如何让Hadoop结合R语言做大数据分析?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何让Hadoop结合R语言做大数据分析?相关的知识,希望对你有一定的参考价值。
R语言和Hadoop让我们体会到了,两种技术在各自领域的强大。很多开发人员在计算机的角度,都会提出下面2个问题。问题1: Hadoop的家族如此之强大,为什么还要结合R语言?问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?下面我尝试着做一个解答:问题1: Hadoop的家族如此之强大,为什么还要结合R语言?
a. Hadoop家族的强大之处,在于对大数据的处理,让原来的不可能(TB,PB数据量计算),成为了可能。
b. R语言的强大之处,在于统计分析,在没有Hadoop之前,我们对于大数据的处理,要取样本,假设检验,做回归,长久以来R语言都是统计学家专属的工具。
c. 从a和b两点,我们可以看出,hadoop重点是全量数据分析,而R语言重点是样本数据分析。 两种技术放在一起,刚好是最长补短!
d. 模拟场景:对1PB的新闻网站访问日志做分析,预测未来流量变化
d1:用R语言,通过分析少量数据,对业务目标建回归建模,并定义指标d2:用Hadoop从海量日志数据中,提取指标数据d3:用R语言模型,对指标数据进行测试和调优d4:用Hadoop分步式算法,重写R语言的模型,部署上线这个场景中,R和Hadoop分别都起着非常重要的作用。以计算机开发人员的思路,所有有事情都用Hadoop去做,没有数据建模和证明,”预测的结果”一定是有问题的。以统计人员的思路,所有的事情都用R去做,以抽样方式,得到的“预测的结果”也一定是有问题的。所以让二者结合,是产界业的必然的导向,也是产界业和学术界的交集,同时也为交叉学科的人才提供了无限广阔的想象空间。问题2: Mahout同样可以做数据挖掘和机器学习,和R语言的区别是什么?
a. Mahout是基于Hadoop的数据挖掘和机器学习的算法框架,Mahout的重点同样是解决大数据的计算的问题。
b. Mahout目前已支持的算法包括,协同过滤,推荐算法,聚类算法,分类算法,LDA, 朴素bayes,随机森林。上面的算法中,大部分都是距离的算法,可以通过矩阵分解后,充分利用MapReduce的并行计算框架,高效地完成计算任务。
c. Mahout的空白点,还有很多的数据挖掘算法,很难实现MapReduce并行化。Mahout的现有模型,都是通用模型,直接用到的项目中,计算结果只会比随机结果好一点点。Mahout二次开发,要求有深厚的JAVA和Hadoop的技术基础,最好兼有 “线性代数”,“概率统计”,“算法导论” 等的基础知识。所以想玩转Mahout真的不是一件容易的事情。
d. R语言同样提供了Mahout支持的约大多数算法(除专有算法),并且还支持大量的Mahout不支持的算法,算法的增长速度比mahout快N倍。并且开发简单,参数配置灵活,对小型数据集运算速度非常快。
虽然,Mahout同样可以做数据挖掘和机器学习,但是和R语言的擅长领域并不重合。集百家之长,在适合的领域选择合适的技术,才能真正地“保质保量”做软件。
如何让Hadoop结合R语言?
