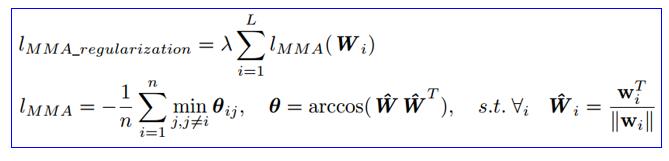提升模型泛化性能,MMA正则化:神经网络去相关性的正则化 Posted 2021-04-26 极市平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了提升模型泛化性能,MMA正则化:神经网络去相关性的正则化相关的知识,希望对你有一定的参考价值。
神经元或卷积核之间的强相关性会大幅削弱神经网络的泛化能力。本文从分析Tammes Problem出发,提出一种针对任意维度d和任意点数n的Tammes Problem的数值求解方法。进而将该方法应用到神经网络中,提出了一种新颖的神经网络正则化方法,减弱神经元或卷积核之间的相关性。 >>
神经元或卷积核之间的强相关性会大幅削弱神经网络的泛化能力。本文提出使归一化后的权重向量在单位超球面上尽可能分布均匀,从而减弱其相关性。而著名的Tammes Problem是均匀分布的评判标准之一。
本文从分析Tammes Problem出发,提出一种针对任意维度d和任意点数n的Tammes Problem的数值求解方法。进而将该方法应用到神经网络中,提出了一种新颖的神经网络正则化方法,减弱神经元或卷积核之间的相关性。
由于该方法使同层中的权重向量之间的最小夹角最大化(Maximizing the Minimal Angle),因此简称为MMA。
MMA正则化形式简单、计算复杂度低、效果明显,因此,可以作为神经网络模型的基本正则化策略
。本文通过大量的实验,证实了MMA正则化的有效性和广泛适用性。
王振楠:2020年博士毕业于深圳大学。博士期间研究课题为深度神经网络的角度正则化及其视觉应用,聚焦于深度学习的基础性研究,如正则化、归一化等,先后在ICCV和NeurIPS两个计算机领域顶级会议上发表论文。
本次分享内容主要是一种新颖的正则化方法,最小夹角最大化(Maximizing the Minimal Angle),因此简称为MMA。这个正则化的目的是使神经网络中的权重去相关性。
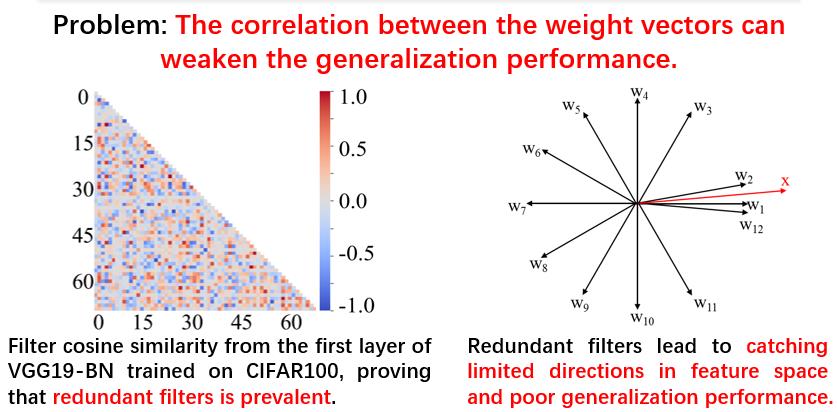
神经网络中权重向量的相关性过高的现象引起了很多的关注,很多论文对这一现象进行了讨论,这会造成模型的泛化性能降低,以下通过一个实验来说明这个问题的影响。
