论文分享:ClueFinder——借助NLP辅助分析Android第三方Lib
Posted 上海交大软件安全研究组GoSSIP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文分享:ClueFinder——借助NLP辅助分析Android第三方Lib相关的知识,希望对你有一定的参考价值。
说明: 本文是NDSS 2018的论文Finding Clues for Your Secrets: Semantics-Driven, Learning-Based Privacy Discovery in Mobile Apps的阅读笔记, 作者Yuhong Nan, Zhemin Yang, Xiaofeng Wang, Yuan Zhang, Donglai Zhu 与Min Yang, 阅读笔记由上海交大GoSSIP软件安全小组温昊煌提供。
1. Abstract
文章出发点在于,目前的app主要都是以后台web服务+前端app构成,信息的传递过程复杂而难以定位。目前对于敏感信息的定位主要集中在定位系统级别的API上,但是这显然是远远不够的。app中可以得到的变量名、方法名、常量等等命名方式都是有其意义的,我们可以根据语义更有效地定位我们想要的敏感信息(即使app有轻微的混淆)。因此,文章提出了一种自然语言处理(NLP)的方法来自动定位我们感兴趣的信息源(变量、方法等),并且利用设计的一种基于学习的程序结构分析来筛选出真正含有敏感信息的内容。
2. Overview
2.1 语义证据发掘
它首先通过关键词、前缀、缩写等表示方法来识别出可能包含敏感信息的内容。例如方法、变量等。 得到这些元素之后,利用NLP技术进行过滤,过滤出真正含有敏感信息的元素。这里文章举了两个例子:“getStreetViewActivity”和”invalid_input_for_home_directory”,看起来像是相关,实则不然。因此这里我们需要根据语义来进行初步筛选。
2.2 基于学习的识别
仅仅基于语义做出判断是不科学的,我们还要结合语境上下文等因素做出判别,这时候我们需要一种基于学习的识别方式。(eg formatInvalidExp(“username”, Exception e)) 作者总共找出了5个特征训练出了一个SVM模式来帮助判别元素中是否含有真正的敏感信息。
2.3 实验结果
作者收集了44w+个app进行大规模分析。结果表明,有26.5%的app将用户隐私泄漏给其他lib,比之前的其他相关研究的数据要高。此方法识别的覆盖范围和精确度都要比其他方法更高。
2.4 假设前提
作者假定研究的app都没有被严重地混淆,仍然能从中提取有用的信息。实际上,app的开发者通常不会混淆数据相关的代码,因为这可能导致app的崩溃。research中表明50%的方法名没有被混淆。有高达98%的app都包含可读的字符串。
3. Design Of ClueFinder
执行流程:Locator反编译并找出可能含敏感信息elements——Checker通过NLP分析过滤掉一部分elements——Analyzer程序结构分析——Tracer追踪隐私信息的传播。
3.1 Semantics Locator
35data item from Google Privacy Policies——定义为private content,包括下图的这些。
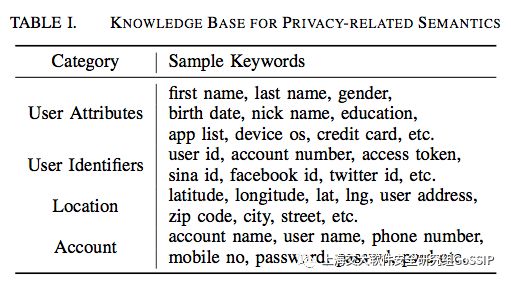
扩展词集方法: – 1. 利用word2vec找出同义词。 – 2. 通过stemming从1w+个google app中找出相近的词语(例如有相同前缀的词)
定位思路:拿到一个element,它会先分词把name分成一个个token(根据分隔符、大小写)。从这些token中,若是从词集中匹配出可能包含敏感信息的词汇,则标记此element,进行下一步的检查。
3.2 Semantic Checker