从上一节我们看到,Hadoop和R语言是可以互补的,但所介绍的场景都是Hadoop和R语言的分别处理各自的数据。一旦市场有需求,自然会有商家填补这个空白。
1). RHadoop
RHadoop是一款Hadoop和R语言的结合的产品,由RevolutionAnalytics公司开发,并将代码开源到github社区上面。RHadoop包含三个R包 (rmr,rhdfs,rhbase),分别是对应Hadoop系统架构中的,MapReduce, HDFS, HBase 三个部分。
2). RHiveRHive是一款通过R语言直接访问Hive的工具包,是由NexR一个韩国公司研发的。
3). 重写Mahout用R语言重写Mahout的实现也是一种结合的思路,我也做过相关的尝试。
4).Hadoop调用R
上面说的都是R如何调用Hadoop,当然我们也可以反相操作,打通JAVA和R的连接通道,让Hadoop调用R的函数。但是,这部分还没有商家做出成形的产品。
5. R和Hadoop在实际中的案例
R和Hadoop的结合,技术门槛还是有点高的。对于一个人来说,不仅要掌握Linux, Java, Hadoop, R的技术,还要具备 软件开发,算法,概率统计,线性代数,数据可视化,行业背景 的一些基本素质。在公司部署这套环境,同样需要多个部门,多种人才的的配合。Hadoop运维,Hadoop算法研发,R语言建模,R语言MapReduce化,软件开发,测试等等。所以,这样的案例并不太多。 参考技术A
