支持向量机及Python代码实现
Posted 大数据挖掘DT数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机及Python代码实现相关的知识,希望对你有一定的参考价值。
网址:datadm.taobao.com
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子。他的理论很优美,各种变种改进版本也很多,比如latent-SVM, structural-SVM等。这节先来看看SVM的理论吧,在(图一)中A图表示有两类的数据集,图B,C,D都提供了一个线性分类器来对数据进行分类?但是哪个效果好一些?
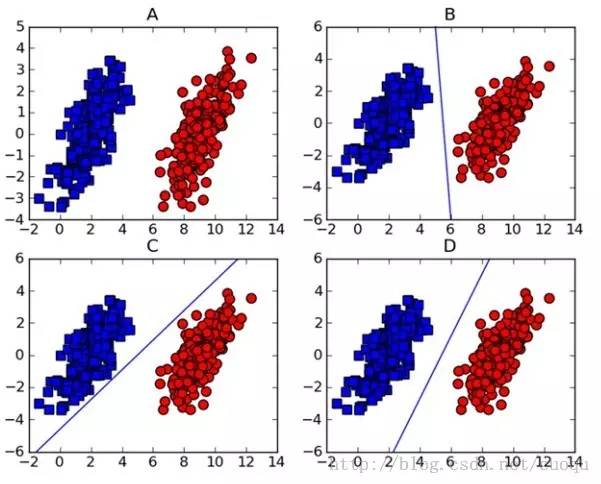
(图一)
可能对这个数据集来说,三个的分类器都一样足够好了吧,但是其实不然,这个只是训练集,现实测试的样本分布可能会比较散一些,各种可能都有,为了应对这种情况,我们要做的就是尽可能的使得线性分类器离两个数据集都尽可能的远,因为这样就会减少现实测试样本越过分类器的风险,提高检测精度。这种使得数据集到分类器之间的间距(margin)最大化的思想就是支持向量机的核心思想,而离分类器距离最近的样本成为支持向量。既然知道了我们的目标就是为了寻找最大边距,怎么寻找支持向量?如何实现?下面以(图二)来说明如何完成这些工作。
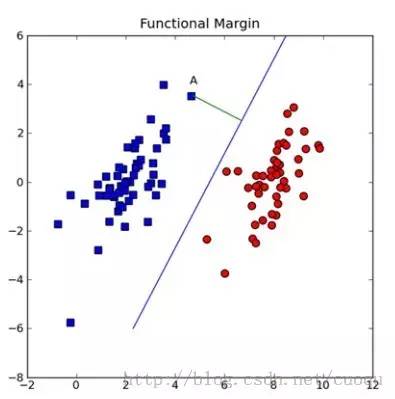
(图二)
假设(图二)中的直线表示一个超面,为了方面观看显示成一维直线,特征都是超面维度加一维度的,图中也可以看出,特征是二维,而分类器是一维的。如果特征是三维的,分类器就是一个平面。假设超面的解析式为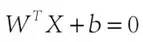 ,那么点A到超面的距离为
,那么点A到超面的距离为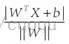 ,下面给出这个距离证明:
,下面给出这个距离证明:
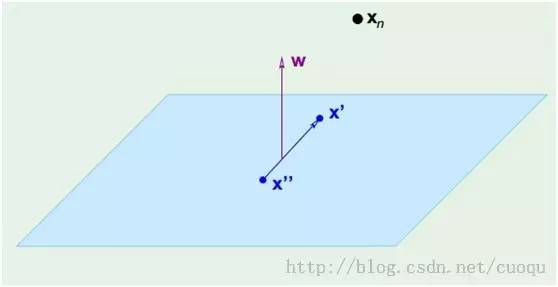
(图三)
在(图三)中,青色菱形表示超面,Xn为数据集中一点,W是超面权重,而且W是垂直于超面的。证明垂直很简单,假设X’和X’’都是超面上的一点,
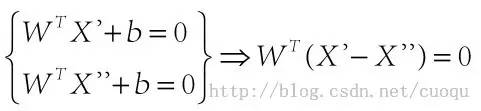
,因此W垂直于超面。知道了W垂直于超面,那么Xn到超面的距离其实就是Xn和超面上任意一点x的连线在W上的投影,如(图四)所示:
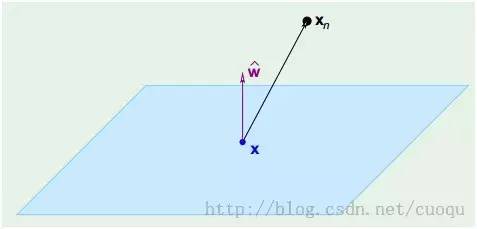
(图四)
而(Xn-X)在W上的投影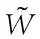 可通过(公式一)来计算,另外(公式一)也一并完成距离计算:
可通过(公式一)来计算,另外(公式一)也一并完成距离计算:
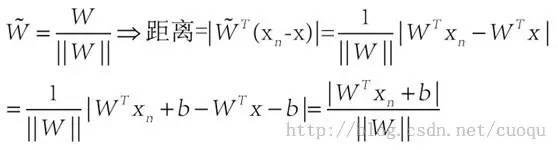
(公式一)
注意最后使用了配项法并且用了超面解析式才得出了距离计算。有了距离就可以来推导我们刚开始的想法:使得分类器距所有样本距离最远,即最大化边距,但是最大化边距的前提是我们要找到支持向量,也就是离分类器最近的样本点,此时我们就要完成两个优化任务,找到离分类器最近的点(支持向量),然后最大化边距。如(公式二)所示:
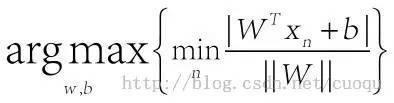
(公式二)
大括号里面表示找到距离分类超面最近的支持向量,大括号外面则是使得超面离支持向量的距离最远,要优化这个函数相当困难,目前没有太有效的优化方法。但是我们可以把问题转换一下,如果我们把大括号里面的优化问题固定住,然后来优化外面的就很容易了,可以用现在的优化方法来求解,因此我们做一个假设,假设大括号里的分子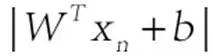 等于1,那么我们只剩下优化W咯,整个优化公式就可以写成(公式三)的形式:
等于1,那么我们只剩下优化W咯,整个优化公式就可以写成(公式三)的形式:

(公式三)
这下就简单了,有等式约束的优化,约束式子为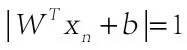 ,这个约束等式背后还有个小窍门,假设我们把样本Xn的标签设为1或者-1,当Xn在超面上面(或者右边)时,带入超面解析式得到大于0的值,乘上标签1仍然为本身,可以表示离超面的距离;当Xn在超面下面(或者左边)时,带入超面解析式得到小于0的值,乘上标签-1也是正值,仍然可以表示距离,因此我们把通常两类的标签0和1转换成-1和1就可以把标签信息完美的融进等式约束中,(公式三)最后一行也体现出来咯。下面继续说优化 求解(公式四)的方法,在最优化中,通常我们需要求解的最优化问题有如下几类:
,这个约束等式背后还有个小窍门,假设我们把样本Xn的标签设为1或者-1,当Xn在超面上面(或者右边)时,带入超面解析式得到大于0的值,乘上标签1仍然为本身,可以表示离超面的距离;当Xn在超面下面(或者左边)时,带入超面解析式得到小于0的值,乘上标签-1也是正值,仍然可以表示距离,因此我们把通常两类的标签0和1转换成-1和1就可以把标签信息完美的融进等式约束中,(公式三)最后一行也体现出来咯。下面继续说优化 求解(公式四)的方法,在最优化中,通常我们需要求解的最优化问题有如下几类:
(i)无约束优化问题,可以写为:
min f(x);
(ii)有等式约束的优化问题,可以写为:
min f(x),
s.t. h_i(x) = 0; i =1, ..., n
(iii)有不等式约束的优化问题,可以写为:
min f(x),
s.t. g_i(x) <= 0; i =1, ..., n
h_j(x) = 0; j =1,..., m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(LagrangeMultiplier),即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
而(公式三)很明显符合第二类优化方法,因此可以使用拉格朗日乘子法来对其求解,在求解之前,我们先对(公式四)做个简单的变换。最大化||W||的导数可以最小化||W||或者W’W,如(公式四)所示:

(公式四)
套进拉格朗日乘子法公式得到如(公式五)所示的样子:
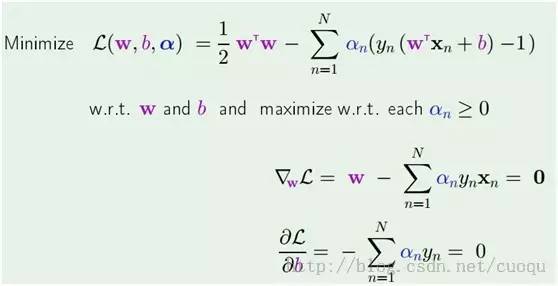
(公式五)
在(公式五)中通过拉格朗日乘子法函数分别对W和b求导,为了得到极值点,令导数为0,得到

,然后把他们代入拉格朗日乘子法公式里得到(公式六)的形式:
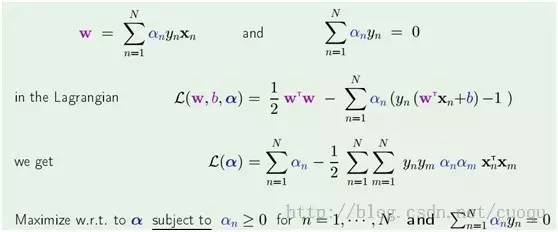
(公式六)
(公式六)后两行是目前我们要求解的优化函数,现在只需要做个二次规划即可求出alpha,二次规划优化求解如(公式七)所示:

(公式七)
通过(公式七)求出alpha后,就可以用(公式六)中的第一行求出W。到此为止,SVM的公式推导基本完成了,可以看出数学理论很严密,很优美,尽管有些同行们认为看起枯燥,但是最好沉下心来从头看完,也不难,难的是优化。二次规划求解计算量很大,在实际应用中常用SMO(Sequential minimal optimization)算法,SMO算法打算放在下节结合代码来说。
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:就是训练集是线性可分的,这样求出的alpha在[0,infinite]。但是如果数据不是线性可分的呢?此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量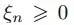 即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时
即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时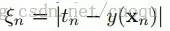 ,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时
,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时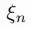 肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
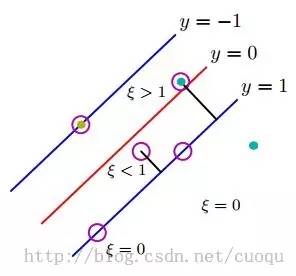
(图五)
这样有了错分类的代价,我们把上节(公式四)的目标函数上添加上这一项错分类代价,得到如(公式八)的形式:
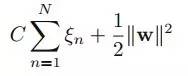
(公式八)
重复上节的拉格朗日乘子法步骤,得到(公式九):
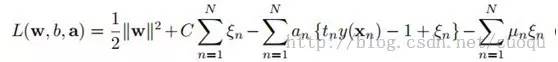
(公式九)
多了一个Un乘子,当然我们的工作就是继续求解此目标函数,继续重复上节的步骤,求导得到(公式十):
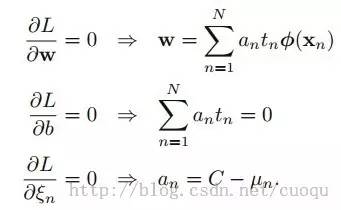
(公式十)
又因为alpha大于0,而且Un大于0,所以0<alpha<C,为了解释的清晰一些,我们把(公式九)的KKT条件也发出来(上节中的第三类优化问题),注意Un是大于等于0:
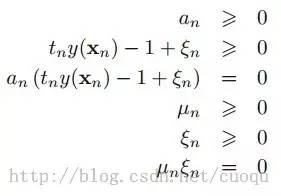
推导到现在,优化函数的形式基本没变,只是多了一项错分类的价值,但是多了一个条件,0<alpha<C,C是一个常数,它的作用就是在允许有错误分类的情况下,控制最大化间距,它太大了会导致过拟合,太小了会导致欠拟合。接下来的步骤貌似大家都应该知道了,多了一个C常量的限制条件,然后继续用SMO算法优化求解二次规划,但是我想继续把核函数也一次说了,如果样本线性不可分,引入核函数后,把样本映射到高维空间就可以线性可分,如(图六)所示的线性不可分的样本:

(图六)

(图七)
这样就有了f,而核函数此时相当于对样本的X和基准点一个度量,做权重衰减,形成依赖于x的新的特征f,把f放在上面说的SVM中继续求解alpha,然后得出权重就行了,原理很简单吧,为了显得有点学术味道,把核函数也做个样子加入目标函数中去吧,如(公式十一)所示:
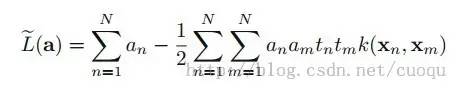
(公式十一)
其中K(Xn,Xm)是核函数,和上面目标函数比没有多大的变化,用SMO优化求解就行了,代码如下:
[python]
def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
下面演示一个小例子,手写识别。
(1)收集数据:提供文本文件
(2)准备数据:基于二值图像构造向量
(3)分析数据:对图像向量进行目测
(4)训练算法:采用两种不同的核函数,并对径向基函数采用不同的设置来运行SMO算法。
(5)测试算法:编写一个函数来测试不同的核函数,并计算错误率
(6)使用算法:一个图像识别的完整应用还需要一些图像处理的只是,此demo略。
完整代码如下:(此处有删节)
在此公众号回复“支持向量机”可获取本文word版,包括代码和数据集。更多资料加微信:hai299014
~~针对校园资料领取问题,小编统一答复大家:
【1】店铺展示图片都是直接从电子书截图过来的,清晰度就是那样了,PDF资料都是完整版的,若发现问题,请及时通过邮箱或微信联系小编;
【2】提醒再提醒:一定要在订单备注栏 填写邮箱,以便发资料;
以上是关于支持向量机及Python代码实现的主要内容,如果未能解决你的问题,请参考以下文章