结果跟预期是反的怎么办?基于R语言的可视化数据分析(附详细操作视频免费查看)
Posted EmpowerStats
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结果跟预期是反的怎么办?基于R语言的可视化数据分析(附详细操作视频免费查看)相关的知识,希望对你有一定的参考价值。
临床上是个保护因素,自己数据做出来是个危险因素,是样本量不够大吗?还是数据质量不高?怎么办?
把“奇怪”的患者删掉。自己手动删数据,这跟造假、编数据没多大区别。不推荐。
扩大样本量。因为不知道为什么结果是反的,原因没有找到,盲目扩大样本量可能出力不讨好。不推荐。
基于R语言的可视化数据分析,看看高手是怎么做的吧。之前已分享了实例1:,继续看实例:
研究某指标A和非酒精性脂肪肝的关系。临床上认为指标A越高,非酒精性脂肪肝风险越高,即指标A是危险因素。然而研究者的数据得出的结果却是相反的,平滑曲线拟合结果如下:
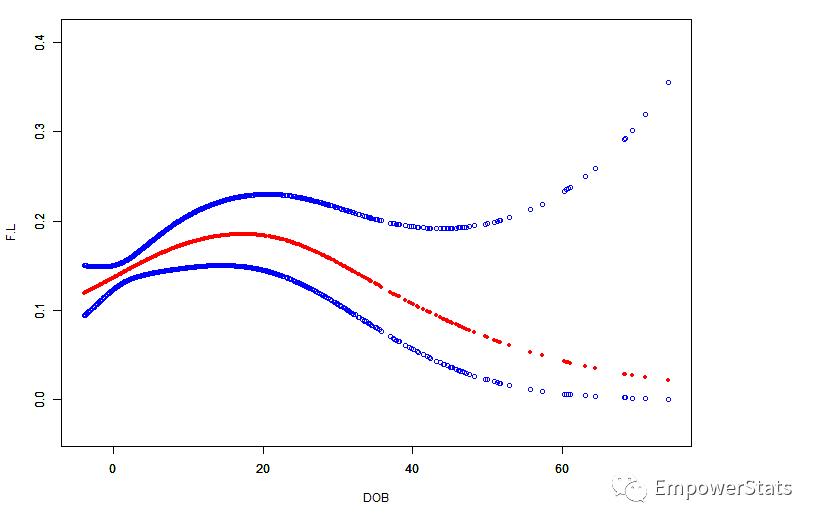
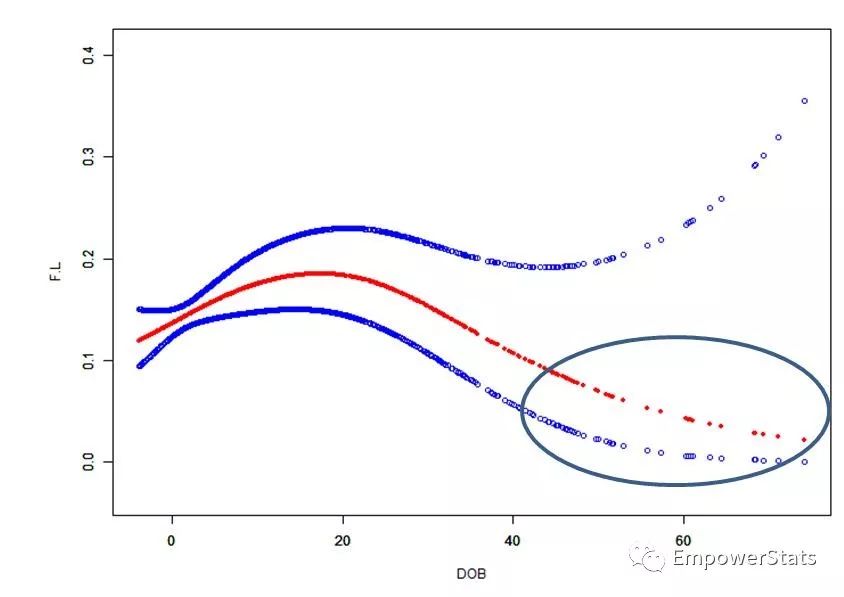
横坐标是指标A的水平,纵坐标为非酒精性脂肪肝发生的概率(1=有,0=无)。红色的是曲线拟合,两边蓝色的是95%CI。看图可知指标A高的人脂肪肝发生的概率反而低,这个临床解释不通啊。
问题就集中在右边圈出来的研究对象,是他们导致结果很奇怪。下一步,想把这些人拎出来看看,到底有什么特殊性。想法很简单,实现起来也不难。

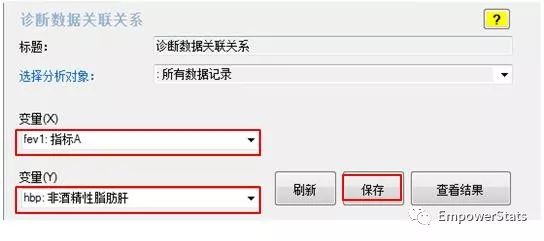
用易侕软件数据分析菜单下的“诊断数据关联关系”模块实现。把X(指标A)放在X里,把Y(非酒精性脂肪肝)放在Y里。点击查看结果。
结果出来了,可以看到按照非酒精性脂肪肝分成两组,每个点是一个研究对象。可以在图上用鼠标拖拽选出左上方这些奇怪的人(指标A高且脂肪肝发生率低的)。
