NLP讯飞英文学术论文分类挑战赛Top10开源多方案--6 提分方案
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP讯飞英文学术论文分类挑战赛Top10开源多方案--6 提分方案相关的知识,希望对你有一定的参考价值。
目录
1 相关信息
2 引言
在该次英文文本分类任务中,数据增强在bert中带来了0.1的增益,伪标签在bert中带来了0.2+增益,在TextCNN等传统深度学习模型,带来了0.3+的增益。但是数据增强在传统深度学习模型并没有带来增益。投票融合也带来0.1+的增益。Stacking也带来了增益,但是本次任务中,没有完全正确实现,也带来了0.1+的增益,但是没有投票融合的效果好。
3 提分技巧及实现
3.1 数据增强
参考队友写的文章NLP 英文文本数据增强
- 第一种方式:英文文本随机删除、同义词替换、随机插入、随机交换
########################################################################
# 随机删除
# 以概率p删除语句中的词
########################################################################
#这里传入的sentences是一个英文句子
def random_deletion(sentences, p):
words = sentences.split()
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return " ".join(new_words)
########################################################################
# 随机交换
# 随机交换几次
########################################################################
#这里传入的sentences是一个英文句子
def random_swap(sentences, n):
words = sentences.split()
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return " ".join(new_words)
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
########################################################################
# 同义词替换
# 替换一个语句中的n个单词为其同义词
########################################################################
from nltk.corpus import stopwords#引入停用词,因为对停用词进行数据增强相当于没有增强
from nltk.corpus import wordnet as wn#引入同义词
import random
stop_words=stopwords.words('english')
for w in ['!',',','.','?','-s','-ly','</s>','s']:
stop_words.add(w)
words = sentences.split()
def synonym_replacement(sentences, n):
words = sentences.split()
new_words = words.copy()
random_word_list = list(set([word for word in words if word not in stop_words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(synonyms)
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
sentence = ' '.join(new_words)
new_words = sentence.split(' ')
return " ".join(new_words)
#获取同义词
def get_synonyms(word):
nearbyWordSet=wn.synsets(word)
return nearbyWordSet[0].lemma_names()
- 第二种方式:互译,翻译成其他语言,再翻译回英文
#经过测试,这个翻译的包翻译的时间是最短的
from pygtrans import Translate
#这里传入的sentences是一个英文句子
def backTran(sentences):
client = Translate()
text1 = client.translate(sentences)
text2 = client.translate(text1.translatedText, target='en')
return text2.translatedText
- 使用方法
train_trans = pd.read_csv('./data/train.csv',sep="\\t")
test = pd.read_csv('./data/test.csv', sep='\\t')
aug_train = pd.DataFrame(columns=['title','abstract','categories'])
aug_test = pd.DataFrame(columns=['title','abstract'])
# 互译处理,其他处理方式也一样
aug_train["title"] = train["title"].progress_apply(lambda x: backTran(x))
aug_train["abstract"] = train["abstract"].progress_apply(lambda x: backTran(x))
aug_test["title"] = test["title"].progress_apply(lambda x: backTran(x))
aug_test["abstract"] = test["abstract"].progress_apply(lambda x: backTran(x))
- 第三种方式:对抗训练
该方案只在传统的深度学习模型方案中使用,暂时不知如何在bert使用。有两种方法,分别是FGM和PGD。在本次任务中,PGD效果较为好一些,FGM通过实验没有带来任何增益。且加入对抗训练后,模型收敛变慢,需要加深训练深度,加大epoch.
