我们真的需要深度图神经网络吗?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我们真的需要深度图神经网络吗?相关的知识,希望对你有一定的参考价值。
本文最初发表于 TowardsDataScience 博客,经原作者 Michael Bronstein 授权,InfoQ 中文站翻译并分享。
今年,图深度学习成为机器学习领域 炙手可热 的话题之一。然而,那些习惯于想象卷积神经网络具有数十层甚至数百层的人,如果看到大多数关于图深度学习的工作最多只用了几层的话,他们会不会感到深深的失望呢?“深度图神经网络”一词是否被误用了?我们是否应该套用经典的说法,思考深度是否应该被认为对图的学习 是有害的?
训练深度图神经网络是一个难点。除了在深度神经结构中观察到的标准问题(如反向传播中的梯度消失和由于大量参数导致的过拟合)之外,还有一些图特有的问题。其中之一是过度平滑,即应用多个图卷积层后,节点特征趋向于同一向量,变得几乎无法区分的现象【1】。这种现象最早是在 GCN 模型【2】【3】中观察到的,其作用类似于低通滤波器【4】。
最近,人们致力于解决图神经网络中的深度问题,以期获得更好的性能,或许还能避免在提到只有两层的图神经网络时使用“深度学习”这一术语的尴尬。典型的方法可以分为两大类。首先,使用正则化技术,例如边 dropout(DropEdge)【5】、节点特征之间的成对距离归一化(PairNorm)【6】,或节点均值和方差归一化(NodeNorm)【7】。其次,架构变化,包括各种类型的残差连接(residual connection),如跳跃知识【8】或仿射残差连接【9】。虽然这些技术允许训练具有几十层的深度图神经网络(否则很难,甚至不可能),但它们未能显示出显著的收益。更糟糕的是,使用深度架构常常会导致性能下降。下表摘自【7】,显示了一个典型的实验评估,比较了不同深度的图神经网络在节点分类任务上的表现:

该图显示了深度图神经网络结构在 CoauthorsCS 引文网络上的节点分类任务中的典型结果。随着深度的增加,基线(具有残差连接的 GCN)表现不佳,性能从 88.18% 急剧下降到 39.71%。使用 NodeNorm 技术的架构随着深度的增加表现一直良好。然而,当深度增加时,性能下降(虽然不明显,从 89.53% 下降到 87.40%)。总的来说,通过 64 层的深度架构获得的最佳结果(87.40%),逊于简单基线(88.18%)。另外,还可以观察到 NodeNorm 正则化提高了浅 2 层架构的性能(从 88.18% 提高到 89.53%)。上表摘自【7】(所示为每个类 5 个标签的情况;该论文中研究的其他设置也表现出了类似的行为)。类似的结果在【5】和其他几篇论文中也有显示。
从这张表中可以看出,要将深度架构带来的优势与训练这样一个神经网络所需的“技巧”区分开来很困难。实际上,上例中的 NodeNorm 还改进了只有两层的浅层架构,从而达到了最佳性能。因此,在其他条件不变的情况下,更深层次的图神经网络是否会表现得更好,目前尚不清楚。
这些结果显然与传统的网格结构化数据的深度学习形成了鲜明的对比,在网格结构化数据上,“超深度”(ultra-deep)架构【10】【11】带来了性能上的突破,并在今天得到了广泛的使用。在下文中,我将尝试提供一些指导,以期有助回答本文标题提出的“挑衅性”问题。需要注意的是,我本人目前还没有明确的答案。
图的结构 。由于网格是一种特殊的图,因此,肯定有一些图的例子,在这些图上,深度是有帮助的。除网格外,表示分子、点云【12】或网片【9】等结构的“几何”图似乎也受益于深度架构。为什么这样的图与通常用于评估图神经网络的引用网络(如 Cora、PubMed 或 CoauthsCS)有如此大的不同?其中一个区别是,后者类似于具有较小直径的“小世界”网络,在这种网络中,人们可以在几跳内从任何其他节点到达任何节点。因此,只有几个卷积层的感受野(receptive field)已经覆盖了整个图【13】,因此,添加更多的层对到达远端节点并没有帮助。另一方面,在计算机视觉中,感受野呈多项式增长,需要许多层来产生一个能捕捉图像中对象的上下文的感受野【14】。
