利用机器学习进行人脸468点的3D坐标检测,并生成3D模型
Posted 启示AI科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用机器学习进行人脸468点的3D坐标检测,并生成3D模型相关的知识,希望对你有一定的参考价值。
上期文章,我们分享了,MediaPipe Face Mesh是一种脸部几何解决方案,即使在移动设备上,也可以实时估计468个3D脸部界标(dlib才能检测出68点)。它采用机器学习(ML)来推断3D表面几何形状,只需要单个摄像机输入,而无需专用的深度传感器。该解决方案利用轻量级的模型架构以及整个管线中的GPU加速,可提供对实时体验至关重要的实时性能。本期我们介绍一下代码如何实现

MediaPipe Face Mesh
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_face_mesh = mp.solutions.face_mesh
# 静态图片
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=True,
max_num_faces=1,
min_detection_confidence=0.5)
drawing_spec = mp_drawing.DrawingSpec(thickness=2, circle_radius=1)
drawing_spec1 = mp_drawing.DrawingSpec(thickness=2, circle_radius=1,color=(255,255,255))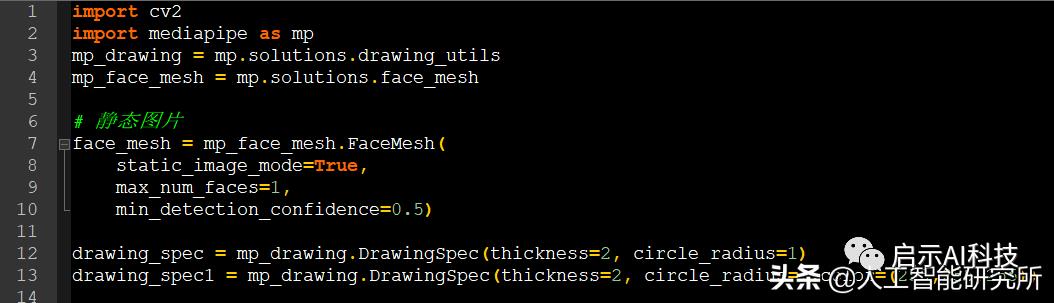
代码截图
首先导入需要的第三方库,mediapipe的安装,直接在cmd命令框中输入
python –m pip install mediapipe 安装即可然后我们定义了一个绘图方法,此方法定义了我们需要画图的线的粗细,颜色等信息,还记得我们前期分享holistic检测时,哪里由于没有配置线的粗细,导致我们的人脸识别的468个点密密麻麻的铺满了整个人脸,这里便可以修改一下
我们使用mp.solutions.drawing_utils下的DrawingSpec方法来定义线的粗细,颜色信息等,此方法接受三个参数,分别是color,thickness,circle_radius,我们可以利用此方法定义我们连接线的粗细已经颜色,定义468点的圆心大小,颜色等
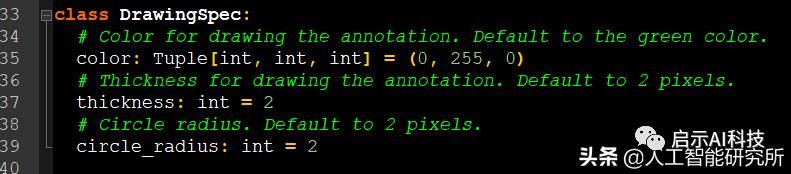
代码截图
然后使用mp_face_mesh.FaceMesh方法定义一个人脸检测器与人脸mesh器,此方法接受4个参数
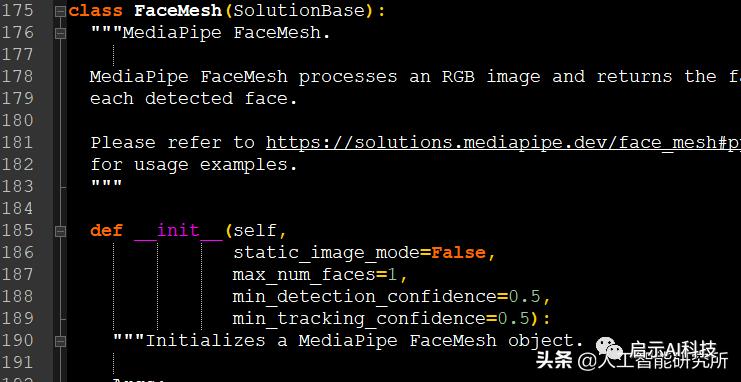
代码截图
STATIC_IMAGE_MODE
如果设置为false,则解决方案会将输入图像视为视频流。它将尝试检测第一个输入图像中的人脸,并在成功检测后进一步定位人脸地标。在随后的图像中,一旦检测到所有面孔并定位了相应的面孔地标,它便会简单地跟踪这些地标,而无需调用另一次检测,直到失去对任何面孔的跟踪为止。这减少了等待时间,是处理视频帧的理想选择。如果设置为true,则脸部检测在每个输入图像上运行,非常适合处理一批静态的,可能不相关的图像。默认为false。
MAX_NUM_FACES
要检测的最大脸数。默认为1。这里也解释了为什么我们分享holistic时 ,检测多人时,只检测了一个人脸,这里需要设置一下
MIN_DETECTION_CONFIDENCE
[0.0, 1.0]来自人脸检测模型的最小置信度值()被认为是成功检测。默认为0.5。
MIN_TRACKING_CONFIDENCE
[0.0, 1.0]来自地标跟踪模型的最小置信度值()将被视为已成功跟踪的人脸地标,否则将在下一个输入图像上自动调用人脸检测。将其设置为较高的值可以提高解决方案的健壮性,但代价是要增加延迟。如果为true,则忽略该,其中人脸检测仅在每个图像上运行。默认为0.5。
最后函数返回一个MULTI_FACE_LANDMARKS参数
检测/跟踪的面,其中,每个面被表示为468米的地标列表以及每个界标由收集x,y和z。x和y分别[0.0, 1.0]通过图像的宽度和高度进行归一化。z代表地标深度,以头部中央的深度为原点,值越小,地标越靠近相机。的z使用量级与大致相同x。