R语言和MATLAB一样,用于数据分析处理的,在某些方面比较MATLAB更加强力,在计算矩阵方面PYTHON完全没可比性,R语言还可以和Hadoop结合运行在集群上,做大规模数据统计必备。
优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop 还是可伸缩的,能够处理 PB 级数据。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
发展前景很好,毕竟数据分析这一行在国内才刚刚起步,很多企业都需要这方面的人才,是很有潜力的,这一行偏商科,技术辅助。真正的大牛不是数据分析工具技术,而是用数据帮助企业在产品、价格、促销、顾客、流量、财务、广告、流程、工艺等方面进行价值提升的人。像我本人就是自学的数据分析师然后毕业后去了决明工作,现在基本实现了财务自由,但想成为大数据分析师的话,需要日积月累坚持沉淀下去,相信你总有一天也能达到这个层次。
[AWS][大数据][Hadoop] 使用EMR做大数据分析
实验包括:
1. 使用EMR创建Hadoop集群
2. 定义schema,创建示例表。
3. 通过HiveQL分析数据,并将分析结果保存到S3上
4. 下载已经分析结果数据。
Task1:创建一个S3 桶
创建一个存储桶比如hadoop202006…

Task2:创建EMR集群
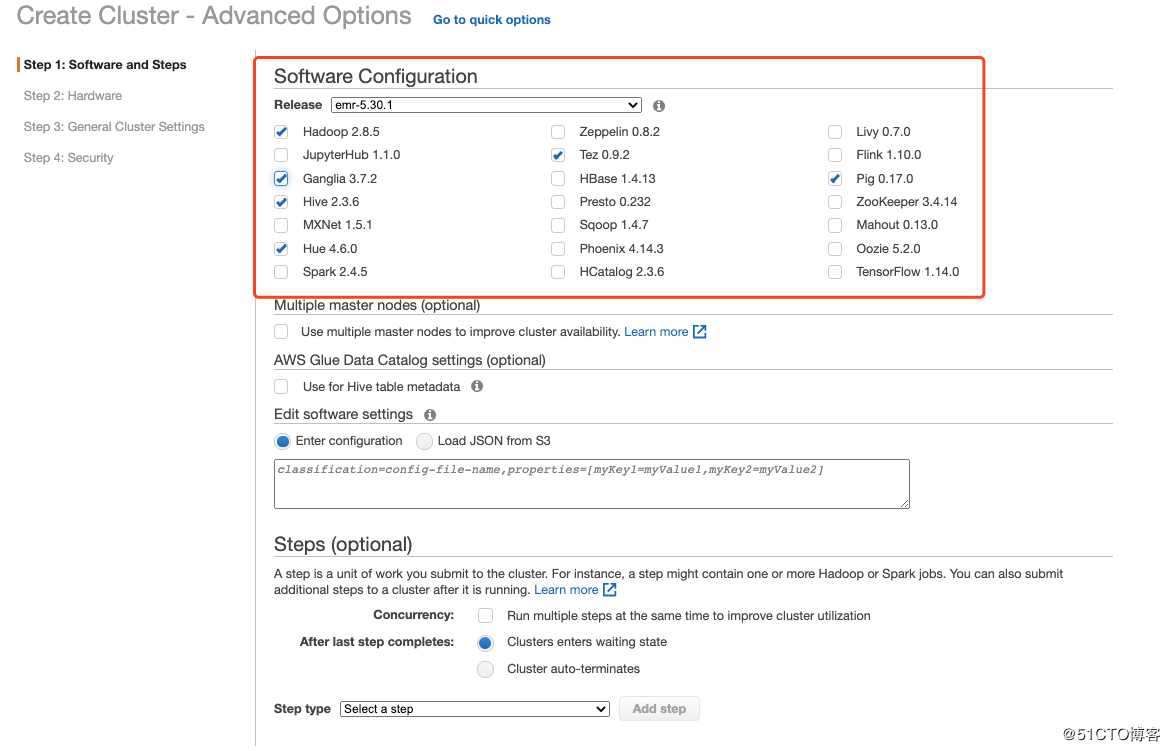
这里我解释一下Hadoop集群中的一些组件,了解大数据的同学直接忽略就好。
