支持向量机的理论基础
Posted 老王AI路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机的理论基础相关的知识,希望对你有一定的参考价值。
我写硕士论文那时候(2010年左右),研究支持向量机的论文大多是这样介绍它的:
支持向量机(Support Vector Machine)是Vapnik等人于1995年首先提出的,它在解决小样本、非线性及高维度模式识别问题中表现出许多特有的优势,SVM是建立在统计学习理论的VC维概念和结构风险最小原理基础上的,根据有限的样本信息在模型复杂性和学习能力之间需求最佳折中,以期获得最好的泛化能力。
下面的内容整理自我的论文、统计学习理论书籍及网络。
统计学习理论
传统「统计学」关注估计的一致性、无偏性和估计方差的界、分类错误率等的渐进性特征,在实际应用中往往无法满足(实际中样本无法趋于无穷),而这种问题在高维空间时尤其如此,当时这被认为是包括神经网络在内的机器学习方法的一个根本难题。Vapnik等人在20世纪60年代就开始研究有限样本情况下的机器学习问题,不过直到90年代中,有限样本情况下的机器学习理论才逐渐成熟起来,形成了一个较完善的理论体系——统计学习理论。
结合数学公式说明一下,基于传统统计学的机器学习方法这样描述「学习问题」:
机器学习的目的是求出对某系统输入输出之间关系的估计,使它能够对未知输出做出尽可能准确的预测。设y与x是存在一定未知依赖关系的两个变量,即它们遵循某个未知的联合概率F(x,y),学习问题可描述为,根据n个独立同分布训练样本,(x1, y1),(x2, y2)…(xn, yn),求任意预测函数集合{f(x,w)}中的最优函数f(x,w0),使预测的期望风险最小:
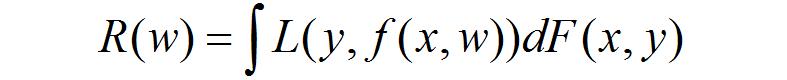
其中,{f(x,w)}称为预测函数集,w为函数的广义参数,L(y, f(x,w))是用{f(x,w)}预测出y造成的损失。不同类型的学习问题会有不同的损失函数。对于模式识别问题来说,输出y是类别标号,比如两类情况下y={0,1},预测函数称为指示函数,损失函数可以定义为:
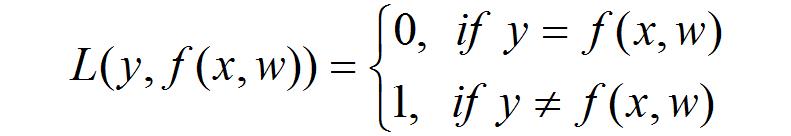
此时,期望风险即是平均错误率,使它最小的学习方法用贝叶斯决策:若正常状态下x的类别条件概率密度大于异常状态下的,则x属于正常状态。然而,我们无法计算期望风险的值,因为我们只有样本数据,而无法知道联合分布F(x,y)。根据概率论中的大数定理,用数学平均估计期望风险得:
调整参数w使经验风险Remp最小,就是经验风险最小化(Empirical risk minimization,ERM)原则。经验风险最小化理论在机器学习方法研究中占据了重要地位,但却没有充分的证据支撑ERM原则,假定当n趋向与无穷大时,Remp趋于R(w),在很多问题中,样本的数量是离无穷大想去甚远的。关于这个问题,1971年Vapnik就曾指出ERM的最小值未必收敛于期望风险的最小值。经验风险最小化原则属于传统的统计学得范畴,当训练点个数很大时,它是一个十分合理的选择,因此此时经验风险大体能代替期望风险。但是,当训练点个数不很大,特别是个数较小时,经验风险和期望风险会有较大的差别,在这种情况下如何更确切地估计期望风险,从而改进经验风险最小化原则正是统计学习理论所研究的内容。
VC维和推广性的界
经验风险最小化原则是在决策函数候选集中选取使其经验风险达到最小的函数作为决策函数。在这里,集合F是事先取定的,统计学习理论则是同时考虑集合F的选取,即考虑集合F对期望风险的作用。为此首先需要给出一个描述集合F的大小的定量指标,这就是由Vapnik和Chervonenkis提出的「VC维」。VC维表征了学习过程一致收敛的速度和推广性,定量地反映了学习机器的复杂性与训练样本数的联合作用对推广能力的影响。VC维是对函数类的一种度量,可以简单的理解为问题的复杂程度,VC维越高,一个问题就越复杂。正是因为SVM关注的是VC维,我们可以看到SVM解决问题的时候,和样本的维数是无关的。
统计学习理论从VC维的概念出发,又提出「推广性的界」的概念,它直观地反映了「经验风险」与真实风险之间的关系。对指示函数中的函数,经验风险Remp(w)和实际风险R(w)之间以至少1-η的概率满足如下关系:
其中,h是函数集的VC维,n是样本数。推广的界将学习的实际风险分为两部分:1)经验风险;2)置信范围:与VC维和训练样本数有关。由上面的式子可知,要使学习过程的实际风险较小,即对未来样本有较好的推广性,需要使经验风险最小、同时使VC维尽量小。
结构风险最小化
虽然可以通过经验调整置信范围,使置信范围最小,但由于缺乏理论指导,造成对使用者技巧的过分依赖。统计学习理论提出了一种新的策略,即结构风险最小化(Structural Risk Minimization,简称SRM)。把函数集S={f(x,w)}分解为一个函数序列:S1S2… Sk… S,使各个子集能够按对应的VC维大小排列,即h1h2… hk… h,这样就可以在同一个子集相同的置信范围内,寻找每个子集的最小经验风险。然后再选择使置信范围与「经验风险」的和最小的子集。
怎么理解上面提到的「学习过程一致性」、「经验风险」、「推广性的界」等概念呢?
