业界 | 英特尔开源nGraph编译器:从多框架到多设备轻松实现模型部署
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业界 | 英特尔开源nGraph编译器:从多框架到多设备轻松实现模型部署相关的知识,希望对你有一定的参考价值。
选自ai.intel
机器之心编译
参与:刘晓坤、李亚洲
近日,英特尔的人工智能产品团队宣布开源 nGraph,这是一个面向各种设备和框架的深度神经网络模型编译器。有了 nGraph,数据科学家能够专注于数据科学研发,不需要担心如何将 DNN 模型部署到各种不同设备做高效训练和运行。
图 1:nGraph 生态系统
nGraph 目前直接支持 TensorFlow、MXNet 以及 neon,并可间接地通过 ONNX 支持 CNTK、PyTorch、Caffe2。用户能够在不同的设备上运行这些框架: 英特尔架构、GPU 和 英特尔 Nervana 神经网络处理器(NNP)。
为什么建立 nGraph
当深度学习框架作为模型训练和推断的工具首次出现时,在设计上是围绕 kernel 为特定设备优化。结果,把深度学习模型部署到其它更先进的设备时,会在模型定义暴露出许多细节问题,从而限制了其适应性和可移植性。
使用传统的方法意味着算法开发者面临把模型升级到其他设备时的沉闷工作。使一个模型能够在不同框架上运行也非常困难,因为开发者必须把模型的本质从对设备的性能调整中分离出来,并转化到新框架中的相似运算,最终在新框架上为优选的设备配置做必要的改变。
我们设计的 nGraph 库充分地减少了这些工程的复杂性。虽然通过该项目以及英特尔的 MKL-DNN 这样的库,能够为深度学习原语提供优化核,但仍有多种编译器启发式的方法能够带来进一步的优化。
nGraph 是如何工作的?
安装 nGraph 库,并使用该库编写或编译一个框架来训练模型和执行模型推理。将 nGraph 指定为框架后端,以在任意支持的系统上用命令行运行该库。我们的中间表征(Intermediate Representation,IR)层可以处理所有的设备抽象细节,从而让开发者集中于数据科学、算法和模型的研究,不需要花费太多精力在写代码上。
从更加详细的角度来说:
nGraph 核心创建了计算过程的一种强类型和设备无关的无状态图表征。图中的每一个节点或运算对应计算的一个步骤,其中每个步骤从 0 或更多张量的输入中生成 0 或更多张量的输出。我们的思想是 nGraph 运算可以作为深度学习框架中的复杂 DNN 操作的构建模块,且它能根据需要而衡量是高效编译和推导训练计算还是推断计算。
