参考指南 | 企业该如何做大数据分析挖掘?
Posted UCloud云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了参考指南 | 企业该如何做大数据分析挖掘?相关的知识,希望对你有一定的参考价值。
前言
大数据时代,各种系统、应用、活动所产生的数据浩如烟海,数据也不再仅是企业存储的信息,而是成为可以从中获取巨大商业价值的战略资产。在此背景下,如何存储海量的复杂数据,并从纷繁错综的数据中找出真正有价值的数据,已是大数据时代企业面临的难题。
在8月18日举行的“UCan下午茶”(杭州站)活动现场,来自UCloud、网易、华为的五位技术专家,从数据库高可用容灾方案设计和实现、新一代公有云分布式数据库、基于Impala平台打造交互查询系统等不同维度,分享了在大数据查询、分析、存储开发过程中遇到的“困惑”与解决方案。
UCloud丁顺:数据库高可用容灾方案设计和实现
高可用容灾是搭建数据库服务的一个重要考量特性,搭建高可用数据库服务需要解决诸多问题,以保证最终的容灾效果。UCloud云数据库产品UDB在研发、演进过程中,根据用户的需求不断改进,形成了一套完善的高可用架构体系。
UCloud资深存储研发工程师丁顺从高可用数据库概述、典型的高可用架构分析以及高可用数据库自动化运维等角度,讲述了如何设计和运营一套完善的数据库高可用架构,保证在出现异常时能够及时恢复数据库服务。
业界典型的高可用架构可以划分为四种:第一种,共享存储方案;第二种,操作系统实时数据块复制;第三种,数据库级别的主从复制;第四种,高可用数据库集群。每种数据同步方式可以衍生出不同的架构。
◆ 共享存储
是指若干DB服务使用同一份存储,一个主DB,其它的为备用DB,若主服务崩溃,则系统启动备用DB,成为新的主DB,继续提供服务。其优点是没有数据同步的问题,缺点是对网络性能要求比较高。
◆ 操作系统实时数据块复制
典型场景是DRBD,如下图所示,左边数据库写入数据以后立即同步到右边的存储设备当中,如果左边数据库崩溃,系统直接将右边的数据库存储设备激活,完成数据库的容灾切换。这个方案同样有一些问题,如系统只能有一个数据副本提供服务,无法实现读写分离;另外,系统崩溃后需要的容灾恢复时间较长。
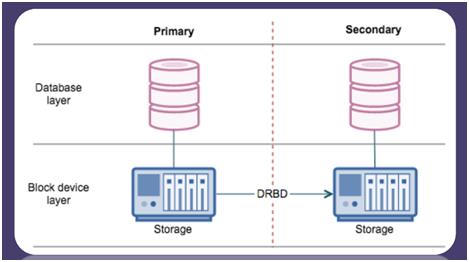
(图:操作系统实时数据块复制原理)
◆ 数据库主从复制
是比较经典的数据同步模式,系统采用一个主库和多个从库,主库同步数据库日志到各个从库,从库各自回放日志。它的好处是一个主库可以连接多个从库,能方便地实现读写分离。同时,因为每个备库都在启动当中,所以备库当中的数据基本上都是热数据,容灾切换也非常快。
◆ 数据库高可用集群
是基于一致性算法来做数据同步,而前述三种是通过复制日志的模式实现高可用。数据库提供一种多节点的一致性同步机制,然后利用该机制构建多节点同步集群,这是业界近年来比较流行的高可用集群方案。
UCloud综合了原生mysql兼容、不同版本、不同应用场景的覆盖等多种因素,最终选择采用基于数据库主从复制的方式实现高可用架构,并在原架构基础上,使用双主架构、半同步复制、采用GTID等措施进行系列优化,保证数据一致性的同时,实现日志的自动寻址。
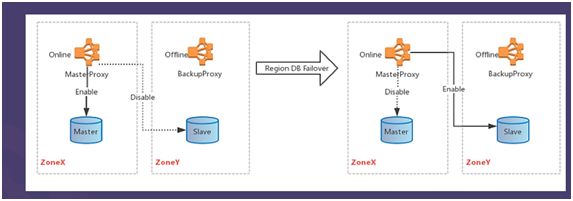
(图:UDB容灾切换示意图)
自动化运维是高可用数据库的难点,UDB在日常例行巡检之外,也会定期做容灾演练,查看在不同场景下数据是否丢失、是否保持一致性等,同时设置记录日志、告警系统等,以便第一时间发现问题,并追溯问题根源,找出最佳解决方案。
UCloud刘坚君:新一代公有云分布式数据库UCloud Exodus
公有云2.0时代,云数据库新产品不断涌现,诸如AWS Aurora、阿里云PolarDB等。UCloud在采用最新软硬件和分布式技术改造传统数据库的工作中,也思考除了分布式数据库所要求的更大、更快之外,是否还有其它更重要的用户价值?UCloud资深数据库研发工程师刘坚君讲解了UCloud对于新一代公有云分布式数据库的思考与设计。
首先从1.0时代存在的问题入手,刘坚君认为1.0时代云数据库带来了三方面价值:弹性、故障救援、知识复用。但它同样面临三大难以解决的问题:容量和性能、租用成本、运营成本。