机器学习本质上就是一种对问题真实模型的逼近,但毫无疑问,真实模型一定是不知道的,这个与问题真实解之间的误差,就叫做「风险」。选了一个假设之后,真实误差无从得知,但我们可以用某些可以掌握的量来逼近它。最直观的想法就是使用分类器在样本数据上的分类的结果与真实结果(因为样本是已经标注过的数据,是准确的数据)之间的差值来表示,这个差值就叫做经验风险。以前的机器学习方法都把经验风险最小化作为努力的目标,但后来发现很多分类函数能够在样本集上轻易达到100%的正确率,在真实分类时却错的一塌糊涂(推广能力差或泛化能力差)。此时的情况便是选择了一个足够复杂的分类函数(它的VC维很高),能够精确的记住每一个样本,但对样本之外的数据一律分类错误,因此我们发现,经验风险最小化原则的大前提是经验风险要确实能够逼近真实风险才行,这就是所谓的「学习过程一致性」。
而「推广性的界」是指真实风险应该由两部分内容刻画,一是经验风险,代表了分类器在给定样本上的误差;二是置信风险,代表了在多大程度上可以信任分类器在未知样本上分类的结果。很显然第二部分是没办法精确计算的,因此只能给出一个估计的区间,也使得整个误差只能计算上界,而无法计算准确的值,所以叫推广性的界。置信风险与两个量有关,一是样本数量,显然给定的样本数量越大,我们的学习结果越有可能正确,此时置信风险越小;二是分类函数的VC维,显然VC维越大,推广能力越差,置信风险会变大。统计学习的目标从经验风险最小化变为了经验风险与置信风险的和最小,即结构风险最小。
总之,统计学习理论告诉我们机器学习不是伪科学,告诉了我们机器学习方法的通用原理。与统计机器学习的精密思维相比,传统的机器学习基本上属于摸着石头过河,用传统的机器学习方法构造分类系统完全成了一种技巧,一个人做的结果可能很好,另一个人差不多的方法做出来却很差,缺乏指导和原则。SVM正是这样一种努力最小化结构风险的算法,这是人们认为SVM好于神经网络的原因之一,而当时,神经网络等机器学习方法的研究则遇到了一些重要的困难,比如如何确定网络结构的问题、过学习与欠学习的难题、局部极小点的问题等。
SVM的另一个优点是小样本分类,而这并不是说SVM不适合大规模数据,只是SVM在小样本训练集上能够得到比其它算法好很多的结果。SVM之所以流行在于其优秀的泛化能力,这是因为其本身的优化目标是结构风险最小,而不是经验风险最小,通过margin的概念,得到对数据分布的结构化描述,因此减低了对数据规模和数据分布的要求。而大规模数据上,也并没有实验和理论证明表面SVM会差于其它分类器。
然而,Yann LeCun有不同的看法,关于深度学习与支持向量机/统计学习理论的联系,他在接受采访时曾说:
90年代初,我和Vapnik一起在贝尔实验室共事,在此期间相继提出了一些后来有影响力的算法:卷积神经网络,支持向量机,切线距离等。1995年,AT&T从朗讯科技公司(LUCENT)独立出来,我则出任了AT&T实验室图像处理研究组的负责人,组内机器学习相关的研究员包括:Yoshua Bengio, Leon Bottou, and Patrick Haffner, and Vladimir Vapnik。
我和Vapnik经常一起深入讨论(深度)神经网络和核方法(kernel machines)的优缺点。简单来讲,我一直对学习特征表示很感兴趣,对核方法并不十分感冒,因为它对我想解决的问题没有直接的帮助。事实上,支持向量机是一个具有很好数学基础的分类方法,但它本质上也只不过是一个简单的两层方法:第一层可以看作是一些单元集合(一个支持向量就是一个单元),这些单元通过核函数能够度量输入向量和每个支持向量的相似度;第二层则把这些相似度做了简单的线性累加。支持向量机第一层的训练和最简单的无监督学习基本一致:利用支持向量来表示训练样本。一般来讲,通过调整核函数的平滑性(参数)能在线性分类和模板匹配之间做出平衡。从这个角度来讲,核函数只不过是一种模板匹配方法,我也因此在大约10年前就意识到了其局限性。另一方面,Vapnik 则认为支持向量机能方便地进行泛化控制。一个用“窄”核函数的支持向量机能很好地学习训练集,但它的泛化能力则要诉诸于核的宽度和对偶系数的稀疏度。Vapnik非常在意算法的误差界,因此他比较担忧神经网络乏善可陈的泛化控制方法(即使可以从VC维来解释其泛化界)。而我则认为,是否能进行有效的泛化在一定程度上并不是最重要的,实际应用中我们往往更在乎通过有限的运算可以更高效地计算更复杂的函数。例如,在像素层次上运用核函数进行具有平移、尺度、旋转、不同光照以及混乱背景不变性的图像识别几乎是不可能的。但是深度学习(比如卷积神经网络)则能很容易地处理这些问题。
以上是关于支持向量机的理论基础的主要内容,如果未能解决你的问题,请参考以下文章