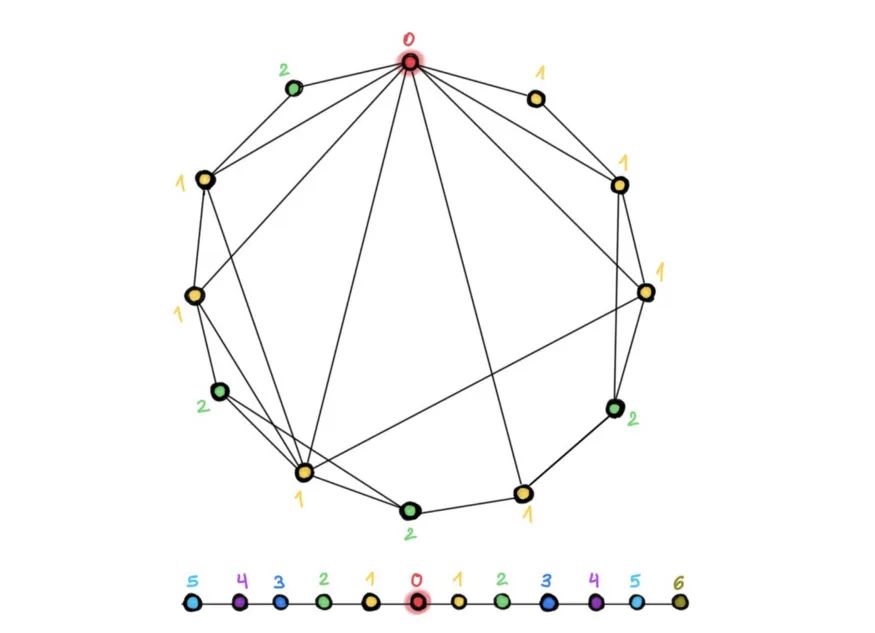
在小世界图(图上)中,只需几跳即可从另一个节点到达任意一个节点。结果,邻居的数量(以及相应的,图卷积滤波器的感受野)呈指数级快速增长。在这个例子中,从红色节点到每个节点仅需两跳即可(不同的颜色表示将到达相应节点的层,从红色节点开始)。另一方面,在网格(图下),感受野的增长是多项式的,因此,需要更多的层才能达到相同的感受野大小。
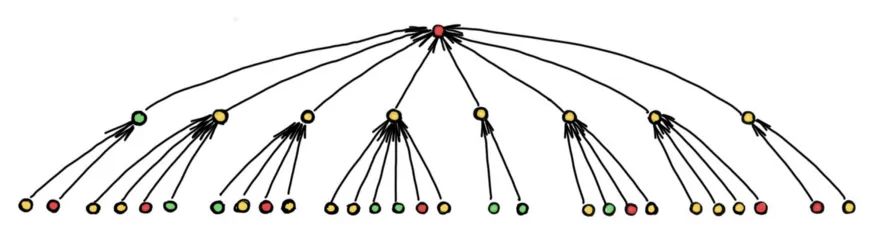
在邻居呈指数级增长的图中(如上图所示),会出现瓶颈现象:来自太多邻居的太多信息必须压缩到单个节点特征向量中。结果,消息无法传播,性能受到影响。
远程问题域短程问题 。一个稍微不同但相关的区别是,问题需要远程信息还是短程信息。例如,在社交网络中,预测通常只依赖于来自某个节点本地邻域的短程信息,而不会通过添加远程信息来改善。因此,这类任务可以由浅层 GNN 来执行。另一方面,分子图通常需要远程信息,因为分子的化学性质可能取决于其相对两边原子的组合【15】。要利用这些远程交互,可能需要深度 GNN。但是,如果图的结构导致感受野呈指数级增长,那么瓶颈现象就会阻止远程信息的有效传播,这就解释了为什么深度模型在性能上没有提高【4】。
理论的局限性 。除了一个更大的感受野外,深度架构在计算机视觉问题上提供的关键优势之一是它们从简单特征组合复杂特征的能力。将 CNN 从人脸图像中学习到的特征进行可视化后,会显示出从简单的几何原语到整个面部结构逐渐变得更加复杂的特征,这表明传说中的“ 祖母神经元”更多是真实的,而不是神话。对于图来说,这样的组合似乎是不可能的,例如,无论神经网络有多深,都无法从边组成三角形【16】。另一方面,研究表明,如果没有一定的最小深度,使用消息传递网络计算某些图的属性(如图矩)是不可能的【17】。总的来说,我们目前还不清楚哪些图属性可以用浅层 GNN 表示,哪些需要深度模型,以及哪些图的属性根本无法计算。
通过卷积神经网络在人脸图像上学习特征的示例。请注意,当进入更深的图层时,特征是如何变得越来越复杂的(从简单的几何原语,到面部部分,再到整个人脸)。图片改编自 Matthew Stewart 的一篇 博文。
深度与丰富度 。与底层网格固定的计算机视觉不同,在对图的深度学习中,图的结构确实很重要,并被考虑在内。设计出更为复杂的消息传递机制来解决标准 GNN 无法发现的复杂的高阶信息是有可能的,比如主题【18】或 子结构计数【19】。人们可以选择具有更丰富的多跳滤波器的浅层网络,而不是使用具有简单一跳滤波器的浅层网络。我们最近发表的关于可扩展的初始类图神经网络(SIGN)的论文,通过将单层线性图卷积架构与多个预计算滤波器结合使用,将这一想法发挥到了极致。我们展示的性能可以与更复杂的模型相媲美,而它们的时间复杂度仅为后者的一小部分【20】。有趣的是,计算机视觉走的是相反的道路:早期具有大(最大 11x11)滤波器的浅层 CNN 架构,如 AlexNet,被具有小(通常为 3x3)滤波器的非常深的架构所取代。
评估 。最后但并非不重要的是,图神经网络的主要评估方法受到了 Oleksandr Shchur 和 Stephan Günnemann【21】小组同事的严厉批评,他们提请人们注意常用基准的缺陷,并表明,如果在公平的环境下进行评估,简单模型的表现可与更复杂的模型相媲美。我们观察到的一些深度架构的现象,例如,性能随深度而下降,可能仅仅是源于对小数据集的过拟合所致。新的 Open Graph Benchmark 解决了其中的一些问题,提供了非常大的图,并进行了严格的训练和测试数据分割。我认为,我们还需要进行一些精心设计的特定实验,以便更好地理解深度在图深度学习是否有用,以及何时有用。
【1】 更确切地说,过度平滑使节点特征向量塌缩成一个子空间,见《 图神经网络对节点分类的表达力呈指数松散》(Graph neural networks exponentially loose expressive power for node classification),K. Oono,T. Suzuki,2009 年,arXiv:1905.10947。论文阐述了使用动态系统形式主义提供渐近分析。