在CIFAR100中训练好的VGG19-BN,经过探究可以发现在很多层中,其权重向量相关性比较高,甚至会达到重合的程度,这里可视化了第一层的权重向量。可以看到左图中具有很多红色的点,其代表余弦为1,即夹角为0,表明其基本重合。这种现象会造成泛化性的降低。通过右边的示意图进一步的解释,如果权重向量相关性比较高,即W2、W1、W12基本上重合,那么和数据向量X内积之后数值接近。进一步的,在这种情况下这一层的计算得到的向量会有很多值非常接近,即表达能力变弱,对于整体模型而言就是泛化能力降低。
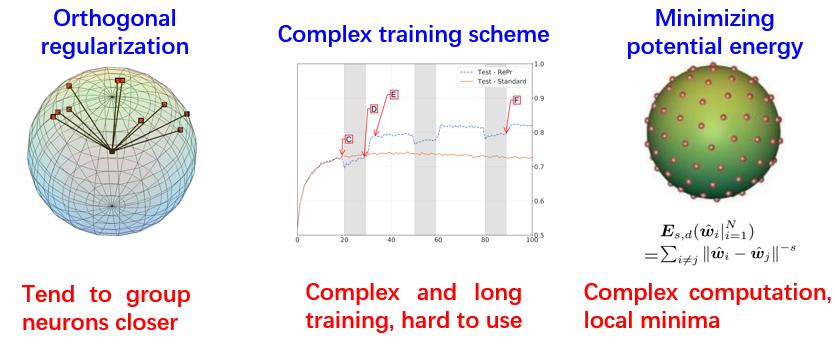
既然这个问题已经被研究了如此之久,那么如何解决也是有过很多尝试的,现有解决方案基本上可以分为这三类,
第一类是正交正则化,第二类是使用复杂训练方式,第三类是最小化势能函数。
对于正交正则化
,提出时间比较早,主要用于度量学习领域。正交正则化的目的是促使任意两个权重向量都达到正交。这个目的在某些情况下不一定成立,并且有论文分析发现这种正则化的效果使权重向量之间倾向于聚拢,效果不好。
对于使用复杂训练方式
,这个方法对于一个简单的分类,例如单个模型,训练模式虽然复杂,但是通过大量的代码还是可以实现,但是比如说对于更为复杂的模型,或本身就有很多种模型组合在一起的情况,实现方式困难。所以,这类方法也没有得到推广。
对于最小化势能函数
,其实是来源于Thomson Problem。Thomson Problem是任意n个点在任意d维的超球面上均匀分布的判定标准之一,其认为当势能函数最小化的时候,这些点达到均匀分布的状态。这个方案有很大的缺陷,第一个是计算复杂度特别高,需要计算大量欧式距离,第二个缺点是它里面有很多极小值点和驻点,优化困难。
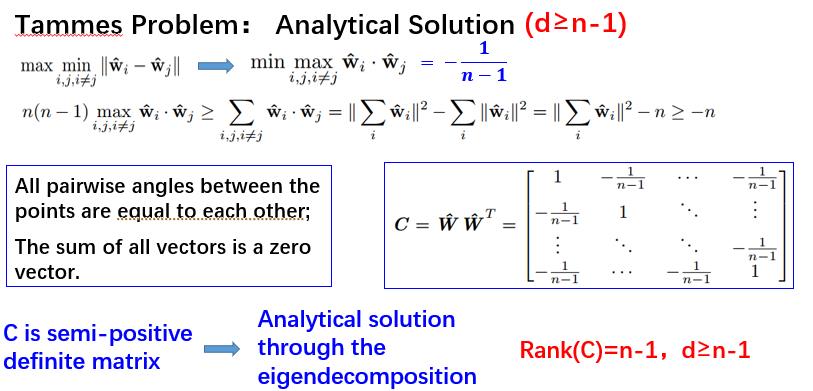
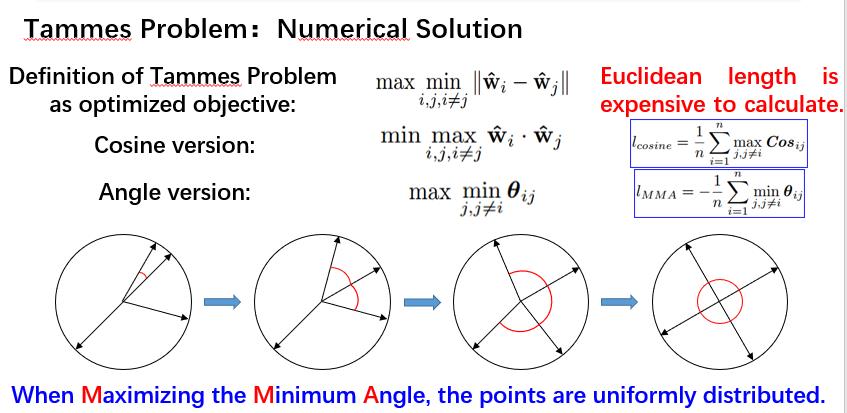
在本次分享中,出发点是使单位超球面上的权重向量均匀分布,使用了均匀分布的另外一种评价标准,称为Tammes Problem。Tammes Problem是荷兰的植物学家Tammes,在观察花粉的分布时提出的问题。经过数学领域的演化之后有一个严格的定义,在一个d维的超球面上,找到n个点的分布,使这n个点的最小欧氏距离最大化,那么这n个点就是均匀分布的。可以使用上图最右侧的数学表达式来表达最小欧式距离最大化的定义。
