美亚4.2星评数据分析经典之作重磅升级,Spark带你玩转数据分析!
Posted 图灵教育
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美亚4.2星评数据分析经典之作重磅升级,Spark带你玩转数据分析!相关的知识,希望对你有一定的参考价值。
今天是 2018 年上半年最后一个工作日,回想这半年,小伙伴们都做了哪些有意义的事情?实现技术上的飞跃、兴趣爱好的拓展亦或是感情路上的归宿?这半年来,图灵问世了很多图书,有火爆编程圈的《程序员的英语》、TensorFlow进阶第一书《深入理解TensorFlow》、区块链实战指南《区块链技术进阶与实战》以及最受读者喜爱的《Python3网络爬虫开发实战》,可以说是不胜枚举。上半年的最后一个工作日,小鹿决定把这本《Spark高级数据分析》的升级版送给大家,希望大家下半年继续奋进。
知乎上经常看到有小伙伴问:“学习 Spark 数据分析,要读哪些书?” 有人推荐了图灵出版的 Spark 入门书《Spark快速大数据分析》。其实除了它,还要推荐大家这本《Spark高级数据分析》。这本书第一版豆瓣评分 8.1,在美亚大数据分析/算法类图书中一直名列前茅,获得很多五星级好评,可见国外读者对该书的喜爱。此次的升级版在美亚也获得了 4.3 星好评,是排行榜前列为数不多的 Spark 图书。
当然,在豆瓣上,有人说这本书讲解得不够详细,其实呢它不算是一本入门书,是一本偏向应用方面的书,需要你进行动手操作实践。如果你了解 Scala 语言,还有一些统计学和机器学习基础,它绝对是你学习 Spark 时必备的图书之一!那没有也不要怕,我们先来了解一下这本书。
全书一共分为 11 章内容,前两章分别介绍了 Spark 以及如何用 Scala 和 Spark 进行数据分析,这两章是基础知识的相关介绍,如果你之前有所了解,可以直接跳到第三章开始。
从第三章开始,陆续讲解了 9 个运用 Spark 进行数据分析的模式。不要小看这 9 个模式哦!跟着练习,保证没错!本书涵盖模式如下:
● 用决策树算法预测森林植被
● 基于 K 均值聚类进行网络流量异常检测
● 基于潜在语义算法分析维基百科
● 用 GraphX 分析伴生网络
● 对纽约出租车轨迹进行空间和时间数据分析
● 通过蒙特卡罗模拟来评估金融风险
● 基因数据分析和 BDG 项目
● 用 PySpark 和 Thunder 分析神经图像数据
我们就以其中的三个模式为例给大家详细介绍一下。
想必小伙伴都有过这样的经历,在亚马逊上买了 Python 类的图书之后,网站就会接二连三地给你推荐类似的书。从经验上来讲,推荐引擎大体上属于大规模机器学习。大家对此都了解,而且大部分人在亚马逊上都见过。从社交网络到视频网站,再到在线零售,都用到了推荐引擎,大家也都知道推荐引擎。实际应用中的推荐引擎我们也能直接看到。虽然我们知道 Spotify 上是计算机在挑选播放的歌曲,但我们可不一定知道 Gmail 系统可以判断收件箱里的邮件是不是垃圾邮件。