【2】 《 深入研究图卷积网络的半监督学习》(Deeper insights into graph convolutional networks for semi-supervised learning),Q. Li、Z. Han、X.-M. Wu,2019 年,Proc. AAAI。将 GCN 模型与 Laplacian 平滑进行了类比,指出了过度平滑现象。
【3】 《 重温图神经网络:我们所拥有的都是低通滤波器》(Revisiting graph neural networks: All we have is low-pass filters),H. Nt and T. Maehara,2019 年,arXiv:1905.09550。在图上使用谱分析来回答 GCN 何时表现良好。
【4】 《 论图神经网络的瓶颈及其实践意义》(On the bottleneck of graph neural networks and its practical implications),U. Alon、E. Yahav,2020 年,arXiv:2006.05205。论文确定了图神经网络中的过度压缩现象,这与序列递归模型中的过压缩现象类似。
【5】 《 DropEdge:面向深度图卷积网络的节点分类》(DropEdge: Towards deep graph convolutional networks on node classification),Y. Rong 等人,2020 年,In Proc. ICLR。论文阐述了一种类似于 DeopOut 的思想,在训练中使用随机边缘子集。
【6】 《 PairNorm:处理 GNN 中的过度平滑》(PairNorm: Tackling oversmoothing in GNNs),L. Zhao、L. Akoglu,2020 年,Proc. ICLR。论文提出对节点特征之间的成对距离和进行归一化,以防止它们塌缩成单个点。
【7】 《 深度图神经网络的有效训练策略》(Effective training strategies for deep graph neural networks),K. Zhou 等人,2020 年,arXiv:2006.07107。
【8】 《 具有跳跃知识的图表示学习》(Representation learning on graphs with jumping knowledge networks),K. Xu 等人,2018 年,Proc. ICML 2018。
【9】 《 图神经网络中的几何原理连接》(Geometrically principled connections in graph neural networks),S. Gong 等人,2020 年,Proc. CVPR。
【10】 《更深的卷积》(Going deeper with convolutions),C. Szegedy 等人,2015 年,Proc. CVPR。
【11】《基于深度残差学习的图像识别》(Deep residual learning for image recognition),K. He 等人,2016 年,Proc. CVPR。
【12】 《 DeepGCN:GCN 能像 CNN 一样深吗?》(DeepGCNs: Can GCNs go as deep as CNNs?),G. Li 等人,Proc. ICCV。论文阐述了几何点云数据的深度优势。
【13】 Alon 和 Yahav 将节点无法从比层数更远的节点接受信息的情况称为“欠范围”(under-reachinig)。P Barceló 等人在论文《 图神经网络的逻辑表达力》(The logical expressiveness of graph neural networks)首先指出了这一现象,2020 年,Proc. ICLR。Alon 和 Yahav 通过实验研究了分子图的化学性质预测问题(使用层数大于图直径的 GNN),发现性能差的根源并非达不到,而是过度压缩。