- Apache Hadoop:在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
- Ganglia:分布式监控系统
- Apache Tez:支持 DAG 作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。比如Hive或Pig可以将Tez作为执行引擎。
- Hive:可以通过类似SQL语句实现快速MapReduce统计
- Hue:通过使用Hue我们可以通过浏览器方式操纵Hadoop集群。例如put、get、执行MapReduce Job等等。
- Pig:它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
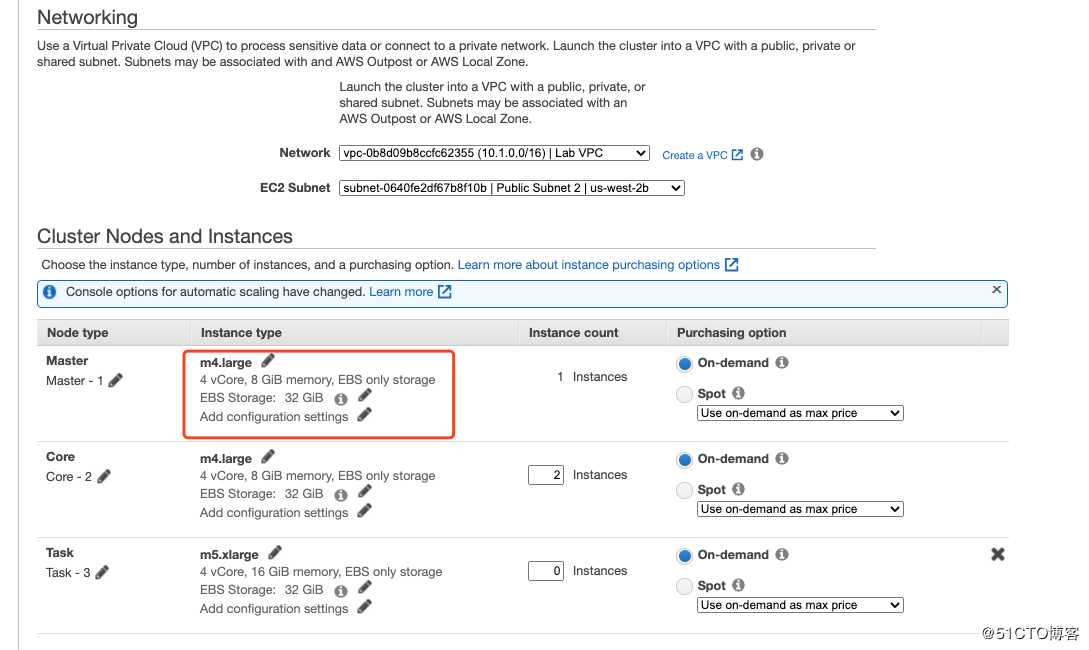
解释一下,Master、Core、Task。
- Master Node:主节点集群管理,通常运行分布式应用程序的Master组件,例如,YARN ResourceManager,HDFS NameNode。
- Core Node:会运行 HDFS的 DataNode, 运行YARN守护程序,MR任务等。
- Task Node:任务节点是可选的,做为可扩展的算力。不运行HDFS的DataNode守护程序,不做HDFS的存储。
MasterNode至少有一个
CoreNode 至少一个
TaskNode 可以有一个(可选)