包括两部分:POS(part-of-speech)标记、依赖关系分析
Checker是基于Stanford Parser做的,著名的NLP tool,专门做POS tagging和dependency relation parsing。具体分析例子如下:

3.3 Structure Analyzer
程序结构分析:通过一种叫Jimple的中间语言。
根据一系列的程序结构特征来判断一个敏感的token是否真正触碰到了用户的敏感信息。 观察得出的结论:在数据读写的操作中的elements几乎都与敏感的信息有关。
基于此观察,作者主要关注上述步骤得出的element在其调用语句中是怎样被使用的,以此来分析是否确实存在敏感信息的操作。
步骤1: 定位直接或间接与element相关的method invocation。
步骤2: 提取方法特征,通过机器学习分析判断。 主要基于以下这些特征
-方法名中一些get/set/put/insert等可能进行data操作的关键token。
-参数类型,主要关注data相关的,例如String、HashMap、Json。
-返回类型,与参数类似。
-base value类型,针对一些类的数据读写操作。例如hashMap.put和Log就是需要我们区分开。
-常量,例如hashMap.put(“user”, $u), hashMap.put(“user”, “default”), 两者就是不同概念,因为前者输入了一个疑似user名的参数,而后者仅仅是个常量而已。
基于上述特征,Structure Analyzer通过训练一个SVM分类器来进行分析判断。训练样本使用了随机选择并人工标注的4326条语句。
3.4 Leakage Tracker
在追踪敏感信息的流向时,文章主要关注不受信任的三方库,因为如果要追踪所有的库对于大规模分析而言成本太高。当数据流入这些不受信任的库时,它们存在着被泄漏给第三方的风险。 对此,Tracker从上述得到的element中抽取数据相关的object,并通过数据流进行分析。
4. Evaluation
4.1 环境配置
主要语言:Java Python 数据流分析:Flow-Droid NLP工具:Standford Parser SVM:Scikit-learn 硬件环境:32 core server Linux 2.6.32 kernal 64GB Mem
4.2 训练数据
4326条数据(一半positive一半negative,因为SVM在平衡的数据集下效果是最好的),来自100个Google Play下的主流app(AUG 2016 top list)。 利用locater和checker抽取elements——由两位android专家人工标注。当两者意见同为pos或者neg时才采用(所以本来有7354条,2163条neg)。
4.3 有效性
文章对4326条标记的数据进行十字交叉验证,准确率达92.7%,召回率(代表查全程度)97.2%,F1-Score(综合)94.8%。
然后对随机爬取的100个app组成unknown set进行测试并人工验证,准确率达91.5%(没有召回率是因为人工遍历所有样本太花时间了)。这部分分析花了97min(平均每个app小于1min)。
对于错误判断的例子,作者指出这些都是稀有的个例:
False Positive: 函数名明明叫做saveAppKeyAndSecret也接受了key和secret却没有做什么save之类的敏感的操作,纯标题党= =
False Negative: outlier的干扰。例如一些app中会用1和-1表示gender,而我们一般假定gender是用string表示。
4.4 代码混淆
在上述进行实验的unkonwn set中约有11.3%(426/3775)的语句是被混淆处理过(Proguard)。然而这不一定影响到CludFinder,因为它是根据多个特征来进行判断分析的,除方法名外还有返回值、参数类型等也正影响。 系统级别的方法、数据相关的模块、第三方SDK经常保留了原来的代码,为了程序的正常执行。因此许多重要的语义信息都得到了保留。