既然Tammes Problem在本文中是一个比较重要的工具,接下来就对它做一个比较详细的介绍。首先尝试通过解析的方法去求解,因为余弦和欧式距离成反比关系,所以
前面提到的最小欧式距离最大化等价于最大余弦距离的最小化
,通过n个向量和的模长的展开式进行推导,可以得到答案-1/(n-1)。
第一个不等号变等号的条件:
任意两个权重向量之间的夹角都是相等的,此时任意两个权重向量之间的余弦也是相等的,那么最大余弦距离也就等于平均余弦距离。
第二个不等号变等号的条件:
前面项为0 ,
这个矩阵有两个特征值,第一个是n/n-1,第二个是0,是一个标准的半正定矩阵。所以可以通过特征值分解求解,即得到权重矩阵W的解。但是需要注意的是,它的秩是n-1,所以要满足权重维度d,至少大于等于n-1才能得到这样一个解析解。当维度小于n-1时,只有少数n和d的组合,在数学领域有解,而大部分组合目前都没有解析解。
从上面的推论来看,对于任意维度d和点数n的组合而言是很难得出解析解的,但是可以采用优化的方式获得数值解。欧式距离的计算复杂,使得优化速度慢,但是最小欧式距离的最大化等价于最大余弦距离的最小化,也等价于最小夹角的最大化,所以
可以将余弦作为优化目标,或者将夹角作为优化目标
。
这里可能会有一个疑问:为什么当最小夹角最大化的时候,点或权重向量可以达到均匀分布的状态。这里通过一个简单示意图做出说明,在一个二维平面里面分布有四个权重向量,对它的夹角进行优化涉及到两个权重向量,即夹角的两个向量,当这两个向量分开直到两个夹角都相等,就会涉及到三个权重向量,再进一步的分开使得三个角都相等,就会涉及到4个权重向量,继续优化就会出现四个夹角相等的情况。
经过以上步骤,权重向量在二维平面就达到了均匀分布,同样的可以应用于高维空间,只不过不好去可视化表现出来。而这种方法称为最大化最小夹角,Maximizing the Minimal Angle,即MMA数值解法 。
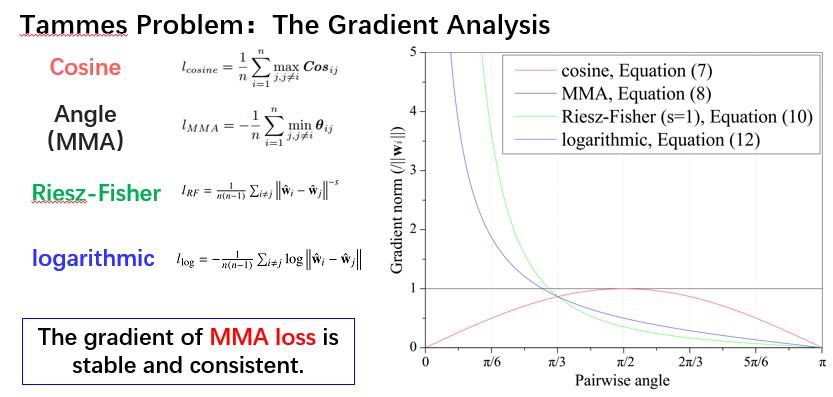