到2.0时代,解决上述三个问题的思路是计算和读写分离。通过计算和读写分离,将传统数据库的计算层和存储层拆开,各自独立扩展和演进。这样做的好处是:1.提供更大的容量和读写性能;2.按需扩容和付费;3.优化运营成本并降低运营风险。当前业界已推出的2.0云数据库(如Aurora、PolarDB等),均采用计算和存储分离的架构。
UCloud Exodus的产品和技术理念则更进一步:计算和存储分离后,存储层将完全复用云平台的高性能分布式存储(如UCloud UDisk、阿里云盘古等),而Exodus则专注于构建一款数据库内核,去适配主流公有云和私有云厂商发布的高性能分布式存储产品,这种产品架构称之为Shared-ALL-DISK架构。
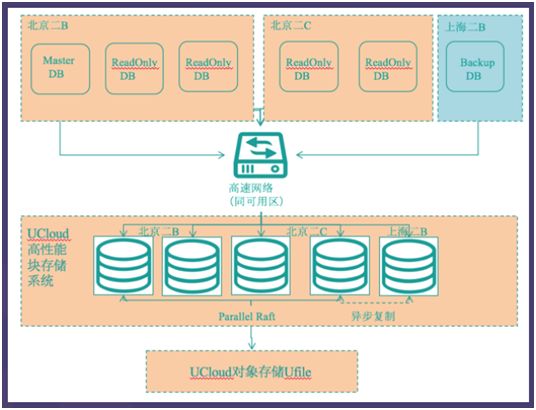
(图:UCloud Exodus架构图)
Shared-ALL-DISK架构的优点明显,在提供云数据库2.0创新功能的同时,赋予用户业务自由迁徙的能力,不被某个云平台绑架,同时能够连接上下游的软硬件厂商,共建Exodus数据库生态。
更为重要的是,Exodus最终将开源。UCloud会把核心系统的每一行源码开放,赋予用户深入了解和优化Exodus的能力,并建设开源社区,吸收全行业的优化成果,共同改进和完善Exodus。
网易蒋鸿翔:基于Impala平台打造交互查询系统
在数据分析时,由于数据基数庞大、关系模型复杂、响应时间要求高等特性,数据之间的交互查询就显得尤为重要。来自网易的大数据技术专家蒋鸿翔从交互式查询特点着手,深入浅出讲解了Impala架构、原理以及网易对Impala的改进思路和使用场景。
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala能够快速实现数据查询。下图是一个Impala架构图。
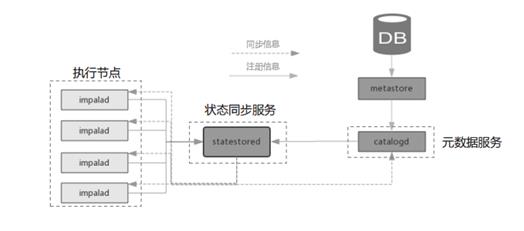
(图:Impala查询流程)
Impala拥有元数据缓存、MPP并行计算、支持LLVM与JIT以及支持HDFS本地读、算子下推等特性。但也有一些缺陷,如服务单点、Web信息无法持久化、资源隔离并不精确、负载均衡需要外部支持等。
网易针对上述不足之处,在原有的Impala查询系统基础上,进行了系列改进优化:
• 基于ZK的Loadbalance,原始Impala负载均衡需要外部支持,为此网易基于ZK做了一个Loadbalance方案;
• 管理服务器,主要为了解决当某一个节点挂掉时的数据丢失问题,管理服务器会将所有的状态信息搜集进来,后续如果做分析都可以通过关联的服务器查询;
• 细粒度权限和代理;
• Json格式;
• 兼容Ranger权限管理;
• 批量元数据刷新;
• 元数据同步;
• 元数据过滤;
• 对接ElasticSearch查询。
据蒋鸿翔介绍,改造后的交互查询系统已成功应用于网易数据科学中心的一站式大数据平台自助查询系统上。同时,数据分析中心的一站式报表系统底层也搭载在Impala上。相信未来基于Impala的查询系统将会应用于更多不同的场景。
UCloud王仆:UCloud分布式KV存储系统
分布式KV存储系统在互联网公司中扮演着重要角色,各类上层业务对于KV存储系统的高可用性、可扩展性和数据一致性都有着很高的要求。UCloud存储部门在迭代升级分布式Redis架构的同时,也一直致力于研发基于硬盘存储的大容量分布式KV系统。来自UCloud的技术专家王仆着重介绍了UCloud在大容量分布式KV系统设计方面的经验,以及应对线上业务高性能、高容量要求的系统架构设计思路。
下图为UCloud分布式KV存储系统架构,底层为多个Storage,每一个Storage有三个节点,这三个节点需要放在不同的物理机上,防止一台机器宕机后系统不可用;标红框的属于Master节点,Master节点通过日志同步的方式,同步到层节点,整个数据的请求从Proxy进入。
(图:UCloud分布式KV存储系统架构)
整个系统是有中心节点的系统,路由管理由Master来管理,Master通过每个机器上的Host管理Storage节点,由Zookeeper确定谁是主谁是从,因此一些管理方面的请求都是直接连接到Master上的,包括创建、删除和控制台方面的功能等。