4.5 性能对比
作者将ClueFinder与现有的几种类似工具做比较:API-based Labeling、UI-based labeling、Semantics-based taint tracking。结果显示CludFinder有以下优点:覆盖率更高、识别准确率跟高、分析时间更短。
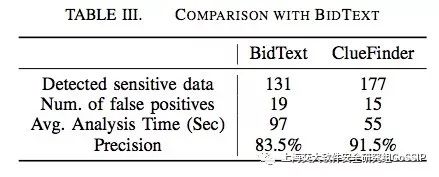
与BidText工具(也是一种基于语义的分析跟踪工具)的性能对比如下:
4.6 大规模泄漏研究
报告对44w+app的分析与测量结果进行大规模泄漏研究
A. 测量指标设置
泄漏风险:主要关注将敏感数据泄漏给第三方库,不考虑泄漏给Internet(因为难以从静态分析得出)
收集app:测试样本的app主要从google play和tencent android market下载 Leakage Tracker的实现:分析敏感数据的流向,判断流向的API包名/方法名是属于app的还是属于第三方库的(例如com.facebook.xxx从前缀判断)。
B. 测量结果
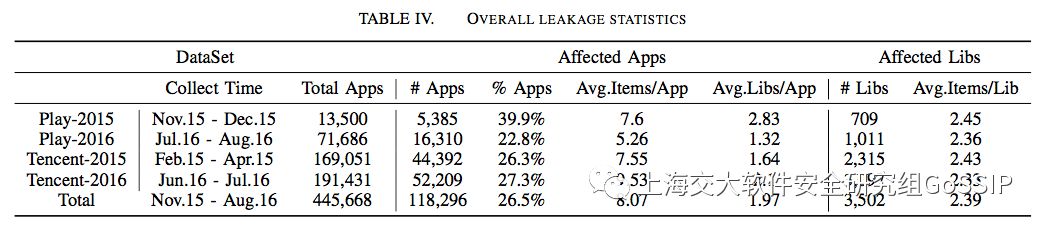
总共有118296个app(26.5%)泄漏敏感数据到3502个第三方库。平均泄漏8.07项数据到1.97个库。表明信息的泄漏还是比较普遍的。
得出的几个结论:
Google Play2015年的应用中泄漏隐私数据最高,达到40%,这一情况在2016有所好转。
经过随机的抽查,发现抽查的100个app中有59个的确通过网络形式将隐私信息泄漏,这一数据还应该更高,因为许多其他手段作者无法探测。
第三方应用市场的应用(例如tencent market)引入第三方的库更多,根源在于其审查机制没有Google那么严格。
第三方库分布和泄漏类型:大部分收集用户信息的库都是一些广告、分析等类型的库。
泄漏信息类型:如下表所示。许多app不一定直接通过系统API来收集信息,它们有可能从其他信息源(database、sp等)间接获取敏感信息,避免频繁调用API而造成用户或者审查的怀疑(真是费尽心思啊…)。并且,许多app收集了许许多多奇怪的信息(例如app list),而这些信息它们应该是不需要的。
5. After-thoughts
这篇文章的方向还是挺有意思的,NLP与安全的结合给了我们找出泄漏线索的新思路。亮点在于,这种方法相比此前的工作覆盖率更广、准确率更高。文章的工作一共收集了44w+个app进行实验,规模相当之大。它的实验工作也做得比较到位:从泄漏数量、信息种类、库的种类,到工具的效率,数据一应俱全,具有相当的说服力。也难怪文章50%的篇幅都是在讲evaluation的工作。
至于说实现部分,文章大概提供了一个框架式的思路。它都是从已有的轮子出发(Stanford的NLP Parser、python的scikit-learn等等)。这些方法是否拥有最好的效果,我们尚未知晓,因为文章没有对各种learning的算法进行比较。这可能是可以挖掘的一点(虽然已经是跨到ML领域的事情了)。但至少从目前的效果看,90%的准确率还是相当不错的。
对我们现有的工作而言,NLP和基于学习的做法也是一种更好的思路。当前的做法主要通过字符串匹配的方式来寻找我们感兴趣的加密或解密方法。在实战过程中,发现其中其实有许多不必要的方法也被过滤了进来。这使得在大规模分析中寻找我们感兴趣的方法的工作量有所增加。从这个角度上说,如果能借鉴文章中提到的NLP思路来分析函数名称并且能够通过基于学习的程序分析的方法来进一步筛选,我们将能够进一步精确地提取到我们需要的信息。将安全与人工智能相结合的方法,我感觉也是未来可以挖掘的点之一。
以上是关于论文分享:ClueFinder——借助NLP辅助分析Android第三方Lib的主要内容,如果未能解决你的问题,请参考以下文章