世界人工智能发展究竟到了什么水平
Posted 腾胜全球高科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了世界人工智能发展究竟到了什么水平相关的知识,希望对你有一定的参考价值。

来源:第一财经

关于人工智能在当今科技界的发展水平,学术界、产业界和媒体界可能会有不同的看法。我经常听到的一个说法是:现在基于大数据与深度学习的人工智能是一种完全新颖的技术形态,它的出现能够全面地改变未来人类的社会形态,因为它能够自主进行“学习”,由此大量取代人类劳力。
我认为这里有两个误解:第一,深度学习并不是新技术;第二,深度学习技术所涉及的“学习”与人类的学习并不是一回事,因为它不能真正“深度”地理解它所面对的信息。
从技术史角度看,深度学习技术的前身,其实就是在20世纪80年代就已经热闹过一阵子的“人工神经元网络”技术(也叫“连接主义”技术)。
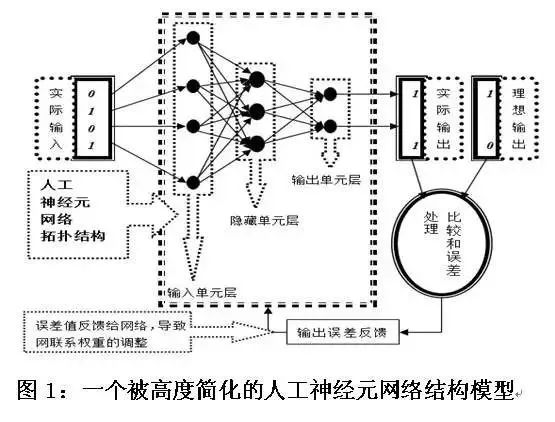
该技术的实质,是用数学建模的办法建造出一个简易的人工神经元网络结构,而一个典型的此类结构一般包括三层:输入单元层、中间单元层与输出单元层。输入单元层从外界获得信息之后,根据每个单元内置的汇聚算法与激发函数,“决定”是否要向中间单元层发送进一步的数据信息,其过程正如人类神经元在接收别的神经元送来的电脉冲之后,能根据自身细胞核内电势位的变化来“决定”是否要向另外的神经元递送电脉冲。
需要注意的是,无论整个系统所执行的整体任务是关于图像识别还是自然语言处理,仅仅从系统中单个计算单元自身的运作状态出发,观察者是无从知道相关整体任务的性质的。毋宁说,整个系统其实是以“化整为零”的方式,将宏观层面上的识别任务分解为了系统组成构件之间的微观信息传递活动,并通过这些微观信息传递活动所体现出来的大趋势,来模拟人类心智在符号层面上所进行的信息处理进程。
工程师调整系统的微观信息传递活动之趋势的基本方法如下:先是让系统对输入信息进行随机处理,然后将处理结果与理想处理结果进行比对。若二者吻合度不佳,则系统触发自带的“反向传播算法”来调整系统内各个计算单元之间的联系权重,使得系统给出的输出与前一次输出不同。两个单元之间的联系权重越大,二者之间就越可能发生“共激发”现象,反之亦然。然后,系统再次比对实际输出与理想输出,如果二者吻合度依然不佳,则系统再次启动反向传播算法,直至实际输出与理想输出彼此吻合为止。
完成此番训练过程的系统,除了能够对训练样本进行准确的语义归类之外,一般也能对那些与训练样本比较接近的输入信息进行相对准确的语义归类。譬如,如果一个系统已被训练得能够识别既有相片库里的哪些相片是张三的脸,那么,即使是一张从未进入相片库的新的张三照片,也能够被系统迅速识别为张三的脸。
如果读者对于上述技术描述还似懂非懂,不妨通过下面这个比方来进一步理解人工神经元网络技术的运作机理。假设一个不懂汉语的外国人跑到少林寺学武术,师生之间的教学活动该如何开展?有两种情况:第一种情况是,二者之间能够进行语言交流(外国人懂汉语或者少林寺师傅懂外语),这样一来,师傅就能够直接通过“给出规则”的方式教授他的外国徒弟。这种教育方法,或可勉强类比基于规则的人工智能路数。
另一种情况是,师傅与徒弟语言完全不通,在这种情况下,学生又该如何学武呢?唯有靠如下办法:徒弟先观察师傅的动作,然后跟着学,师傅则通过简单的肢体交流来告诉徒弟,这个动作学得对不对(譬如,如果对,师傅就微笑;如果不对,师傅则棒喝徒弟)。进而,如果师傅肯定了徒弟的某个动作,徒弟就会记住这个动作,继续往下学;如果不对,徒弟就只好去猜测自己哪里错了,并根据这种猜测给出一个新动作,并继续等待师傅的反馈,直到师傅最终满意为止。很显然,这样的武术学习效率是非常低的,因为徒弟在胡猜自己的动作哪里出错时会浪费大量的时间。但“胡猜”二字恰恰切中了人工神经元网络运作的实质。概而言之,这样的人工智能系统其实并不知道自己得到的输入信息到底意味着什么——换言之,此系统的设计者并不能与系统进行符号层面上的交流,正如在前面的例子中师傅是无法与徒弟进行言语交流一样。而这种低效学习的“低效性”之所以在计算机那里能够得到容忍,则缘于计算机相比于自然人而言的一个巨大优势:计算机可以在很短的物理时间内进行海量次数的“胡猜”,并由此遴选出一个比较正确的解。一旦看清楚了里面的机理,我们就不难发现:人工神经元网络的工作原理其实是非常笨拙的。