当Cluster状态为Waiting时,执行Task3.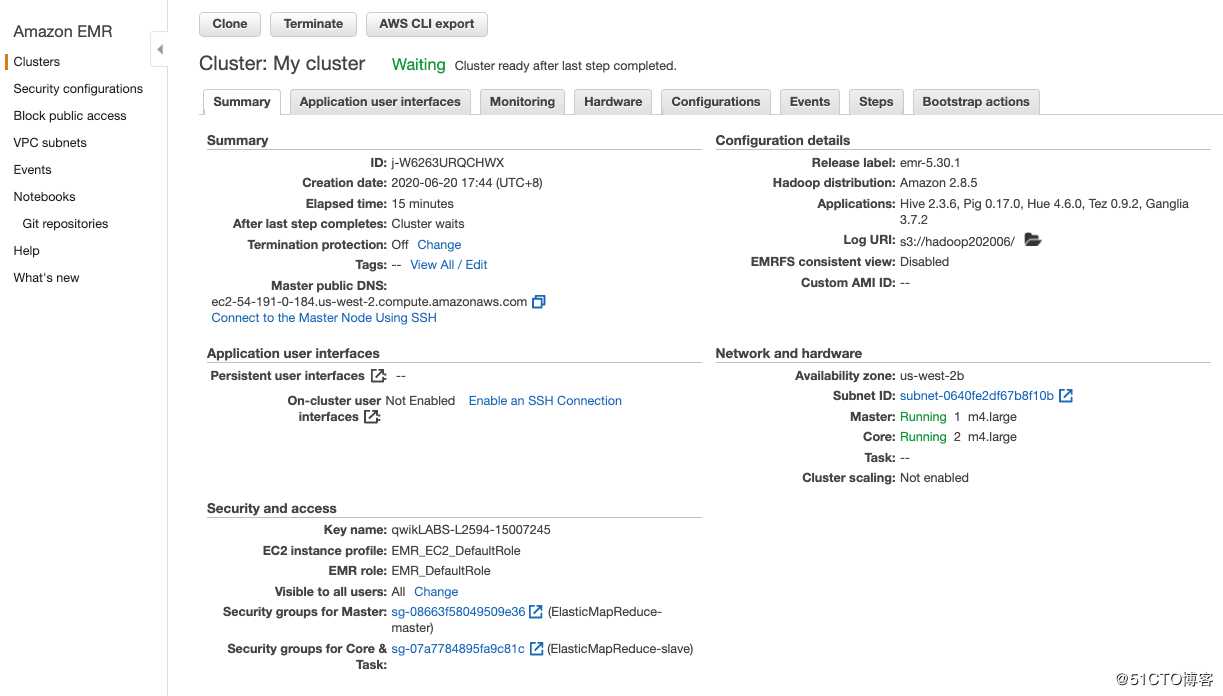
Task3:使用Hive脚本处理数据
在处理数据之前肯定要明确两件事情:
- 处理什么数据
-
如何处理数据
- 处理什么数据:
这里以CDN的log日志为例,其中一条数据的格式为:2017-07-05 20:05:47 SEA4 4261 10.0.0.15 GET eabcd12345678.cloudfront.net /test-image-2.jpeg 200 - Mozilla/5.0%20(MacOS;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20Chrome/3.0.9
解释如下:
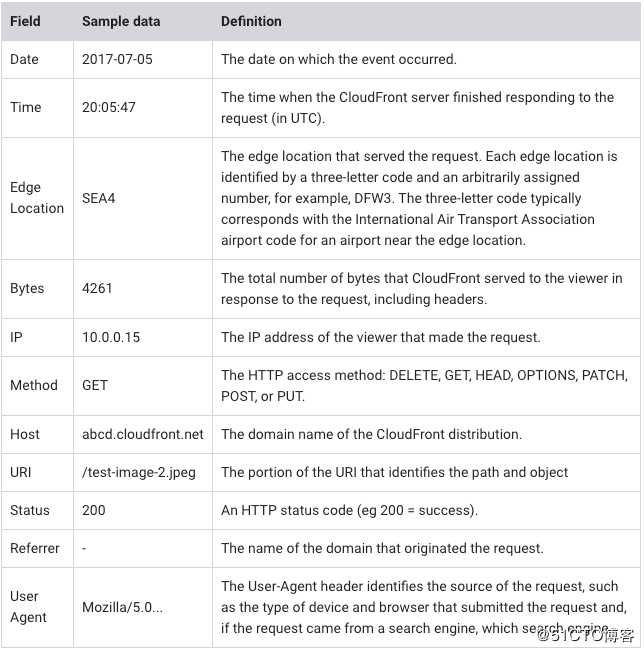
- 如何处理数据
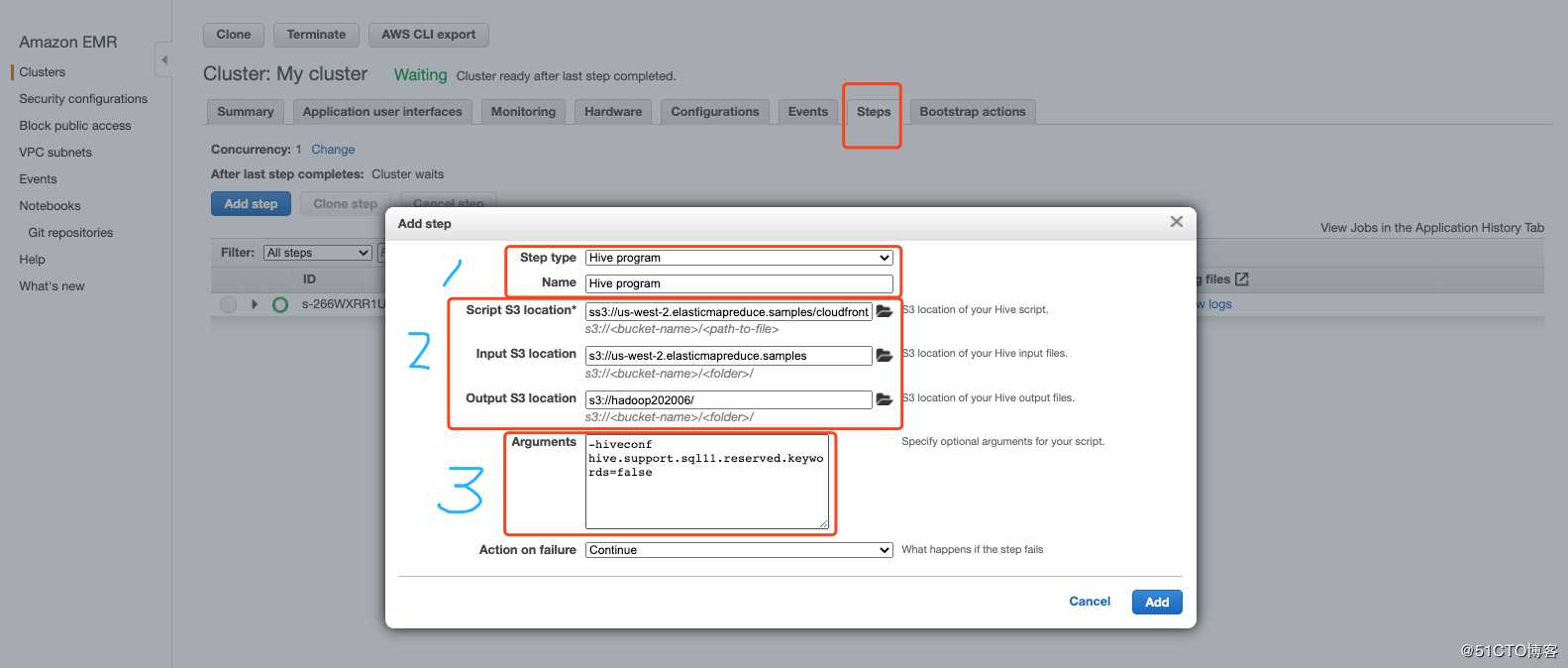
在EMR集群中,添加STEP,
- Step类型选择:Hive progran。
多说一句:目前有4中Task类型,自定义JAR,Streaming program来处理流数据,Hive/Pig执行类SQL。
- Name:Process logs
- Script S3 location:s3://us-west-2.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q