原理参考队友文章NLP 英文文本数据增强
本次任务使用,参考Github源码
3.2 投票融合
(1)原理解析
我使用该方式的时候,已经用TextCNN、Fasttext、bert_base、bert_large、roberta_large分别得到了0.79+的结果。通过将提交结果文件放在同一个文件夹后。提交文件样式如下。
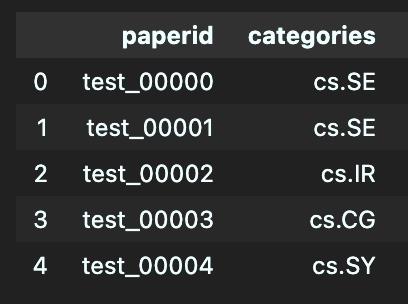
对categories列进行唯一类别特征编码,并命名为label。
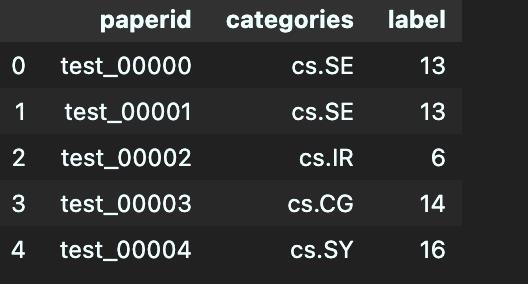
同理将多个提交结果都编码并存放到同一个csv文件中,如下所示。投票的原理就是每一行进行投票,多数者即为该行的label。如下第一行0是5列中全票,9995行,12的票数多余29的票数,该行的label为12。投票融合的条件是模型之间差异越大,融合效果越好。

(2)实现
import pandas as pd
import numpy as np
import os
from pprint import pprint
DATA_DIR = 'voting_data/'#'./ensemble_submit/8298/'
files = os.listdir(DATA_DIR)
files = [i for i in files if i[0]!='.']
print(len(files))
pprint(files)
# 读取原始文件进行编码
train = pd.read_csv('./data/train.csv', sep='\\t')
#将标签进行转换
label_id2cate = dict(enumerate(train.categories.unique()))
label_cate2id = {value: key for key, value in label_id2cate.items()}
# 读取提交文件,也可以自定义空的csv文件,该文件将会存储多个结果
sub_exp_df = pd.read_csv('./data/sample_submit.csv')
df_merged = sub_exp_df.drop(['categories'], axis=1)
for file in files:
tmp_df = pd.read_csv(DATA_DIR + file)
tmp_df['label'] = tmp_df['categories'].map(label_cate2id)
tmp_df = tmp_df.drop(['categories'], axis=1)
df_merged = df_merged.merge(tmp_df, how='left', on='paperid')
df_merged.head()
# 进行计票
def work(pres):
count = [0]*39
for i in pres:
count[i] += 1
out = count.index(max(count))
return out
tmp_arr = np.array(df_merged.iloc[:,1:])
# 转为list
label_voted = [work(line) for line in tmp_arr]
# 反编码,生成提交文件
sub_exp_df['categories'] = label_voted
sub_exp_df['categories'] = sub_exp_df['categories'].map(label_id2cate)
# 存储提交文件
savepatch = "./ensemble_submit/8279_voting.csv"
sub_exp_df = sub_exp_df.drop(['label'], axis=1)
sub_exp_df.to_csv(savepatch, index=False)
3.2 伪标签
参考伪标签(Pseudo-Labelling)——锋利的匕首
(1)原理解析
在文本分类任务中,在比赛最初是没法使用的,因为要获得准确的伪标签,一般选择多模型结果投票的方式获得高质量的标签。是在已经从多个方案中得到了较高的预测结果后,通过投票的方式得到高质量标签。具体来说,我使用该方式的时候,已经用TextCNN、Fasttext、bert_base、bert_large、roberta_large分别得到了0.79+的结果。利用以上的投票原理,选择多个模型都投票的数据作为该行数据的label。然后将该行数据加入到训练集中,重新训练模型。

注意:图中的第一个Model和第二个模型不是同一个模型,第二个Model是加入伪标签后重新训练出来的模型
(2)实现
Github源码下载
- 模型结果合并
import pandas as pd
import numpy as np
import os
from pprint import pprint
DATA_DIR = './submit/'
files = os.listdir(DATA_DIR)
files = [i for i in files if i[0]!='.']
