正则化处理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则化处理相关的知识,希望对你有一定的参考价值。
参考技术A过拟合本质上是模型太过复杂,复杂到消弱了模型的泛化能力。由于训练数据时有限的,因此总可以通过增加参数的的方式来提升模型的复杂度,降低训练误差。可正如你学习的领域越专精,可应用的范围可能越窄,则在模型训练中就是指过拟合。
如图所示的红色曲线就是过拟合。
正则化是用于抑制过拟合方法的统称,通过动态调整模型参数的取值 来降低模型的复杂度。这是因为当一些参数的取值足够小时,参数对应的属性对结果的影响微乎其微,这在实质上去除了非相关属性的影响。
在线性回归里,最常见的正则化方式就是在损失函数中添加正则化项,而添加的正则化项往往是待估计参数的 p- 范数。将均方误差和参数的范数之和作为一个整体来进行约束优化,相当于额外添加了一重关于参数的限制条件,避免大量参数同时出现较大的取值。由于正则化的作用通常是让参数估计值的幅度下降,因此在统计学中它也被称为系数收缩方法。
w1,w2都是模型的参数,要优化的目标参数。蓝色的圆圈表示没有经过限制的损失函数在寻找最小值过程中,w的不断迭代(随最小二乘法,最终目的还是使损失函数最小)变化情况,表示的方法是等高线,z轴的值就是 E(w)。
那个红色边框包含的区域,其实就是解空间,只能在这个缩小了的空间中,寻找使得目标函数最小的w1,w2。左边图是岭回归,是由于采用了L2范数正则化项的缘故,要求两个参数的平方和小于某个固定的参数,所以是圆形。右边的LASSO,是由于采用了L1范数作为正则化项,要求两个参数的绝对值之和小于某个固定值,所以解空间是方形。
图中蓝色和红色的交点就是最优参数解,交点出现的位子取决于边界的情况,岭回归的边界是曲线,误差等值线可以在任意位置和边界相切。LASSO边界是直线,因此切点最可能出现在方形的顶点上,这就意味着某个参数的取值为0。
岭回归 :衰减不同属性的权重,让所有属性向圆心收拢。
LASSO :直接将某些属性的权重降为0,是对属性的过滤筛选。
当属性的数目远远大于样本的数目的高纬度统计问题,并且不少属性间还存在着相关性时,建议使用LASSO回归来属性的数目。LASSO回归会让很多属性的系数变成0,保留一些系数较大的属性,这个时候系数的取值会对结果又较大影响,因此需要对属性的取值范围进行调整,比如标准化。
当样本数远大于属性数时,岭回归更快,岭回归不会删除属性,会对属性的取值范围进行压缩,特征值小的特征向量会被压缩的很厉害,因此要求属性的取值范围差不多,这样系数差不多,压缩更有意义。
参考资料:王天一,机器学习40讲。
吴恩达《机器学习》课程总结正则化
7.1过拟合的问题
训练集表现良好,测试集表现差。鲁棒性差。以下是两个例子(一个是回归问题,一个是分类问题)
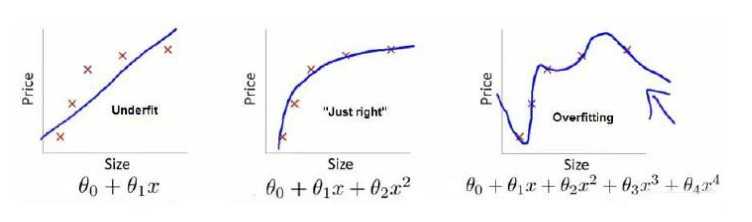
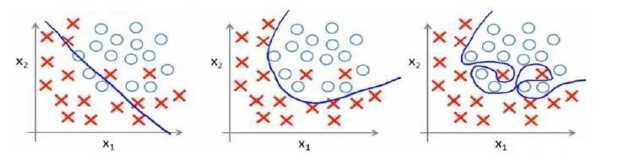
解决办法:
(1)丢弃一些不能帮助我们正确预测的特征。可以使用工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(PCA);
(2)正则化。保留素有的特征,但是减少参数的大小。
7.2代价函数
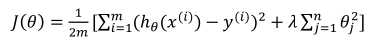
其中λ称为正则化参数。
经过正则化处理的模型和原模型的可能对比如如下:
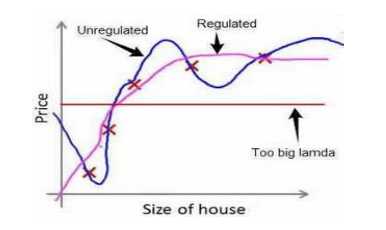
不对θ0正则化。
7.3正则化线性回归
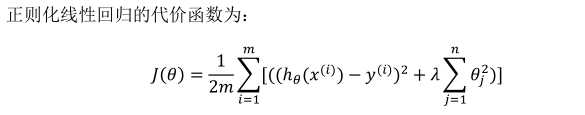
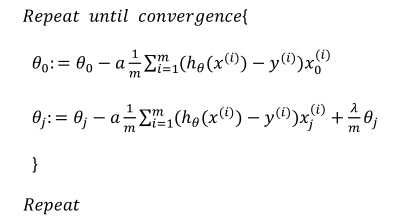
对于j=1,2,3……有:
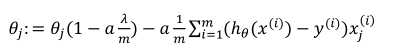
可以看出,正则化线性回归的梯度下降法的变化在于,每次都会在原有算法的更新规则的基础上令θ值减少了一个额外的值。
7.4正则化的逻辑回归模型
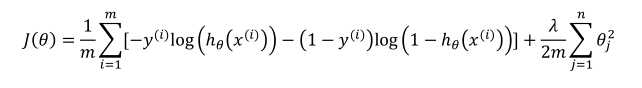
以上是关于正则化处理的主要内容,如果未能解决你的问题,请参考以下文章