(一会儿分析一个这个脚本都执行了什么) - Input S3 location: s3://us-west-2.elasticmapreduce.samples(这个就是CDN的log日志)
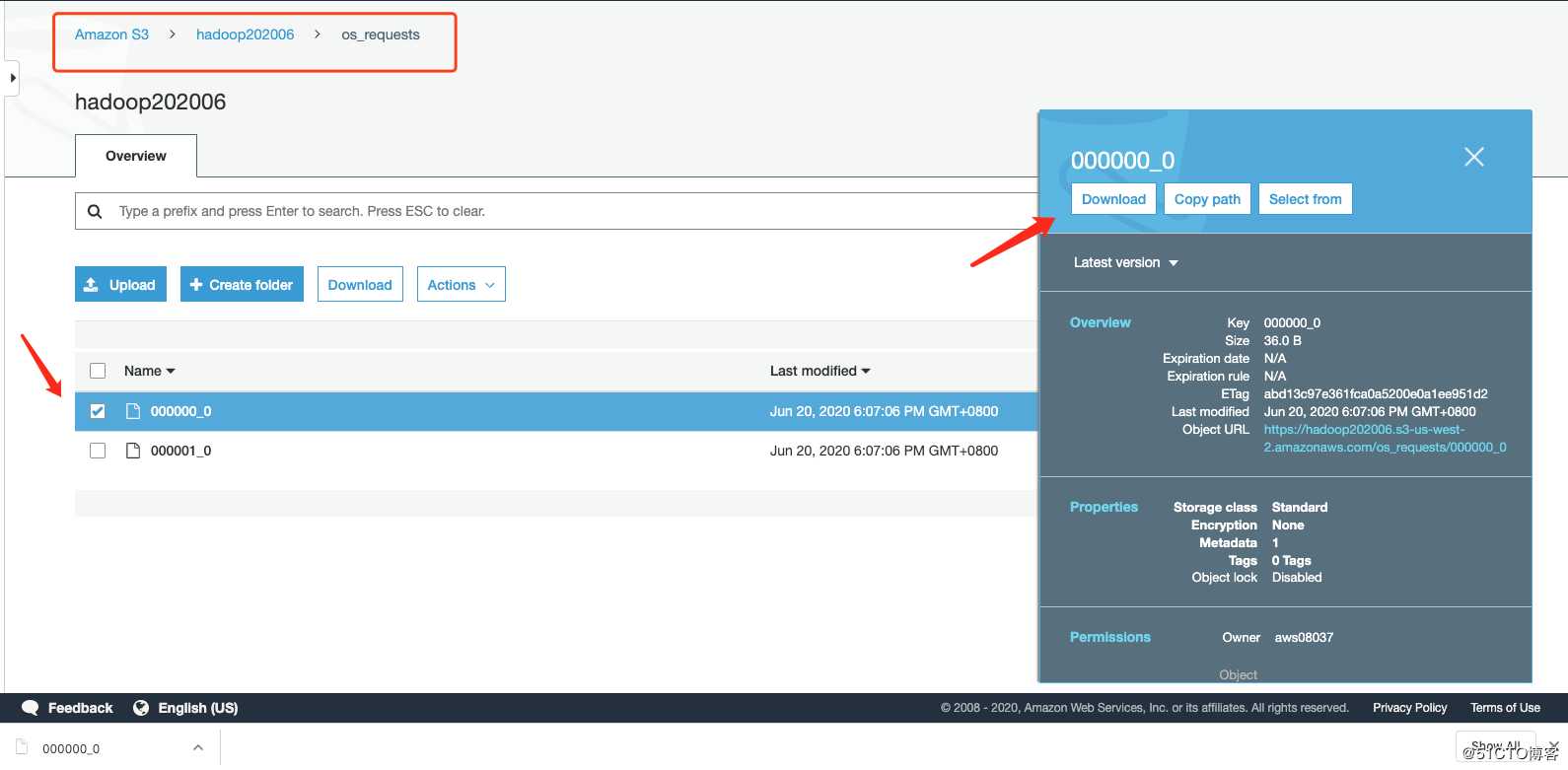
- Output S3 Location:选择我创建的hadoop202006(这个就是我们处理后的文件存放的位置)
- Arguments:-hiveconf hive.support.sql11.reserved.keywords=false
如下图:
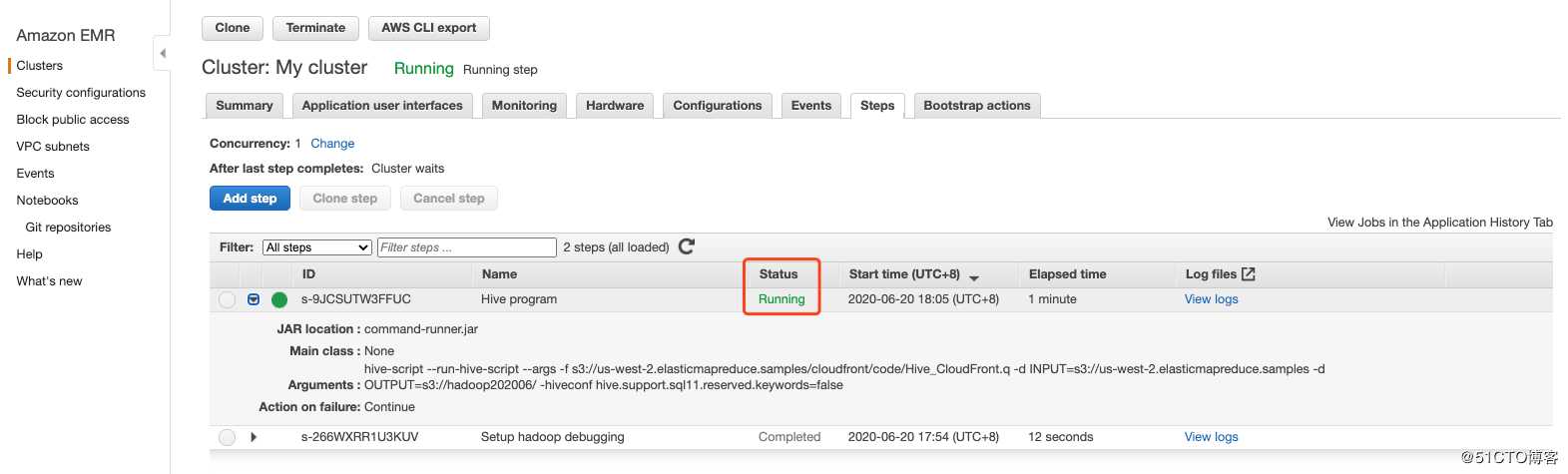
脚本都干了啥?(你可以SSH到Cluster上直接执行HiveQL)
- 创建一个叫cloudfront_logs的Hive table
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (DateObject Date,Time STRING,Location STRING,Bytes INT,RequestIP STRING,Method STRING,Host STRING,Uri STRING,Status INT,Referrer STRING,OS String,Browser String,BrowserVersion String)
- 对log的格式进行序列化/反序列化 RegEx SerDe 并写入CDN的log数据到Hive表中