【14】 André Araujo 和合著者发表了一篇关于卷积神经网络感受野的 优秀博文。随着 CNN 模型在计算机视觉应用中的发展,从 AlexNet,到 VGG、ResNet 和 Inception,它们的感受野作为层数增加的自然结果而增加。在现代架构中,感受野通常包含整个输入图,即最终输出特征映射中每个特征所使用的上下文包含所有的输入像素。Araujo 等人观察到分类准确率与感受野大小之间存在对数关系,这表明较大的感受野对于高水平的识别任务是必需的,但收益是递减的。
【15】 《 基于波网络的无向图远程信息的深度学习》(Deep learning long-range information in undirected graphs with wave networks),M. K. Matlock 等人,2019 年,Proc. IJCNN。观察了图神经网络在分子图中捕捉远距离交互作用的失败现象。
【16】 这源于消息传递 GNN 等价于 Weisfeiler-Lehman 图通过测试,参见例如《 关于 Weisfeiler-Lehman 不变性:子图计数和相关图性质》(On Weisfeiler-Leman invariance: subgraph counts and related graph properties),V. Arvind 等人,2018 年,arXiv:1811.04801。以及《 图神经网络能计算子结构吗?》(Can graph neural networks count substructures?),Z. Chen 等人,2020 年,arXiv:2002.04025。
【17】 《 理解图神经网络在学习图拓扑中的表示能力》(Understanding the representation power of graph neural networks in learning graph topology),N. Dehmamy、A.-L. Barabási、R. Yu,2019 年,Proc. NeurIPS。论文表明了一定阶数的学习图矩需要一定深度的 GNN。
【18】 《 MotifNet:基于主题(motif)的有向图卷积网络》(MotifNet: a motif-based Graph Convolutional Network for directed graphs),F. Monti、K. Otness、M. M. Bronstein,2018 年,arXiv:1802.01572。
【19】 《 通过子图同构计数提高图神经网络的表达能力》(Improving graph neural network expressivity via subgraph isomorphism counting),G. Bouritsas 等人,2020 年,arXiv:2006.09252。
【20】 《 SIGN:可扩展的初始图神经网络》(SIGN: Scalable inception graph neural networks),E. Rossi 等人,2020 年,arXiv:2004.11198。
【21】 《 图神经网络评估的缺陷》(Pitfalls of graph neural network evaluation),O. Shchur 等人,2018 年。关系表征学习研讨会(Workshop on Relational Representation Learning)。论文阐述了简单的 GNN 模型与复杂的 GNN 模型的性能相当。
作者介绍:
Michael Bronstein,伦敦帝国理工学院教授,Twitter 图机器学习研究负责人,CETI 项目机器学习主管、研究员、教师、企业家和投资者。
原文链接:
https://towardsdatascience.com/do-we-need-deep-graph-neural-networks-be62d3ec5c59
你也「在看」吗? 以上是关于我们真的需要深度图神经网络吗?的主要内容,如果未能解决你的问题,请参考以下文章