然语言处理应用 。2018 年出现了 BERT Transformer。通过两个关键的改进,BERT 带来了自然语言处理性能的大跃进:
BERT 被预先训练在一个语料库大小至少 4 个数量级(10000 倍),比我们的基于 GLOVE 的机器学习模型更加巨大;
BERT 的模型参数的数量比我们基于 GLOVE 的 ML 模型大两个数量级(100 倍)。
无论机器学习应用有多成功,在项目过程中都会出现一些小问题。我们已经找到了一份提供给客户项目发起人和经理的 1~2 页的每周状态报告,即使他们没有要求这么做,但这可以消除项目中的大部分沟通错误。
无论你在项目中的位置如何,你的要求都是错误的,你需要停下来并重新评估。做好重新开始或者被解雇的准备。记录你新提出的解决方案。人生苦短,无法继续推出一个需要解决问题的机器学习应用解决方案。
陷阱 8 与陷阱 7 类似。由于你正确地处理了业务用例,所以我们把它列在这里,但目前业务需求的优先级不高,或者消失了。这样的话,你唯一能做的就是提出不同的需求,去满足它们。要做好走人的准备。
早些时候,我们举办了《如何从机器学习中获益?》(How to benefit from Machine Learning?)课程。现在,我们将这些课程指向 Github、Coursera 和 Medium 博客上的 Awesome-X URL。
但我们不会放弃幻灯片,因为我们还是会经常用到它。
对于“我们没有 ML 部署基础设施”这个问题,我们只有一个答案(可行的解决方案),那就是去获取一个云账户。
推出自己的基础设施是可以做到的。Apple、Amazon、Google、IBM、Zillow 和其他数十亿(或数万亿)的公司都已经做到了。我们的答案是:去获取一个云账户。
Google Cloud Platform(GCP)是基于云端部署机器学习模型的主要选择之一。其他选择有 AWS、Microsoft Azure、Paperspace 等。
机器学习的最新进展正在发生,并且正在加速。你不想被另一个 BERT 类的事情蒙蔽双眼。
要及时掌握最新文献。你还可以向你的客户宣传全新的、优秀的机器学习项目。
我们是从外部顾问的角度为客户设计机器学习应用而写的本文。但是,如果你是负责设计机器学习应用解决方案的内部员工或团队,那么本文提到的所有陷阱和最佳实践都同样适用。
人工智能 1.0 行业的第一波浪潮在 20 世纪 80 年代末可以说是失败的。人工智能 1.0 行业由于难以推出强大的生产机器学习应用而夭折。
人工智能 2.0 行业之所以取得成功,是因为强大的生产机器学习应用的推广和日常使用。我们预计成功将会持续增长,人们在生活中使用机器学习,甚至都没有意识到这一点(尽管存在营销行为)。
但愿这些陷阱和最佳实践能帮助你设计机器学习应用,并使它们成功地投入到生产环境中。
我们将详述在机器学习项目生命周期的开发和部署阶段遇到的更多陷阱。此外,我们还将列出我们用来摆脱困境的最佳实践。我们在后续博文中完成这一任务。
-
点个在看少个 bug
以上是关于机器学习应用设计阶段的 10 个陷阱和 11 个最佳实践的主要内容,如果未能解决你的问题,请参考以下文章