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe‘WITH SERDEPROPERTIES ( "input.regex" = "^(?!#)([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+([^ ]+)s+[^(]+(.\%20([^/]+)[/](https://s3-us-west-2.amazonaws.com/us-west-2-aws-training/awsu-spl/spl-166/1.0.7.prod/instructions/en_us/.)$") LOCATION ‘${INPUT}/cloudfront/data/‘;
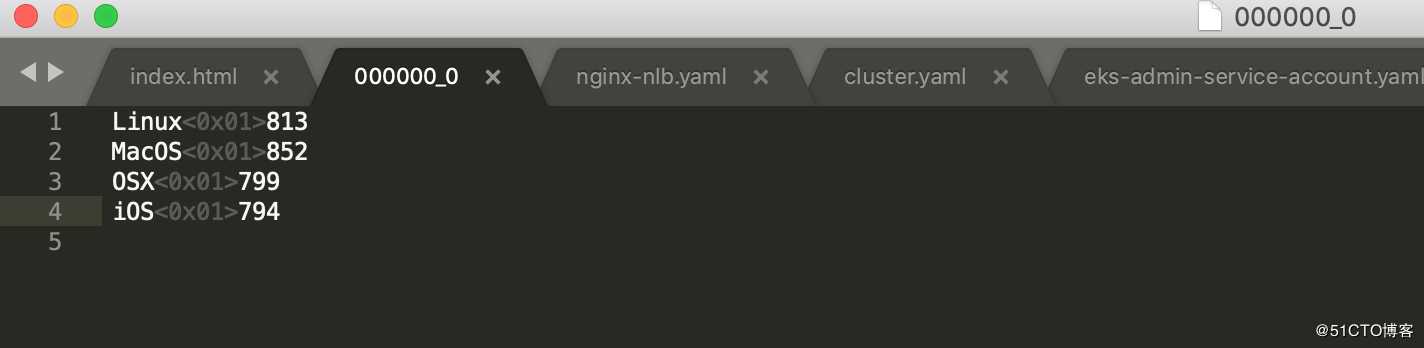
- 查询日中Client端使用的OS数量by日期并把查询结果写入S3
INSERT OVERWRITE DIRECTORY ‘${OUTPUT}/os_requests/‘SELECT os, COUNT(*) countFROM cloudfront_logsWHERE dateobjectBETWEEN ‘2014-07-05‘ AND ‘2014-08-05‘GROUP BY os;
Task4:收获果实:
有关云数据库视频教学参考:https://edu.51cto.com/course/23012.html
以上是关于如何让Hadoop结合R语言做大数据分析?的主要内容,如果未能解决你的问题,请参考以下文章