那么,为何“神经元网络技术”现在又有了“深度学习”这个后继者呢?这个新名目又是啥意思呢?
不得不承认,“深度学习”是一个带有迷惑性的名目,因为它会诱使很多外行认为人工智能系统已经可以像人类那样“深度地”理解自己的学习内容了。但真实情况是:按照人类的“理解”标准,这样的系统对原始信息最肤浅的理解也无法达到。
为了避免此类误解,笔者比较赞成将“深度学习”称为“深层学习”。因为该词的英文原文“deeplearning”技术的真正含义,就是将传统的人工神经元网络进行技术升级,即大大增加其隐藏单元层的数量。这样做的好处,是能够增大整个系统的信息处理机制的细腻度,使得更多的对象特征能够在更多的中间层中得到安顿。
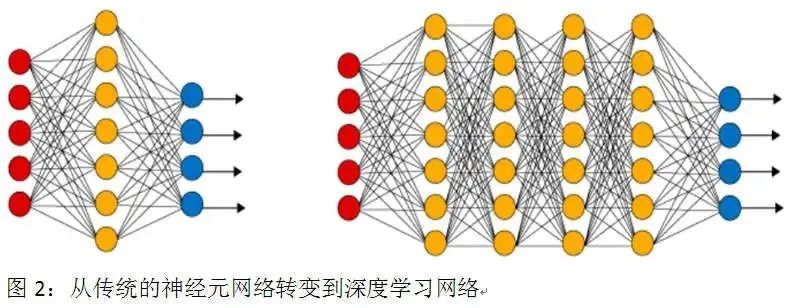
比如,在人脸识别的深度学习系统中,更多的中间层次能够更为细腻地处理初级像素、色块边缘、线条组合、五官轮廓等处在不同抽象层面上的特征。这样的细腻化处理方式当然能够大大提高整个系统的识别能力。
但需要看到,由此类“深度”化要求所带来的整个系统的数学复杂性与数据的多样性,自然会对计算机硬件以及训练用的数据量提出很高的要求。这也就解释了为何深度学习技术在21世纪后才逐渐流行,正是最近十几年以来计算机领域内突飞猛进的硬件发展,以及互联网普及所带来的巨大数据量,才为深度学习技术的落地开花提供了基本保障。
但有两个瓶颈阻碍了神经元网络-深度学习技术进一步“智能化”:
第一,一旦系统经过训练而变得收敛了,那么系统的学习能力就下降了,也就是说,系统无法根据新的输入调整权重。这可不是我们的终极理想。我们的理想是:假定由于训练样本库自身的局限性,网络过早地收敛了,那么面对新样本时,它依然能够自主地修订原来形成的输入-输出映射关系,并使得这种修订能够兼顾旧有的历史和新出现的数据。但现有技术无法支持这个看似宏大的技术设想。设计者目前所能够做的,就是把系统的历史知识归零,把新的样本纳入样本库,然后从头开始训练。在这里我们无疑又一次看到了让人不寒而栗的“西西弗斯循环”。
第二,正如前面的例子所展现给我们的,在神经元网络-深度学习模式识别的过程中,设计者的很多心力都花费在对于原始样本的特征提取上。很显然,同样的原始样本会在不同的设计者那里具有不同的特征提取模式,而这又会导致不同的神经元网络-深度学习建模方向。对人类编程员来说,这正是体现自己创造性的好机会,但对于系统本身来说,这等于剥夺了它自身进行创造性活动的机会。试想:一个被如此设计出来的神经元网络-深度学习结构,能够自己观察原始样本,找到合适的特征提取模式,并设计出自己的拓扑学结构吗?看来很难,因为这似乎要求该结构背后有一个元结构,能够对该结构本身给出反思性的表征。关于这个元结构应当如何被程序化,我们目前依然是一团雾水——因为实现这个元结构功能的,正是我们人类自己。让人失望的是,尽管深度学习技术带有这些基本缺陷,但目前的主流人工智能界已经被“洗脑”,认为深度学习技术就已经等于人工智能的全部。一种基于小数据,更加灵活、更为通用的人工智能技术,显然还需要人们投入更多的心力。从纯学术角度看,我们离这个目标还很远。
文章内容纯属作者个人观点,不代表平台观点。感谢作者辛苦付出与创作,版权归属原作者,如有版权问题请联系删除bella_z@tsgroupedu.com。
完


