卷积神经网络与Transformer结合,东南大学提出视频帧合成新架构 ConvTransformer
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络与Transformer结合,东南大学提出视频帧合成新架构 ConvTransformer相关的知识,希望对你有一定的参考价值。
研究者表示,这是卷积神经网络与 Transformer 首度结合用于视频帧合成。
深度卷积神经网络(CNN)是功能非常强大的模型,在一些困难的计算机视觉任务上性能也很卓越。尽管卷积神经网络只要有大量已标记的训练样本就能够执行,但是由于物体的变形与移动、场景照明变化以及视频序列中摄像头位置的变化,卷积神经网络在视频帧合成方面的表现并不出色。
近日,来自东南大学的研究者提出了一种新型的端到端架构,称为卷积 Transformer(ConvTransformer),用于视频帧序列学习和视频帧合成。ConvTransformer 的核心组件是文中所提出的注意力层,即学习视频序列序列依赖性的多头卷积自注意力。ConvTransformer 使用基于多头卷积自注意力层的编码器将输入序列映射到特征图序列,然后使用另一个包含多头卷积自注意层的深度网络从特征图序列中对目标合成帧进行解码。
在实验阶段的未来帧推断任务中,ConvTransformer 推断出的未来帧质量媲美当前的 SOTA 算法。研究者称这是 ConvTransformer 架构首次被提出,并应用于视频帧合成。
论文地址:https://arxiv.org/abs/2011.10185
如图 2 所示,ConvTransformer 的整体网络 G_θG 有 5 个主要组件:特征嵌入模块 F_θF、位置编码模块 P_θP、编码器模块 E_θE、查询解码器模块 D_θD 和综合前馈网络 S_θS。
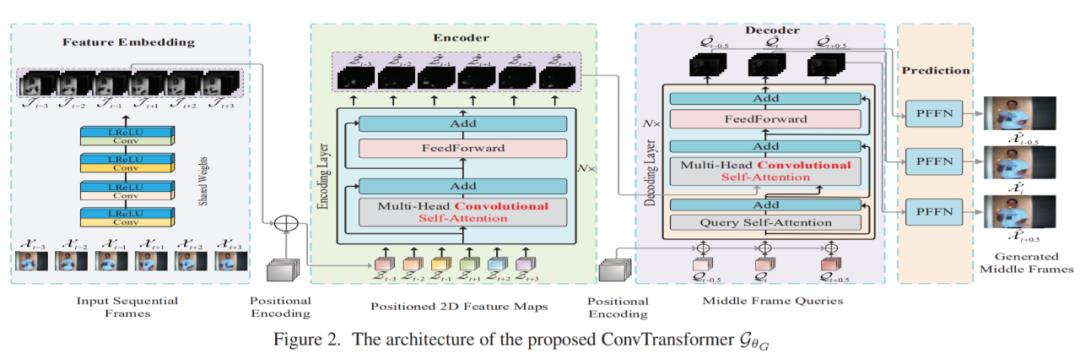
首先,特征嵌入模块嵌入输入的视频帧,然后生成表示性特征图。随后,将每个帧提取出的特征图与位置图相加,用于位置识别。然后,将位置帧特征图作为输入传递给编码器,以利用视频序列中每一帧之间的长距离序列依赖性。得到编码的高级特征图之后,将高级特征图和位置帧查询同时传递到解码器中,然后查询帧和输入视频序列之间的序列依赖性将被解码。最后,解码的特征图被馈入综合前馈网络(SFFN)以生成最终的中间插值帧或推断帧。
在实验部分,研究者通过与几种 SOTA 方法进行比较来评估所提出的 ConvTransformer。最后该研究还进行了控制变量实验,以验证 ConvTransformer 中每个组件的优势和有效性。
为了创建视频帧序列的训练集,该研究利用来自 Vimeo90K 数据集的帧序列,该数据集是用于视频帧合成的新建高质量数据集,另一方面,该研究还利用其他几个广泛使用的基准进行测试,包括 UCF101、Sintel、REDS、HMDB 和 Adobe240fps。
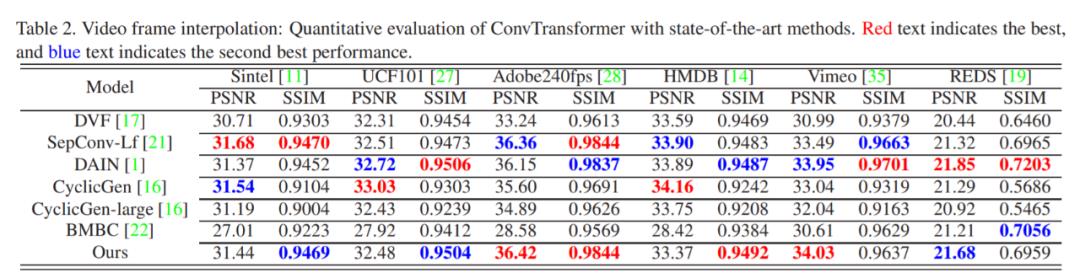
研究者将经过训练的 ConvTransformer 在几个公共基准上与 SOTA 视频插帧和视频帧推断算法进行比较,包括 DVF、MCNet、SepConv、CyclicGen、DAIN 和 BMBC。表 1 和表 2 分别说明了几种算法在视频插帧和未来帧推断方面的定量比较结果。

此外,带有缩放细节的合成图像视觉比较结果如图 1 和图 3 所示。

图 1:视频帧推断示例,上面是推断结果,中间是放大的局部细节,底部是根据实际情况计算出的遮挡图。
图 3:ConvTransformer 与其他视频插帧 SOTA 方法(DVF、SepConv、DAIN、CyclicGen、BMBC)的可视化比较结果。
「WAVE SUMMIT+2020 深度学习开发者峰会」由深度学习技术及应用国家工程实验室与百度联合主办,来自行业内的人工智能专家和开发者们将分享 AI 时代的最新技术发展和产业应用经验,诸多顶级高校人工智能专家将就 AI 人才培养展开对话,AI 开源产品及社区专家也将共话开源趋势。
本次峰会既有干货满满的分享、讨论,又有丰富多彩的展示、体验、互动,为开发者打造专属的 AI Party。
12 月 20 日,北京 798 艺术园区 751 罐,点击阅读原文,参与报名。
© THE END
投稿或寻求报道:content@jiqizhixin.com
以上是关于卷积神经网络与Transformer结合,东南大学提出视频帧合成新架构 ConvTransformer的主要内容,如果未能解决你的问题,请参考以下文章
消除视觉Transformer与卷积神经网络在小数据集上的差距
CNN和Transformer相结合的模型
第30篇Vision Transformer
第30篇Vision Transformer
结合Transformer模型与深度神经网络的数据到文本生成方法
Coatnet网络code