print(len(files))
pprint(files)
train = pd.read_csv('./data/train.csv', sep='\\t')
#将标签进行转换
label_id2cate = dict(enumerate(train.categories.unique()))
label_cate2id = {value: key for key, value in label_id2cate.items()}
sub_exp_df = pd.read_csv('./data/sample_submit.csv')
df_merged = sub_exp_df.drop(['categories'], axis=1)
for file in files:
tmp_df = pd.read_csv(DATA_DIR + file)
tmp_df['label'] = tmp_df['categories'].map(label_cate2id)
tmp_df = tmp_df.drop(['categories'], axis=1)
df_merged = df_merged.merge(tmp_df, how='left', on='paperid')
df_merged.head()
- 构造高质量伪造标签
#计票。
def work_high(pres):
count = [0]*39
for i in pres:
count[i] += 1
p = 7 # 可根据融合模型的数量选择该数的大小。当共有8个模型融合,>7表示必须有8个模型都投票的才被选择加入伪标签数据
if max(count) >p:
out = count.index(max(count))
else:
out = -1
return out
tmp_arr = np.array(df_merged.iloc[:,1:])
label_voted = [work_high(line) for line in tmp_arr]
# 计算有多少数据不被加入伪标签数据
print(label_voted.count(-1))
# 读取测试集
test_data = train = pd.read_csv('./data/test.csv', sep='\\t')
test_data['categories'] = label_voted
test_data = test_data.drop(test_data[test_data['categories']==-1].index)
# 计算有多少伪标签数据
len(test_data)
# 反编码映射
test_data['categories'] = test_data['categories'].map(label_id2cate)
# 合并训练集
train = pd.read_csv('./data/train.csv')
# 存储新的训练集
pseudo_label_train = pd.concat([train,test_data])
model_name = "./data/pseudo_train_data"
pseudo_label_train.to_csv('{}.csv'.format(model_name),sep="\\t", index=False)
4 加快训练
4.1 混合精度训练
(1)引言
参考资料pytorch混合精度训练
使用fp16存储网络的权重值、激活值和梯度值进行网络训练,好处是:
减少显存占用:上面的图已经很明显的可以看出,fp16的存储空间为fp32的一半,如果使用fp16进行训练,那么可以减少一半的显存占用,因此也就可以使用更大的batchsize进行大模型的训练;
加快训练和推理速度:fp16可以提高模型的训练和推理的速度。
(2)实现
有两种方法实现,nvidia版本和pytorch版本。这里采用了第一种,其他的方案参考pytorch混合精度训练。实现只需要在pytroch代码上,修改三行代码即可
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
opt_level参数:
O0:纯FP32训练,可以作为accuracy的baseline;
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算;
O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算;
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline。
(3)具体实现
#训练模型
import torch.nn as nn
from apex import amp
def train_start(EPOCHS,MAX_LEN,BATCH_SIZE,train, test_data_loader, label_id2cate):
#模型定义
model = PaperClassifier()
model = model.to(device)
k_fold = 5
predict_all = np.zeros([10000,39])#存储测试集的 预测结果
for n in range(k_fold):
train_data_loader, val_data_loader = load_data_kfold(train, BATCH_SIZE,MAX_LEN, k_fold, n)
#使用差分学习率
parameters = get_parameters(model, 2e-5, 0.95, 1e-4)
optimizer = AdamW(parameters)
# fp16混合精度训练
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
total_steps = len(train_data_loader) * EPOCHS
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=0,
num_training_steps=total_steps
)
loss_fn = nn.CrossEntropyLoss().to(device)
best_accuracy = 0
for epoch in range(EPOCHS):
print(f'Epoch {epoch + 1}/{EPOCHS}')
print('-' * 10)
train_acc, train_loss = train_epoch(
model,
train_data_loader,
loss_fn,
optimizer,
device,
scheduler
)
print(f'Train loss {train_loss} accuracy {train_acc}')
val_acc, val_loss= eval_model(
model, val_data_loader, loss_fn, device)
print(f'Val loss {val_loss} accuracy {val_acc}')
if val_acc > best_accuracy:
torch.save(model.state_dict(), 'model/best_model_state_large_aug.bin')
best_accuracy = val_acc
#进行预测
y_pred = model_predictions(model, test_data_loader, device)
predict_all += np.array(y_pred)
test_x.extend(y_pred)
def train_epoch(model, data_loader, loss_fn, optimizer, device, scheduler):
print("start training!")
model = model.train()
losses = []
pred_ls = []
label_ls = []
for d in tqdm(data_loader):
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["labels"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
losses.append(loss.item())
# fp16混合精度训练
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
# loss.backward()
nn.utils.clip_grad_norm_(model.parameters(