相比其他的机器学习算法,推荐引擎的输出更直观,更容易理解。而这章主要讲述 Spark 中主要的机器学习算法。围绕推荐引擎展开,主要介绍音乐推荐。作者以一个音乐推荐系统 Audioscrobbler 为例,运用交替最小二乘推荐算法,来掌握用户的偏爱选择。





这一章主要是通过 MLlib 实现的聚类算法来介绍非监督学习技术。而聚类却是最有名的非监督学习方法,它试图找到数据中的自然群组。
K 均值聚类也许是应用最广泛的聚类算法。它试图在数据集中找出 k 个簇群,这里 k 值由数据科学家指定。k 是模型的超参数,其最优值与数据集本身有关。事实上,这章有一个关键点就是如何选择合适的 k 值。通过 K 均值聚类来对网络流量的异常形成检测。






这部分主要讲解 PySpark API。有了这个 API,小伙伴就可以通过 Python 与 Spark 交互。本章还会介绍一个 Thunder 项目,它构建在 PySpark 之上,目的是处理海量时间序列数据,特别是处理神经影像数据。
PySpark 是一个特别灵活的工具,可以帮我们进行探索式的大数据分析,它紧密集成 PyData 生态系统的其他工具,包括可视化工具 matplotlib,甚至是“可执行文档”工具 IPython Notebook(Jupyter)。
利用这些工具可以在一定程度上了解斑马鱼的大脑结构。利用 Thunder 可以对斑马鱼大脑的不同区域(代表不同神经元群组)进行聚类,这样就可以找到斑马鱼随时间变化的大脑活动模式。Thunder 是建立在 PySpark RDD API 上的,我们将继续使用它。



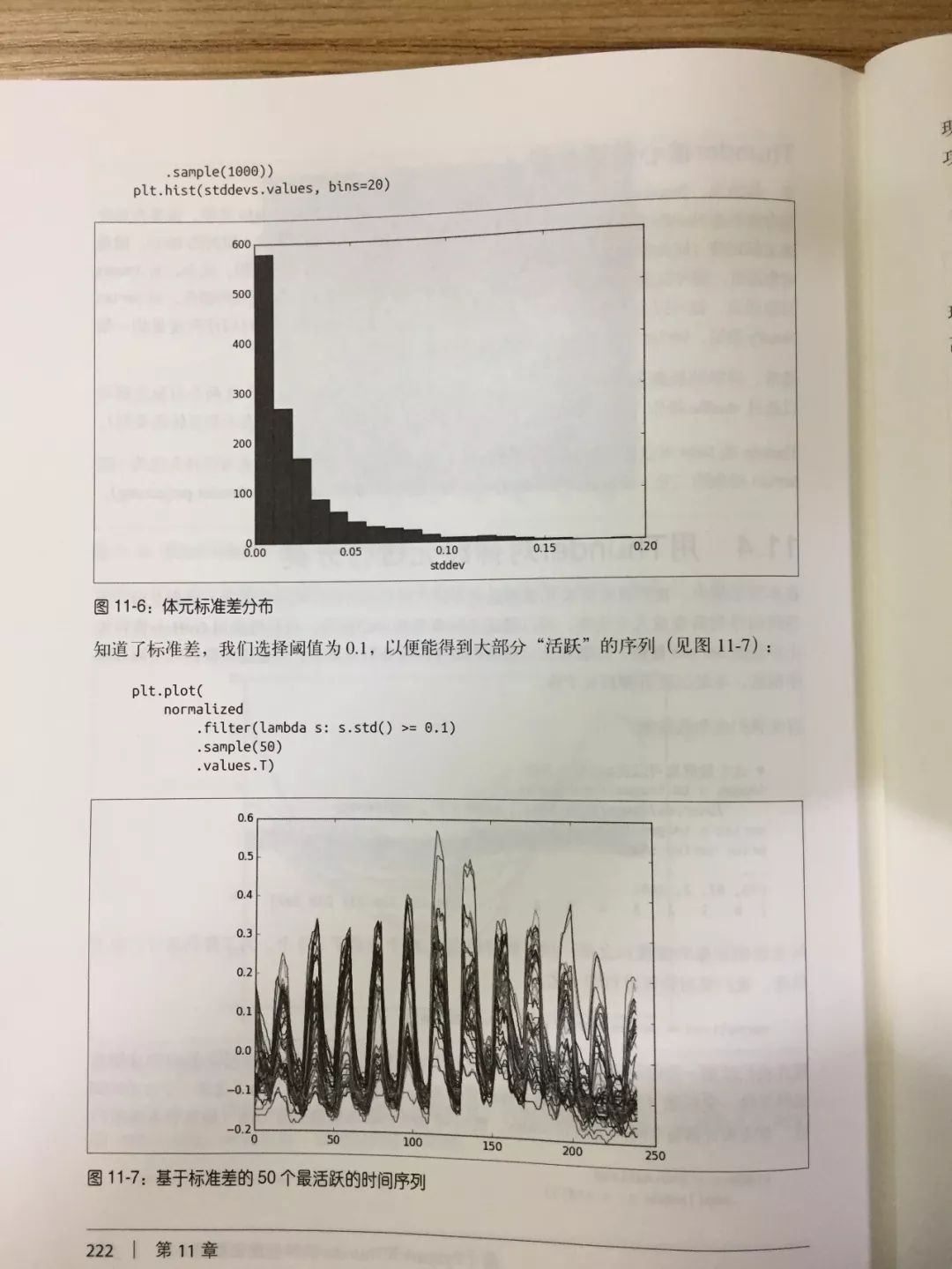
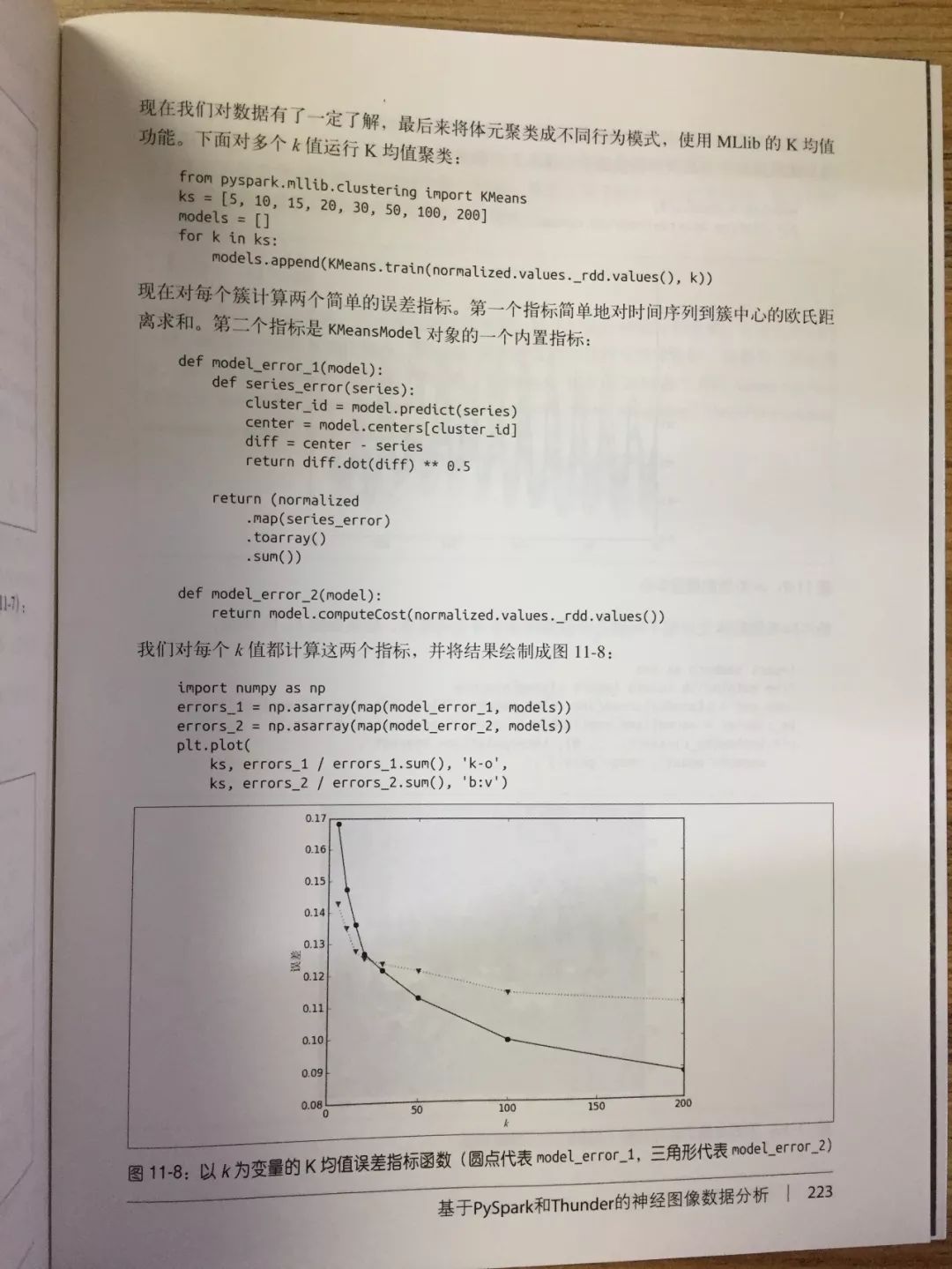
以上就是有关 3 个模式的介绍,看过之后是不是很想知道剩下那 6 个都是怎么操作的?那不如翻开书仔细研究一下。


知名数据公司 Cloudera 数据科学家联合执笔
Spark 大规模数据分析实战宝典
新版针对 Spark 近年来的发展,对样例代码和所使用的资料进行了大量更新
本书涵盖大规模数据分析中常用算法、数据集和设计模式。本书在第 1 版的基础上,针对 Spark 近年来的发展,对样例代码和所使用的资料进行了大量更新。新版 Spark 使用了全新的核心 API,MLlib 和 Spark SQL 两个子项目也发生了较大变化,本书为关注 Spark 发展趋势的读者提供了与时俱进的资料,例如 Dataset 和 DataFrame 的使用,以及与 DataFrame API 高度集成的 Spark ML API。