我们为每个支持的框架开发了框架桥梁(framework bridge);它作为 nGraph 核心和框架之间的媒介起作用。目前我们已经开发了 TensorFlow/XLA、MXNet 和 ONNX 的框架桥梁。由于 ONNX 仅仅是一种交换格式,因此 ONNX 的桥梁将通过执行 API 进行增强。
在 nGraph 核心和多种设备之间工作的变换器有着类似的作用;变换器使用通用的和设备特定的图转换处理设备抽象。得到的结果是一个函数,可以从框架桥梁执行。变换器是可分配和可解除分配的,可按桥梁的方向读取和写入张量。我们目前已有英特尔架构、英特尔 NNP、英伟达 cuDNN 的变换器,并正积极开发着其它设备的变换器。
当前的性能
对于 Intel Architecture 上的框架的 MKL-DNN 优化,英特尔拥有大量的开发经验。我们借用了以前的工作带来的附加效益,使得通过 nGraph 为一个设备开发的优化方法可以为所有框架带来效益。框架开发者可以继续完善优化工作。例如,Intel Architecture 上的 TensorFlow 1.7+/XLA 的优化效果远远好于 Intel Architecture 上的 TensorFlow 1.3/XLA 的优化效果,因此随着更多工作投入到 Intel Architecture 上的 XLA,这种情况将会得到改善。
下图中展示了多个框架上的原始性能数据和优化性能数据,可以反映 nGraph 在 Intel Architecture 变换器上的优化带来的效益。在最新的 Intel Xeon Platinum 8180 处理器上,通过同时使用 MKLDNN v0.13,我们可以达到甚至超越之前已优化的框架的性能,例如 MXNet-MKLDNN-CPU(用 MKL-DNN 优化的 MXNet),以及 neon-MKLML-CPU(用 MKLML 优化的 neon)。我们还得到了比 TensorFlow XLA 编译器(TF-XLA-CPU)更好的性能,但在默认的 CPU 实现和 nGraph 上,还可以使用 XLA 做相当多的优化工作。
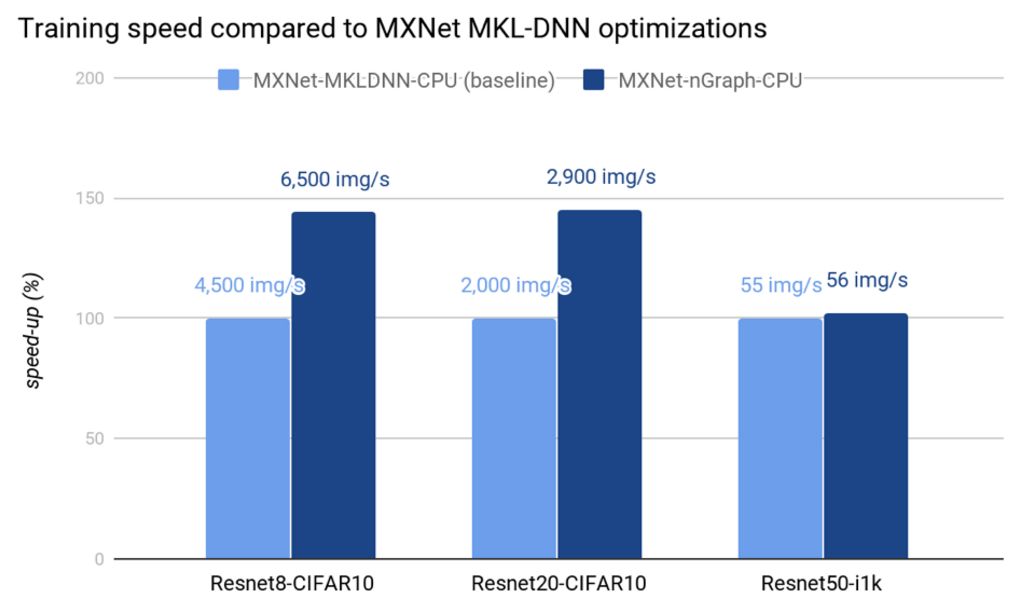
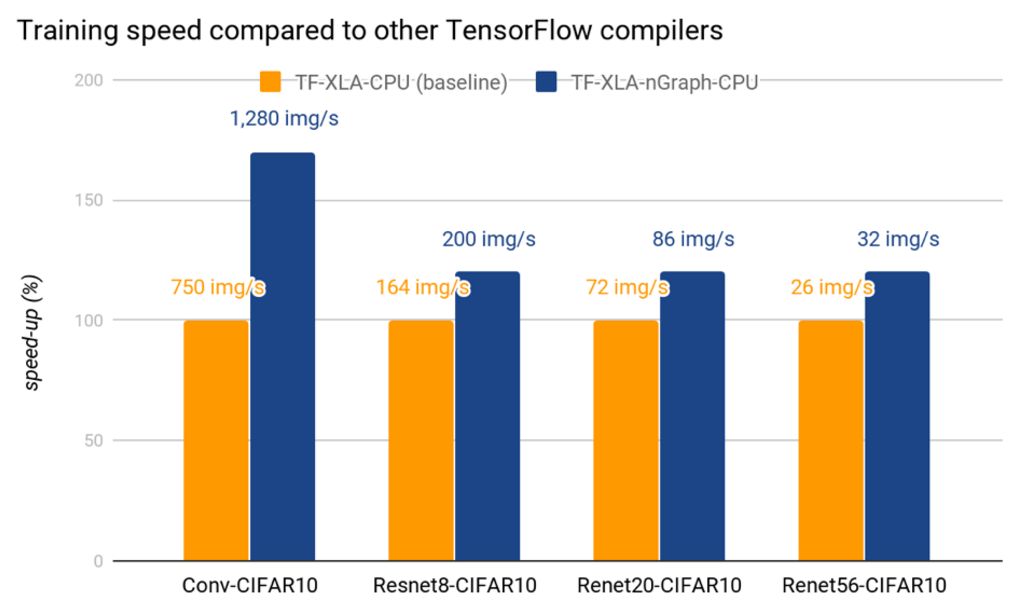
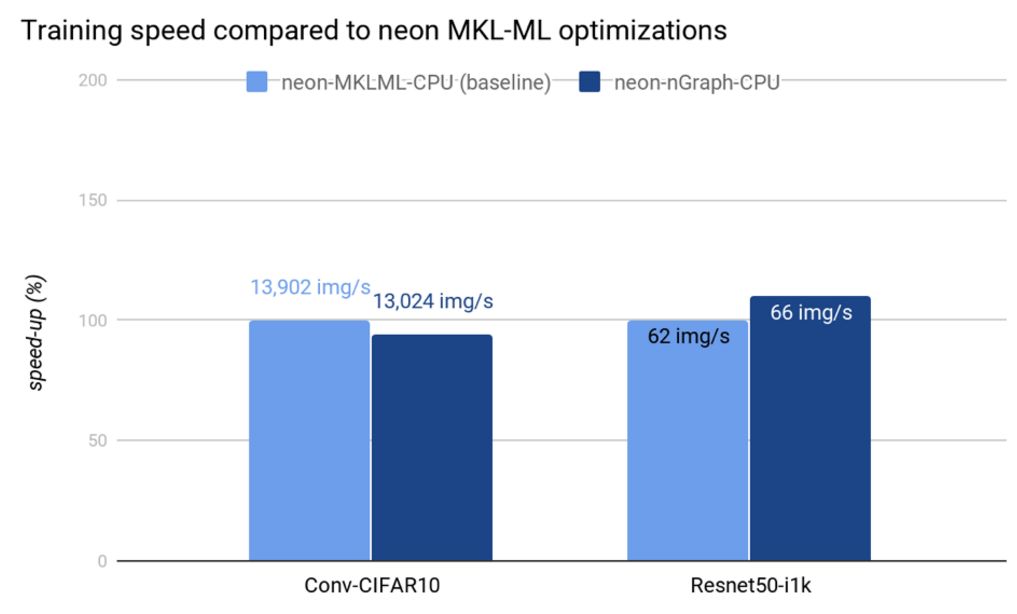
现状和未来工作
自今天起,nGraph 支持 6 个深度学习框架和三个计算设备。
