美亚评分4.3 ,销量超过10万,Hadoop入门经典,带你玩转大数据
Posted 程序员书库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美亚评分4.3 ,销量超过10万,Hadoop入门经典,带你玩转大数据相关的知识,希望对你有一定的参考价值。
马云曾说过:“未来最大的资源就是数据,不参与大数据十年后一定会后悔!”
Hadoop 最早诞生于 2006 年,并在 2008 年成为 Apache 顶级项目,起初,Hadoop在中国基本没有人注意到它,直到2011年开始,中国进入大数据风起云涌的时代,因为能够高效地处理大数据,以Hadoop为代表的家族软件,占据了大数据处理的庞大市场,继而成为大数据开发的标准。
不仅如此,它还孕育了包括 HBase、Hive、ZooKeeper 等一系列知名 Apache 顶级项目,而这些项目一开始都是以 Apache Hadoop 子项目的形式在社区运作并为开发者熟知的。
Hadoop至今已经发展12年了,在许多国内外企业的大数据平台中,Hadoop生态的各类组件都占据了相当大的比例,然而,在很多开发者眼里,Hadoop复杂且难以掌握,因此,在许多社交论坛上,经常可以看到许多Java、安卓开发者都在问想学习Hadoop大数据,应该看哪些书?
这本书在美亚上获得许多五星级好评,综合获得4.3星的高分,由此可见国外读者对其的肯定。本书第三版豆瓣评分 7.6,稍逊于美亚评分。

本书特点
● 美亚评分4.3
● 融技术性、知识性、前沿性于一体
● 大而全的介绍了Hadoop这一高性能的数据分析平台
本书从Hadoop的缘起开始,由浅入深,结合理论和实践,并通过案例学习来展示如何用Hadoop解决特殊问题。
通过它,你可以从学到以下内容:
● 使用Hadoop分布式文件系统(HDFS)来存储海量数据集,通过MapReduce对这些数据集运行分布式计算..
● 熟悉Hadoop的数据和I/O构件,用于压缩、数据集成、序列化和持久处理
● 洞悉编写MapReduce实际应用程序时常见陷阱和高级特性
● 设计、构建和管理专用的Hadoop集群或在云上运行Hadoop
● 使用Pig这种高级的查询语言来处理大规模数据
● 利用HBase这个Hadoop数据库来处理结构化和半结构化数据
● 学习Zookeeper,这是一个用于构建分布式系统的协作原语工具箱
此外,第3版还覆盖Hadoop的最新动态,包括新增的MapReduceAPI,以及MapReduce2及其灵活性更强的执行模型(YARN)。
详细目录如下:

通过目录,可以把本书分为5部分:
第Ⅰ部分:介绍Hadoop 基础知识
第Ⅱ部分:介绍MapReduce
第Ⅲ部分:介绍Hadoop 的运维
第Ⅳ部分:介绍Hadoop 相关开源项目
第Ⅴ部分:提供了三个案例,分别来自医疗卫生信息技术服务商塞纳(Cerner)、微软的人工智能项目ADAM(一种大规模分布式深度学习框架)和开源项目Cascading(一个新的针对MapReduce 的数据处理API)。
读者书评:
@三十笔画:百科全书式,涉及面广,泛泛而谈
@一只黑眼睛看着大千世界:书很棒,全面又直接实用,中间不少地方解决了我之前遇到的难题。翻译不好,一些关键点,逻辑不顺,一看原文,甚至是说反了。内容基于2014年的hadoop2刚出现时,之后应该看第四版。
@无关风月:整个生态链都有介绍,宏观把控不错,感觉应用场景可以再多点和详细点
@john1king:内容非常全,主要章节看一遍下来还是有不少收获。不过中文版内容比较老,第三版新旧API一起介绍容易产生混乱
@风纪扣v:学习haddop都要买这本书吧,仔细读能有很大的收获,不过就是实践性不强,太偏理论了
美亚评论:
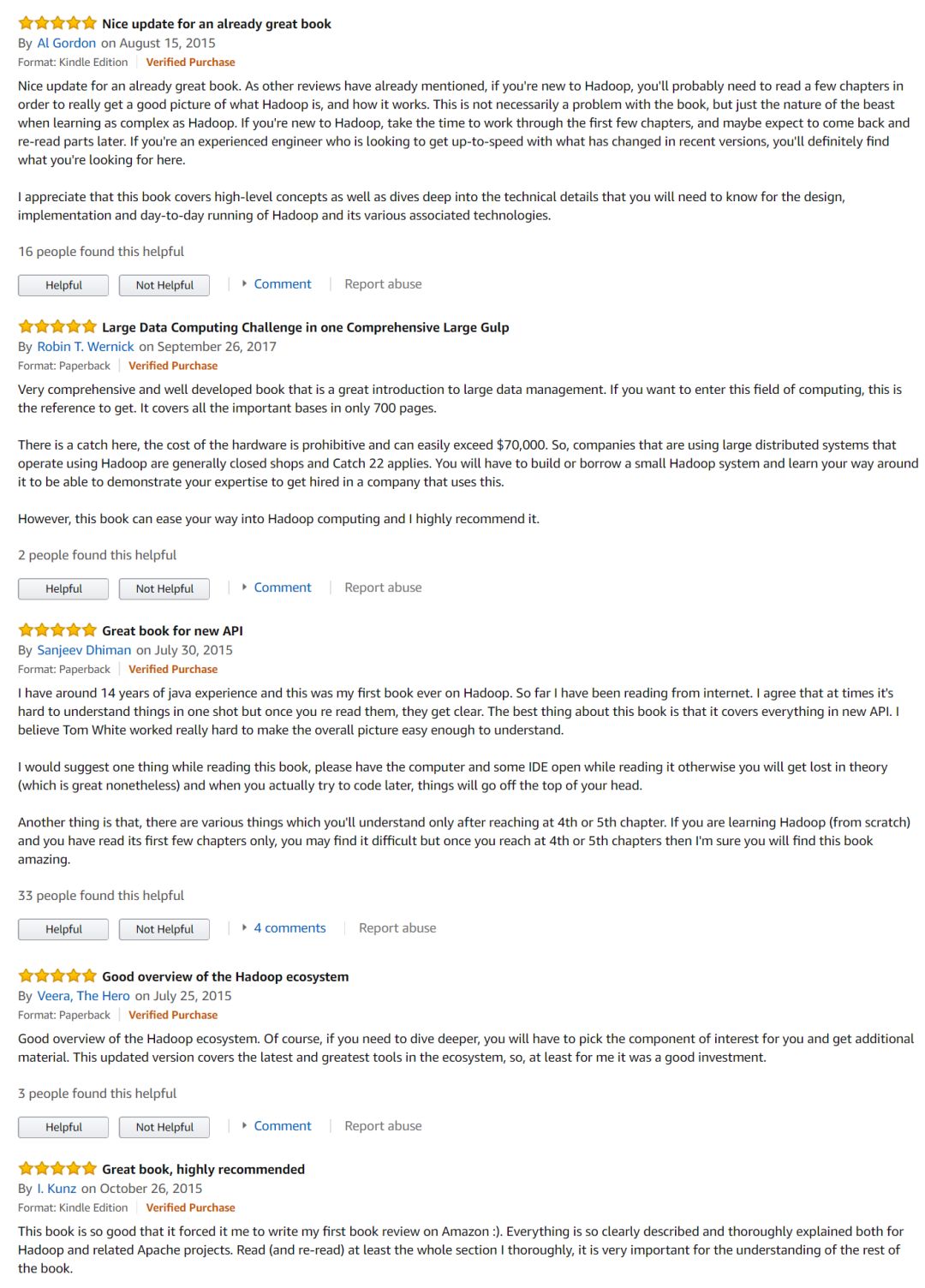
满屏的5星好评!
其他学习Hadoop的书
1、《Hadoop技术内幕》

共两册,分别从源代码的角度对“Common+HDFS”和“MapReduce的架构设计和实现原理”进行了极为详细的分析。
2、《Hadoop实战》
《Hadoop实战》分为3个部分,深入浅出地介绍了Hadoop框架、编写和运行Hadoop数据处理程序所需的实践技能及Hadoop之外更大的生态系统。
如果你还想知道大数据开发工程师除了Hadoop,还应该具备哪些技能,可点击阅读:
●输入m获取到文章目录
以上是关于美亚评分4.3 ,销量超过10万,Hadoop入门经典,带你玩转大数据的主要内容,如果未能解决你的问题,请参考以下文章