作译者简介
 目录
目录
第1章 大数据分析 1
1.1 数据科学面临的挑战 2
1.2 认识Apache Spark 4
1.3 关于本书 5
1.4 第2版说明 6
第2章 用Scala和Spark进行数据分析 8
2.1 数据科学家的Scala 9
2.2 Spark编程模型 10
2.3 记录关联问题 10
2.4 Spark shell和SparkContext 11
2.5 把数据从集群上获取到客户端 16
2.6 把代码从客户端发送到集群 19
2.7 从RDD到DataFrame 20
2.8 用DataFrame API来分析数据 23
2.9 DataFrame的统计信息 27
2.10 DataFrame的转置和重塑 29
2.11 DataFrame的连接和特征选择 32
2.12 为生产环境准备模型 33
2.13 评估模型 35
2.14 小结 36
第3章 音乐推荐和Audioscrobbler数据集 37
3.1 数据集 38
3.2 交替最小二乘推荐算法 39
3.3 准备数据 41
3.4 构建第一个模型 44
3.5 逐个检查推荐结果 47
3.6 评价推荐质量 50
3.7 计算AUC 51
3.8 选择超参数 53
3.9 产生推荐 55
3.10 小结 56
第4章 用决策树算法预测森林植被 58
4.1 回归简介 59
4.2 向量和特征 59
4.3 样本训练 60
4.4 决策树和决策森林 61
4.5 Covtype数据集 63
4.6 准备数据 64
4.7 第一棵决策树 66
4.8 决策树的超参数 72
4.9 决策树调优 73
4.10 重谈类别型特征 77
4.11 随机决策森林 79
4.12 进行预测 81
4.13 小结 82
第5章 基于K均值聚类的网络流量异常检测 84
5.1 异常检测 85
5.2 K均值聚类 85
5.3 网络入侵 86
5.4 KDD Cup 1999数据集 86
5.5 初步尝试聚类 87
5.6 k的选择 90
5.7 基于SparkR的可视化 92
5.8 特征的规范化 96
5.9 类别型变量 98
5.10 利用标号的熵信息 99
5.11 聚类实战 100
5.12 小结 102
第6章 基于潜在语义分析算法分析维基百科 104
6.1 文档-词项矩阵 105
6.2 获取数据 106
6.3 分析和准备数据 107
6.4 词形归并 109
6.5 计算TF-IDF 110
6.6 奇异值分解 111
6.7 找出重要的概念 113
6.8 基于低维近似的查询和评分 117
6.9 词项-词项相关度 117
6.10 文档-文档相关度 119
