扩展图神经网络:暴力堆叠模型深度并不可取
Posted 数学职业家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了扩展图神经网络:暴力堆叠模型深度并不可取相关的知识,希望对你有一定的参考价值。
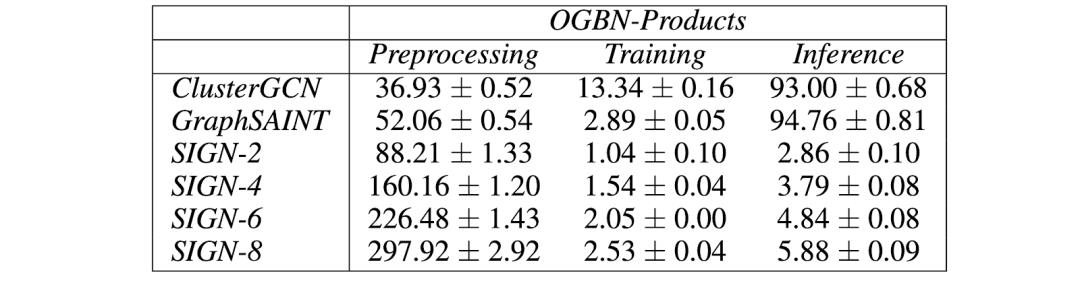
目前,阻碍图神经网络在业界大规模应用的挑战之一是:图神经网络很难被扩展到 Twitter 的用户关注关系图这类大型图上。
节点之间的相互依赖关系使我们很难将损失函数分解为各个独立节点的影响。
在本文中,我们介绍了Twitter 研发的一种简单的图神经网络架构,该架构可以在大型图上有效工作。
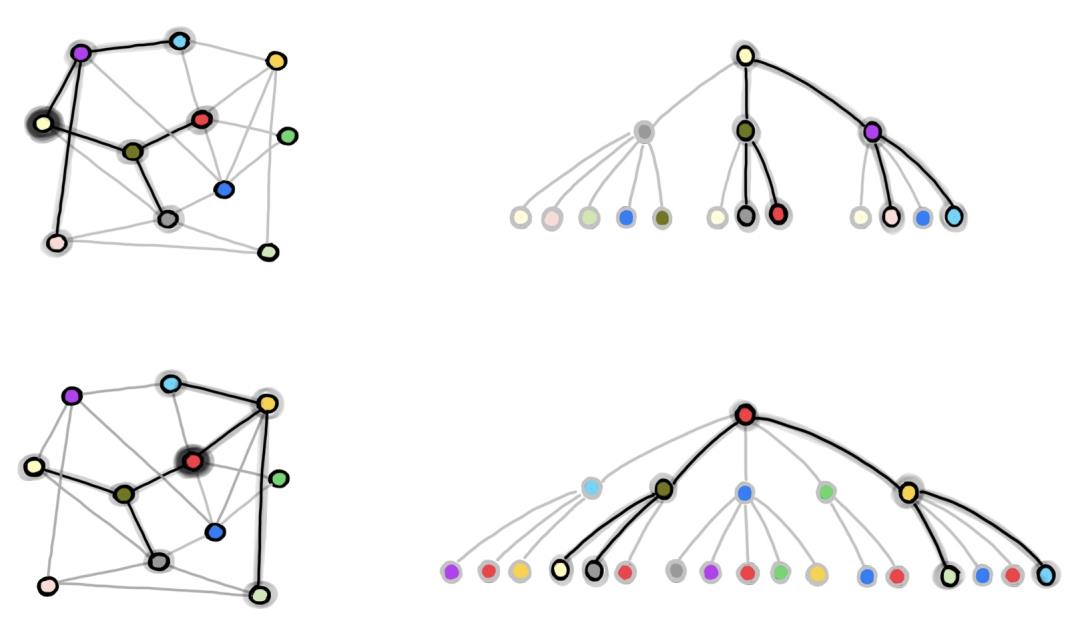
 大多数现有的文献中描述的方法在这样的大规模应用场景下并不适用。
大多数现有的文献中描述的方法在这样的大规模应用场景下并不适用。

3
方法探究
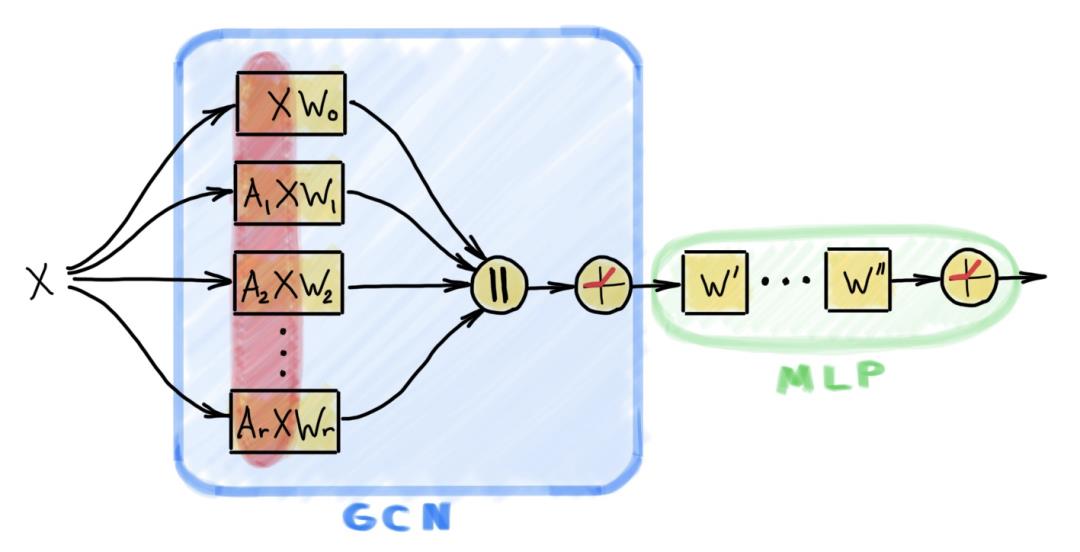
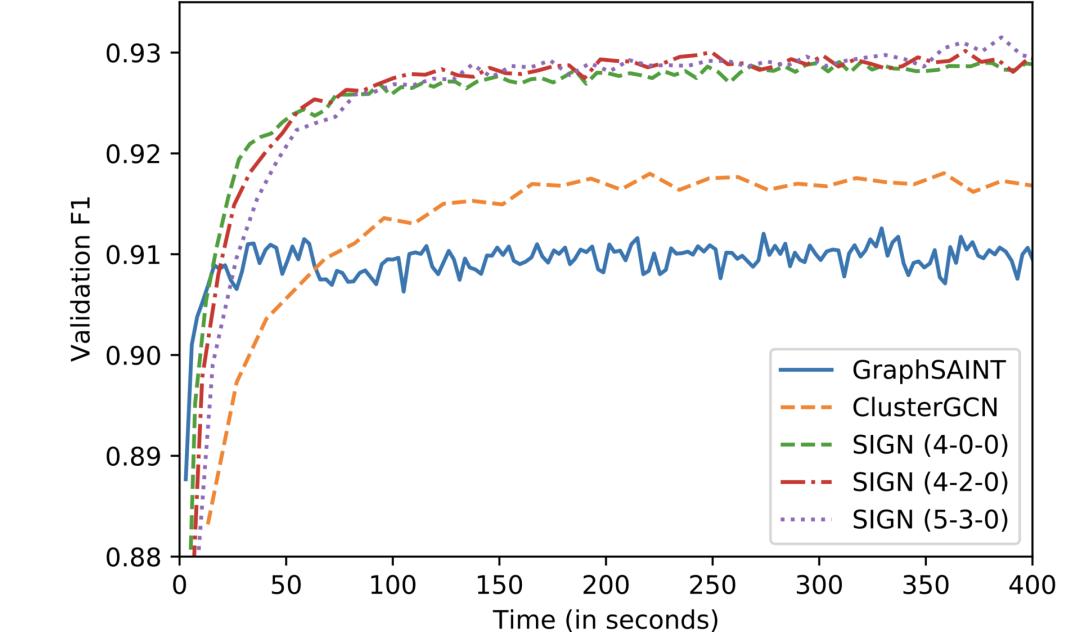
[1] The recently introduced Open Graph Benchmark now offers large-scale graphs with millions of nodes. It will probably take some time for the community to switch to it.
[2] T. Kipf and M. Welling, Semi-supervised classification with graph convolutional networks (2017). Proc. ICLR introduced the popular GCN architecture, which was derived as a simplification of the ChebNet model proposed by M. Defferrard et al. Convolutional neural networks on graphs with fast localized spectral filtering (2016). Proc. NIPS.
[3] As the diffusion operator, Kipf and Welling used the graph adjacency matrix with self-loops (i.e., the node itself contributes to its feature update), but other choices are possible as well. The diffusion operation can be made feature-dependent of the form A(X)X (i.e., it is still a linear combination of the node features, but the weights depend on the features themselves) like in MoNet [4] or GAT [5] models, or completely nonlinear, 以上是关于扩展图神经网络:暴力堆叠模型深度并不可取的主要内容,如果未能解决你的问题,请参考以下文章