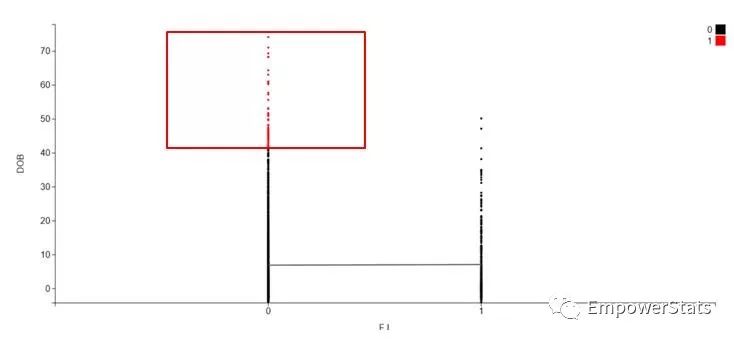
保存成一个组,其他的人是另一个组。自动计算其他所有变量在两组间的差异,可以看到第四个变量是ALT。选取的研究对象ALT很低,两组差异显著p=0.0026。
临床上解释为:对于肝功能很好的患者,就算指标A很高,也不会发生非酒精性脂肪肝。这就提示我们在研究的排除标准里面加上一条:排除肝功能情况很好的患者。至于如何定义ALT的范围,可以结合临床参考值范围确定。
这样做是不是玩弄数据呢?当然不是。如果研究者在做研究设计的时候,根据临床意义想到了这条排除标准,后面数据分析就不会出现这个问题了。然而谁能保证自己的研究设计是完美的呢?后期发现问题,就要及时补救。
怎么写排除标准和设置排除标准的原因呢?
可以参考这篇NEJM
这是2016年发表在新英格兰医学杂志的论文。题目是保留肺功能吸烟者的临床症状。文章排除了肥胖(BMI>40)的人,原因是既往文献报道肥胖可导致肺活量测定异常和呼吸困难,也就是跟本研究的Y关系密切的大混杂被排除了。


登录易侕学院官网
点击“易侕下载”免费下载安装
http://www.empowerstats.com/empowerU/#
以上是关于结果跟预期是反的怎么办?基于R语言的可视化数据分析(附详细操作视频免费查看)的主要内容,如果未能解决你的问题,请参考以下文章
R语言基于自定义函数构建xgboost模型并使用LIME解释器进行模型预测结果解释:基于训练数据以及模型构建LIME解释器解释一个iris数据样本的预测结果LIME解释器进行模型预测结果解释并可视化
R语言层次聚类(hierarchical clustering):特征缩放抽取hclust中的聚类簇(cutree函数从hclust对象中提取每个聚类簇的成员)基于主成分分析的进行聚类结果可视化
R语言构建文本分类模型并使用LIME进行模型解释实战:文本数据预处理构建词袋模型构建xgboost文本分类模型基于文本训练数据以及模型构建LIME解释器解释一个测试语料的预测结果并可视化