青岛腾胜全球文化教育咨询有限公司

公司的座右铭是:汇智合力,决胜全球!
(Winning your Globe with a Proven Pool of Skills)
W由两个V并列而成;V是victory首字母。W 也代表我们,代表文教, 最终代表"Win", 即“成功”。
终意是:小胜不断,大胜连连。
青岛腾胜全球文化教育咨询有限公司于2017年正式成立、经筹备于2018 年3月正式开业。办公地点位于山东省青岛市黄岛开发区著名的国际“光谷科技园核心区”的51号楼3层。坐落在青岛市黄岛开发区的光谷科技园类似于京的中关村,和美国加州的硅谷等。公司人力资源科学配置,公司的优质服务产品由全球顶级专家团队和具有丰富业界经验的专业化执行团队精密合作而成。
欢迎大家来电垂询或来公司参观询问本公司的国际教育、中外文化交流互鉴,多元文化教育,跨文化管理,文化产业化与国际化,以及一带一路等相关的培训,策划和整合营销传播及创意服务项目,以及海外留学申请、境外留学监管服务、青少年留学预备班、国内高校国际交流项目与欧美游学、英语语言培训等卓越的国际教育版块。公司将会根据客户的具体情况作出研究诊断,针对客户的明确需求提供精准程度高和专业化程度高的服务。
我们提供的专业服务产品是由全球顶级专家学者团队精心研发设计而成。该公司以青岛为中心,打造了由美国高科技区硅谷、新港滩市、尔湾市和中国北京市、西安市等地区的跨国服务网络平台,未来将继续开拓中美以外的更广阔的全球市场。
欲知详情,请电:18511084948(中文)13991260626 (英文)
微信:
邮箱:info@tsgroupedu.com
邮编:266555
网站:www.tsgroupedu.com

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
好看,你就点一下
以上是关于世界人工智能发展究竟到了什么水平的主要内容,如果未能解决你的问题,请参考以下文章