在前面的方法中提到过一种最小势能函数,其中有两个常用的,一个是RF,一个是对数。那么从梯度的角度对这两种和MMA和余弦方法做一个对比,对比结果如上图所示 。
图中横坐标表示夹角,纵坐标表示模长的变化。蓝色线和绿色线分别表示对数的势能函数和RF势能函数的梯度变化。从图中可以看出当夹角趋向于0的时候,两个函数的梯度趋向于无穷大,而随着夹角的变大,梯度又急剧下降,所以它们的梯度是很不稳定的,这对于优化而言并不合适。所以不管是从梯度方面,还是从函数中涉及大量的欧式距离计算,都会造成高空间复杂度和高时间复杂度。
红色的线代表余弦对于权重向量的梯度模长,当夹角比较小的时候,它比较小,当夹角大一些会有梯度,但是在点数较多且夹角比较小的情况下优化困难。
至于黑色的线,就是MMA方法,可以看到梯度是非常稳定。
对比之下MMA的梯度是最稳定的,不管夹角是多少。所以从梯度来说,使用夹角作为优化目标的MMA方法是比较有优势的。
对于MMA在神经网络中,可以把全连接层看作很多权重向量;对于卷积层,把filters拉成权重向量;所以,可以把MMA loss直接用到神经网络当中每一层,因此提出一种正则化方法,MMA Regularization。一个向量的两个基本属性,一个是模长,一个是方向(其相对方向,就是夹角),因此MMA可以和weight decay,也就是L2正则化实现互补。因为Weight decay沿着模长的方向去改变权重向量的模长,哪个权重向量的模长大,它的梯度就大,对它的惩罚就大。而MMA恰好改变它的方向,所以去改变权重向量两个基本属性。另外MMA既可以用到隐层,也可以用到分类层,隐层是权重向量或filter去相关性,分类层除了去相关性,还因为分类层每一个权重向量实际上是一个类别中心,所以它可以最大化类间距离,或者最大化类别区分度。
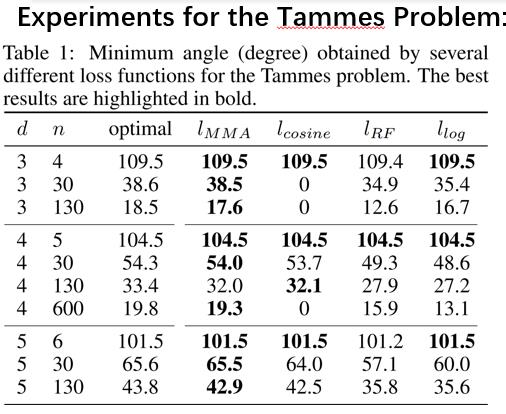
接下来是从多个角度进行的实验,前面提到过对于任意维度d和点数n实现均匀分布很少有理论解析解。上图是对Tammes Problem的一个实验,第一列是维度,第二列是点数,第三列是解析解最佳值,
第四列是MMA正则化方法,可以看到MMA得到的解和最佳解是非常接近的。
第五列是余弦方法,当能够优化时,与最佳值比较接近,但是效果不够稳定。第六列和第七列属于最小势能函数,其与最佳值有着较大的差异。