6.11 文档-词项相关度 121
6.12 多词项查询 122
6.13 小结 123
第7章 用GraphX分析伴生网络 124
7.1 对MEDLINE 文献引用索引的网络分析 125
7.2 获取数据 126
7.3 用Scala XML工具解析XML文档 128
7.4 分析MeSH主要主题及其伴生关系 130
7.5 用GraphX来建立一个伴生网络 132
7.6 理解网络结构 135
7.7 过滤噪声边 140
7.8 小世界网络 144
7.9 小结 150
第8章 纽约出租车轨迹的空间和时间数据分析 151
8.1 数据的获取 152
8.2 基于Spark的第三方库分析 153
8.3 基于Esri Geometry API和Spray的地理空间数据处理 153
8.4 纽约市出租车客运数据的预处理 157
8.5 基于Spark的会话分析 165
8.6 小结 168
第9章 基于蒙特卡罗模拟的金融风险评估 170
9.1 术语 171
9.2 VaR计算方法 172
9.3 我们的模型 173
9.4 获取数据 173
9.5 数据预处理 174
9.6 确定市场因素的权重 177
9.7 采样 179
9.8 运行试验 182
9.9 回报分布的可视化 185
9.10 结果的评估 186
9.11 小结 188
第10章 基因数据分析和BDG项目 190
10.1 分离存储与模型 191
10.2 用ADAM CLI导入基因学数据 193
10.3 从ENCODE数据预测转录因子结合位点 201
10.4 查询1000 Genomes项目中的基因型 207
10.5 小结 210
第11章 基于PySpark和Thunder的神经图像数据分析 211
11.1 PySpark简介 212
11.2 Thunder工具包概况和安装 215
11.3 用Thunder加载数据 215
11.4 用Thunder对神经元进行分类 221
11.5 小结 225

扫一扫,京东购
扫一扫,当当购
扫一扫,亚马逊购
文末福利
本期送出 3 本《Spark高级数据分析(第2版)》,小伙伴来说说你与大数据的故事有哪些?你曾经分析过哪些数据?或者说说你眼中的数据分析应该是什么样子的?精选留言选出 3 位小伙伴获得赠书。
另外,作为上半年的最后一个工作日,你可以留言总结一下上半年都读了哪些书。小鹿还将挑选出 3 位小伙伴获得上半年图灵出版的任意图书一本。两种形式皆可,截止2018.7.3 12:00。
☟☟☟点击【阅读原文】查看大数据书单
以上是关于美亚4.2星评数据分析经典之作重磅升级,Spark带你玩转数据分析!的主要内容,如果未能解决你的问题,请参考以下文章
又一本经典重磅升级!豆瓣 8.5,搞透 Kafka 就看它了