在测试过程中也发现了一些性能方面的问题:首先,采用的部分Raft协议是单Raft,设计之初并没有实现并行Raft功能,因此数据同步较慢;其次,请求是通过代理的方式实现,代理的延迟会比直接访问的延迟更高,后期会考虑提供一些客户端的SDK,让请求可以跳过代理,减少一次网络交互。
在KV系统的后续优化上,王仆介绍,为了能够将存储系统应用于更多不同的业务场景,未来会考虑更高的通用性,适配多种存储引擎;另外,因为Redis比较流行,系统设计之初主要是支持Redis,但业界还有一些其它协议,这时候需要特殊的转化流程,未来希望做成一个支持各种协议的通用结构化存储系统,适配其它不同协议。
华为时金魁:实时流计算技术及其应用
随着Flink/Spark Streaming的大受欢迎,实时流计算开始进入大众视野。流计算在物联网行业、车联网、智慧城市等行业快速落地,亦创造出越来越多的价值。来自华为的架构师时金魁分享了实时流计算的一些技术方案和落地应用。
在传统的数据处理流程中,总是先收集数据,然后将数据放到DB中。当需要时,通过DB对数据做query,得到答案或进行相关的处理。这个流程看起来虽然合理,但结果却非常紧凑,尤其是对于一些实时搜索应用环境中的某些具体问题,类似于MapReduce方式的离线处理并不能很好地解决问题。这就引出了一种新的数据计算结构——流计算方式。它可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息,并把结果发送到下一计算节点。
目前,业界开源的流计算框架很多,最早有Storm、Heron,后来还有Akka、Beam以及现在的Kafka等。在诸多的开源框架中,时金魁认为,Flink是最恰当的流计算框架,Spark Streaming则是最有潜力的流计算框架,但这两个框架在落地应用中都有各自的优缺点。
华为根据Flink与Spark框架各自的特点,摒弃其劣势,设计开发出一款全新的实时流计算服务Cloud Stream Service(简称CS)。CS采用Apache Flink的Dataflow模型,实现完全的实时计算,同时采用在线SQL编辑平台编写Stream SQL,定义数据流入、数据处理、数据流出,用户无需关心计算集群, 无需学习编程技能,降低流数据分析门槛。
(图:实时流计算CS概览)
据介绍,CS聚焦于互联网和物联网场景,适用于实时性要求高、吞吐量大的业务场景。主要应用在互联网行业中小企业、物联网、车联网、金融反欺诈等多种行业应用场景,如互联网汽车、日志在线分析、在线机器学习、在线图计算、在线推荐算法应用等。
总结
虽然开源软件因为其强大的成本优势而拥有强大的力量,但是数据库、云计算厂商仍会尝试推出性能、稳定性、维护服务等指标上更加强大的产品与之进行差异化竞争,并参与开源社区,借力开源软件来丰富自己的产品线、提升自身竞争力,通过更多的高附加值服务来满足部分消费者的需求。
总体来看,未来的大数据分析、存储技术将会变得越来越成熟、便宜和易用。相应的,用户将会更容易、方便地从自己的大数据中挖掘出有价值的商业信息。
—End—
现场演讲PDF下载链接
《数据库高可用容灾方案设计和实现》-丁顺:
https://static.ucloud.cn/946c0d47d7464c039bca604e533ab52c.pdf
《新一代公有云分布式数据库UCloud Exodus》-刘坚君:
https://static.ucloud.cn/c1d0e277c843458884fdb6c6f8d71488.pdf
《基于Impala打造交互查询系统》-蒋鸿翔:
https://static.ucloud.cn/b58b2bb63c6c4249b4363b9ead89774c.pdf
《UCloud分布式KV存储系统》-王仆:
https://static.ucloud.cn/960f349dfd5747328266e798c5e35456.pdf
《实时流计算技术及其应用》-时金魁:
https://static.ucloud.cn/7fd3332f5a894c468d94d6531f2ea918.pdf
以上是关于参考指南 | 企业该如何做大数据分析挖掘?的主要内容,如果未能解决你的问题,请参考以下文章