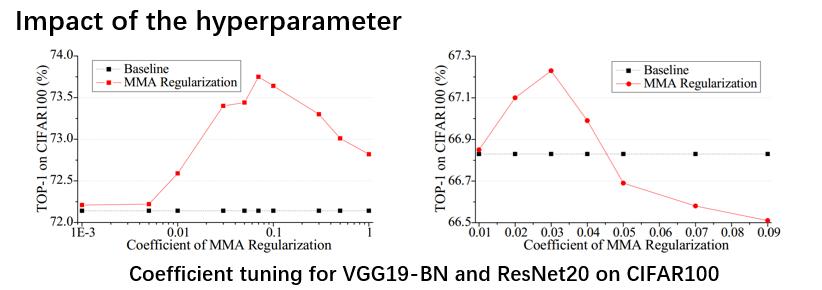
接下来是对超参数的实验,这里分为两类,分别是有跳层连接的和无跳层连接的。从结构上来说带有跳层连接的网络模型有一个优势就是它的权重向量之间的相关性本身就比较弱,但是使用MMA 正则化可以进一步使权重向量去相关性。这里使用VGG19-BN来代表没有跳层连接的模型,是左侧的图;ResNet20代表有跳层连接的模型,是右侧的图。分别做超参数实验。对于VGG19-BN,MMA正则化对超参数是不敏感的,从0.03~0.2都是可以work的。对有跳层连接的,因为本身相关性就不大,所以它对于超参数相对要敏感一些。
此外数据增强也属于正则化的一种方法,这里采用了比较强大的Autoaugment的方式进行实验。该方法创建一个数据增强策略的搜索空间,利用搜索算法选取适合特定数据集的数据增强策略。此外,从一个数据集中学到的策略能够很好地迁移到其它相似的数据集上。因为MMA和它的出发点是不同的,MMA可以继续在它的基础上提升效果。
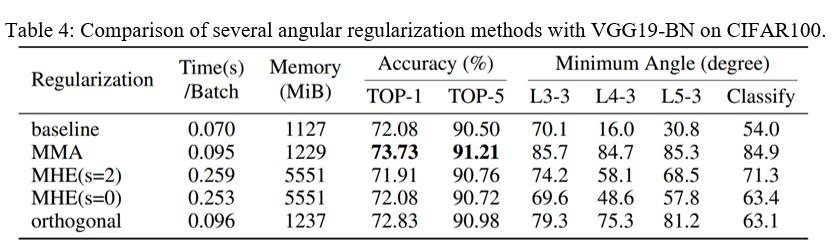
将前面提到的正交正则化,两个势能函数的正则化,本文提出的MMA正则化做对比。
首先从准确度来说,MMA正则的效果最好,提升量明显。
另外从时间复杂度和空间复杂度来说,MMA和正交正则额外消耗的时间和空间很少,但是势能函数的方法额外消耗了几倍的时间和空间。另外还发现一个规律,就是神经网络层当中,权重向量之间的相关性越小,也就是最小夹角越大,那么模型的泛化性能越高,上表中最后四列体现出了这一规律。
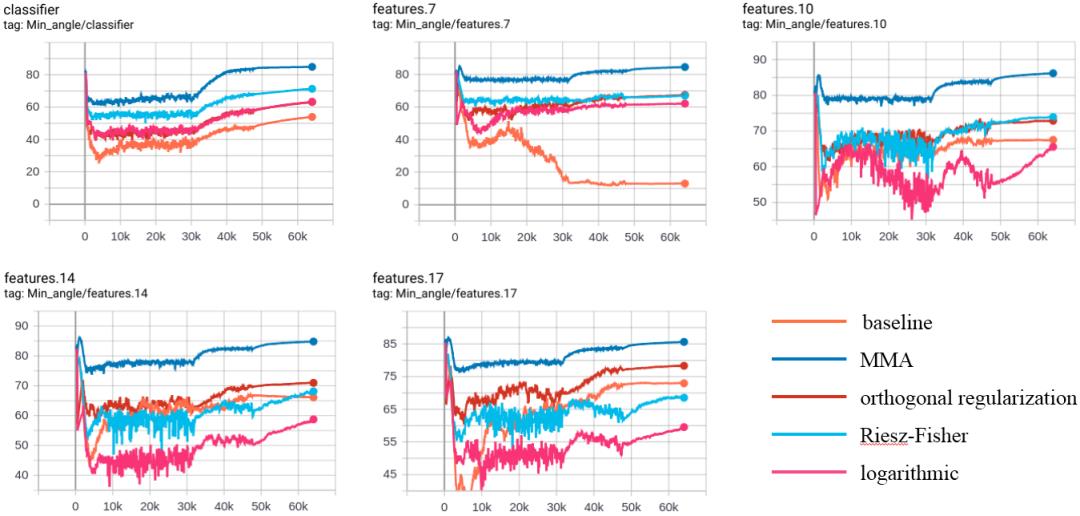
为了去验证是否会有最小夹角越大,模型泛化能力越高的规律,这里面选了其他的一些层。通过整个训练过程当中的可视化来看,可以看到
使用MMA正则化的方法每一层的权重向量之间的最小夹角都是最大的,也就说它的每一层的权重向量之间的相关性都是最弱的。
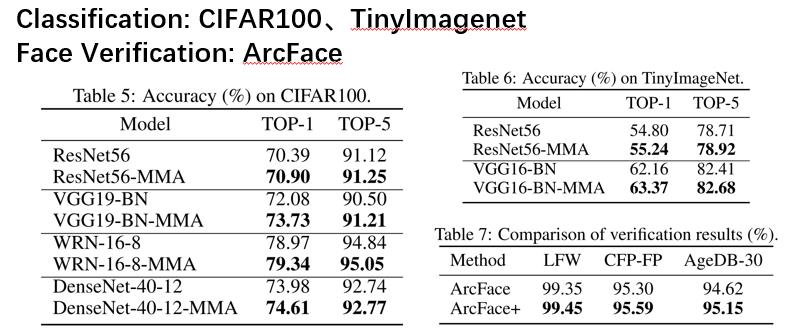