支持的框架:
1.通过 nGraph 的框架独立表征直接支持的框架:
TensorFlow
MXNet
neon
2.通过 ONNX 间接支持的框架:
CNTK
PyTorch
Caffe2
支持的计算设备:
英特尔架构 (x86、Intel® Xeon® 和 Xeon Phi®)
Intel® Nervana™ 神经网络处理器 (Intel® Nervana NNP)
英伟达 cuDNN (进行中)
我们将继续支持更多的设备、更多的图优化(例如特定设备的运算融合)、更好的工作进度表以及在运算 kernel 上更快的自定义。
论文:Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
论文链接:https://arxiv.org/abs/1801.08058
深度学习(DL)社区每年都会发布非常多的拓扑结构实现。而在每一个新的拓扑结构中实现高性能计算仍然是非常大的挑战,因为每一个结构都需要一定的人力调整。这个问题由于框架和硬件平台的激增而变得越发复杂。目前我们称之为「直接优化」的方法需要在每个框架上进行深入的修改以在每一个硬件后端(CPU、GPU、FPGA 和 ASIC)提升训练性能,且要求 O(fp) 的复杂度;其中 f 为框架的数量,p 为平台的数量。虽然深度学习基元的优化核可以通过 MKL-DNN 等库提供支持,但目前有几种编译器启发的方式能实现进一步的优化。基于我们构建 neon(GPU 上的快速深度学习库)的经验,我们开发了 Intel nGraph,即一个用于在跨框架和硬件平台间简化深度学习的性能优化过程的开源 C++库。
该工具最初支持的框架包含 TensorFlow、MXNet 和 Intel neon 框架,最初支持的后端为 Intel Architecture 的 CPU、Intel(R) Nervana 神经网络处理器(NNP)和英伟达 GPU。目前支持的编译器优化包括高效内存管理和数据布局提取。在本论文中,我们描述了该工具的整体架构与核心组件。未来,我们希望 nGraph 的 API 支持扩展到更广泛的框架、硬件(包括 FPGA 和 ASIC)和编译器优化(训练 vs 推断优化、通过高效子图分割的多节点和多设备扩展、特定硬件的复合操作)。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于业界 | 英特尔开源nGraph编译器:从多框架到多设备轻松实现模型部署的主要内容,如果未能解决你的问题,请参考以下文章