image = cv2.imread('2.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_mesh.process(image)
annotated_image = image.copy()
代码截图
随后,我们打开一张需要检测的图片,并把图片转换到RGB空间,然后使用process方法对图片进行检测,此方法返回所有的人脸468个点的坐标,有了这468个点的坐标,我们便可以遍历所有点,然后进行人脸mesh的绘制
for face_landmarks in results.multi_face_landmarks:
print('face_landmarks:', face_landmarks)
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACE_CONNECTIONS,
landmark_drawing_spec=drawing_spec,
connection_drawing_spec=drawing_spec1)
cv2.imshow('annotated_image',annotated_image)
cv2.waitKey(0)
cv2.imwrite('111.png', annotated_image)
face_mesh.close()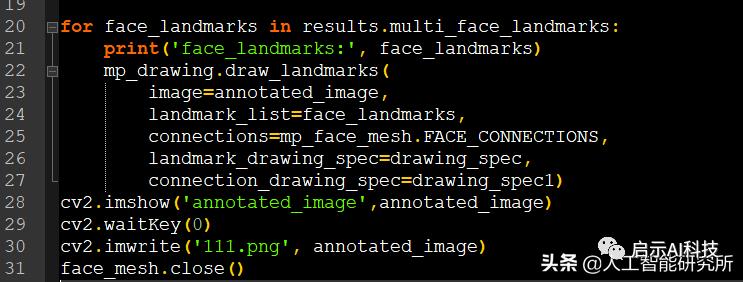
代码截图
我们使用for循环遍历所有的468个点,然后使用draw_landmarks方法画图,此方法接受5个参数
1、 image,需要画图的原始图片
2、 landmark_list 检测到的人脸坐标
3、 connections,连接线,需要把那些坐标连接起来
4、 landmark_drawing_spec,坐标的颜色,粗细
5、 connection_drawing_spec连接线的粗细,颜色等

代码截图
遍历完成后,便可以生成人脸的mesh网络了
Mesh人脸468点网络的视频实现
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(
min_detection_confidence=0.5, min_tracking_confidence=0.5)
drawing_spec = mp_drawing.DrawingSpec(thickness=2, circle_radius=1)
drawing_spec1 = mp_drawing.DrawingSpec(thickness=2, circle_radius=1,color=(255,255,255))
cap = cv2.VideoCapture(0)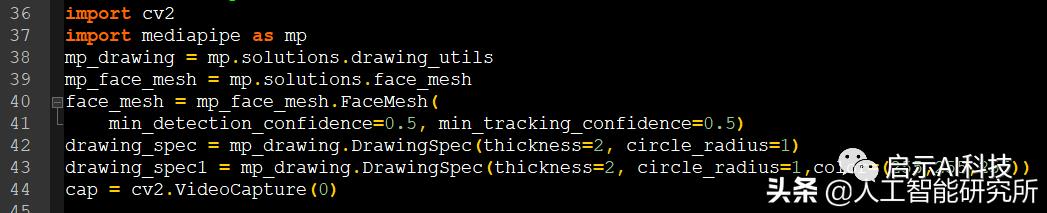
代码截图
对于实时视频,代码跟图片检测几乎一致,这里我们需要设置STATIC_IMAGE_MODE检测模型为视频,而不是图片,然后打开我们电脑的默认摄像头,进行视频帧的抓取
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = face_mesh.process(image)
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACE_CONNECTIONS,
landmark_drawing_spec=drawing_spec,
connection_drawing_spec=drawing_spec1)
cv2.imshow('MediaPipe FaceMesh', image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
face_mesh.close()
cap.release()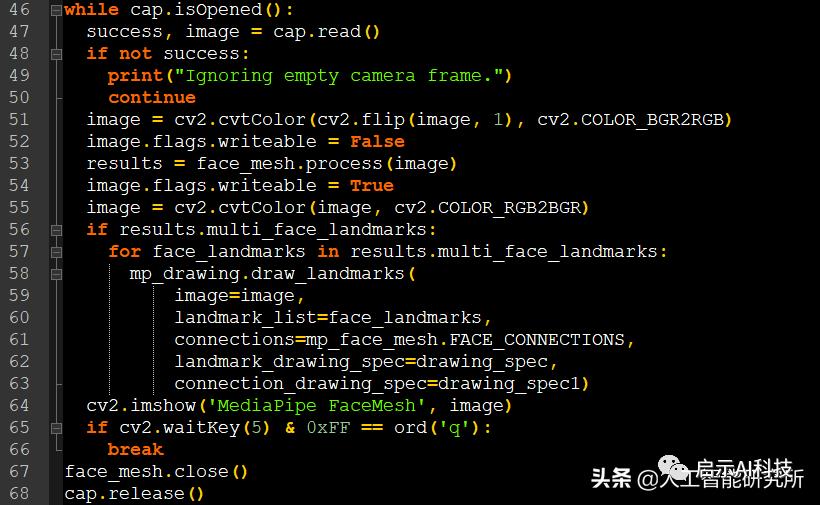
代码截图
待视频帧的图片抓取后,就可以使用图片识别的方法进行图片的检测,并实时把检测结果显示在视频里面了
以上是关于利用机器学习进行人脸468点的3D坐标检测,并生成3D模型的主要内容,如果未能解决你的问题,请参考以下文章
Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
Mediapipe入门——搭建姿态检测模型并实时输出人体关节点3d坐标