接下来就是在CIFAR100和TinyImageNet上使用了多个常用的经典网络模型,都是有效果的,并且对于VGG19的提升最明显。另外在人脸识别的ArcFace模型上进行了实验,因为人脸识别属于度量学习,ArcFace主要在Softmax交叉熵损失函数中增加了余量惩罚M。对人脸的最后一层添加MMA正则化,又出现了明显的提升。
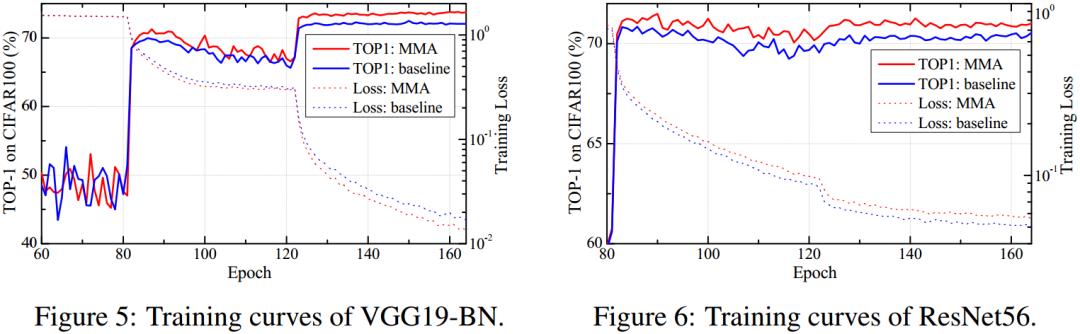
从分类任务的训练曲线可以看到,对收敛速度和稳定性都是没有影响的。也可以看到这个精度有一个持续的提升。
受到Tammes Problem的启发,本文提出它的一个数值解法,称之为MMA数值解法,它的解法原理是最小夹角添加负号作为损失函数,最后使得最小夹角最大化。
这个数值解法应用到神经网络当中,称之为MMA正则化。能够对权重向量去相关性。
这个方法具有明显优势,比现有方法最大的优势是方法轻便,效果明显,并且实现简单。
MMA Regularization: Decorrelating Weights of Neural Networks by Maximizing the Minimal Angles
https://papers.nips.cc/paper/2020/hash/dcd2f3f312b6705fb06f4f9f1b55b55c-Abstract.html
推荐阅读
添加极市小助手微信 (ID : cvmart2) ,备注: 姓名-学校/公司-研究方向-城市 (如:小极-北大-目标检测- 深圳),即可申请加入 极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解 等技术交流群: 每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+ 来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流 ~
以上是关于提升模型泛化性能,MMA正则化:神经网络去相关性的正则化的主要内容,如果未能解决你的问题,请参考以下文章
正则化处理
L1范数与L2范数正则化
Python机器学习及实践——进阶篇3(模型正则化之欠拟合与过拟合)
Python机器学习及实践——进阶篇3(模型正则化之欠拟合与过拟合)
正则化交叉验证泛化能力
线性模型 泛化优化 之 L1 L2 正则化