集群服务消息队列Nova Cells...丨OpenStack的12个关键技术突破口
Posted OpenStack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集群服务消息队列Nova Cells...丨OpenStack的12个关键技术突破口相关的知识,希望对你有一定的参考价值。
奥斯汀OpenStack Summit网络技术主题的观影指南将对OpenStack网络架构、功能与工具、开发之外的一些重要演讲做出点评。这是的完结篇。OpenStack+在此感谢您的持续关注与支持。
1. Performance Measuring Tools for the Cloud
评分:★★★★
简介:几位演讲者带来的 OpenStack 上用的各类 Performance 度量工具的介绍,关键词是 Rally、Cloud Bench、Ceph Benchmark Tool、SPECcloud。
评论: Rally 基本不用介绍了,OpenStack 上最常用的性能测试工具,有意思的事最近提交了这一 Patch:https://review.openstack.org/#/c/115439,可以为 Rally 带来在 VM 里跑 linpack 和 dd (已有)来衡量虚拟机 CPU 和磁盘性能的数据,将 Rally 的测试从 API 层扩展到了虚拟机性能。缺点是只支持 OpenStack,无法衡量不同云的性能情况。
CloudBench 支持很多平台,可以在 libvirt、OpenStack、SoftLayer、EC2、CloudStack、VMWare、GCE 上跑,执行的测试也是 SPEC、Hadoop、linpack、netperf 等等这些标准化测试,便于比较云平台。
SPECcloud 类似于 CloudBench,但是其标准化的考虑很多,有几篇很详细的报告说明其为何跑哪些测试,能反映出什么指标等等。可以对控制平面和数据平面做测试,metric 有弹性、扩展性、供给时间等。Workload 有 YSCB(Cassandra)和 Kmeans(Hadoop),前者考察 IO,后者考察 CPU 和 MEM。
CBT 全称 Ceph Benchmark Tool,可以用来测试 Ceph 的性能。
Perfkit 本是 Google 的云性能检测工具,最近支持了 OpenStack,还可以支持 GCE、Azure、AWS、阿里云、DigitalOcean、Rackspace、Kubernetes、Mesos 等等,测试工具很全,详见其 Github。
演讲里还有一个是如何用 HAproxy 做性能的分析,主要是分析 HAproxy 的日志,也挺有意思的。
可惜的是没有人提 browbeat,这个项目其实也很有意思,也被 RedHat OpenStack 所使用。
2. Project Vitrage How to Organize, Analyze and Visualize your OpeenStack Cloud
评分:★★★★
简介:Vitrage 是一个 Nokia 开发的运维辅助项目,主要作用是集成 OpenStack 的监控工具做可视化和报警压缩。
评论: 开场是长达 4 分钟的酷炫动画,我差点以为这个演讲要全程动画了,还好后边及时换成了 PPT。运维有一个痛点是这样的,当你的云很大、监控项很多时,很可能发生一个故障引起一连串报警,你得在一连串报警中分析问题所在,很浪费时间而且撰写故障报告又得重新把所有报警理一遍确定却是所有故障已经处理完,还有发报警一般是要花钱的(比如短信和语音报警),一堆报警一起想起来很花钱……
举个例子,一个交换机 Down 导致几个宿主机网络连接挂掉,进而导致其上运行的虚拟机、分布式服务(例如Ceph)之类的服务都挂掉,这时你可收到很多很多报警例如交换机 Down 的报警,服务器网络 Down 的报警,VM 网络 Down 的报警、Ceph 的 osd down 的报警等等,然而真正有用的其实是第一个!能否压缩报警呢?再比如一个 Region 的 ISP 网关挂了,那我们各种报警是不是得收到手残?(所有交换机、服务器、虚拟机无法连接到公网,想象一下得多少报警)
Vitrage 通过一个 Yaml 格式的配置文件定义各种 Alram 的依赖关系,可以通过简单的逻辑运算符组合各种情况,最终达到如果符合我们预期的某些场景,那么只需要将根本原因的报警发出来就可以的目的。
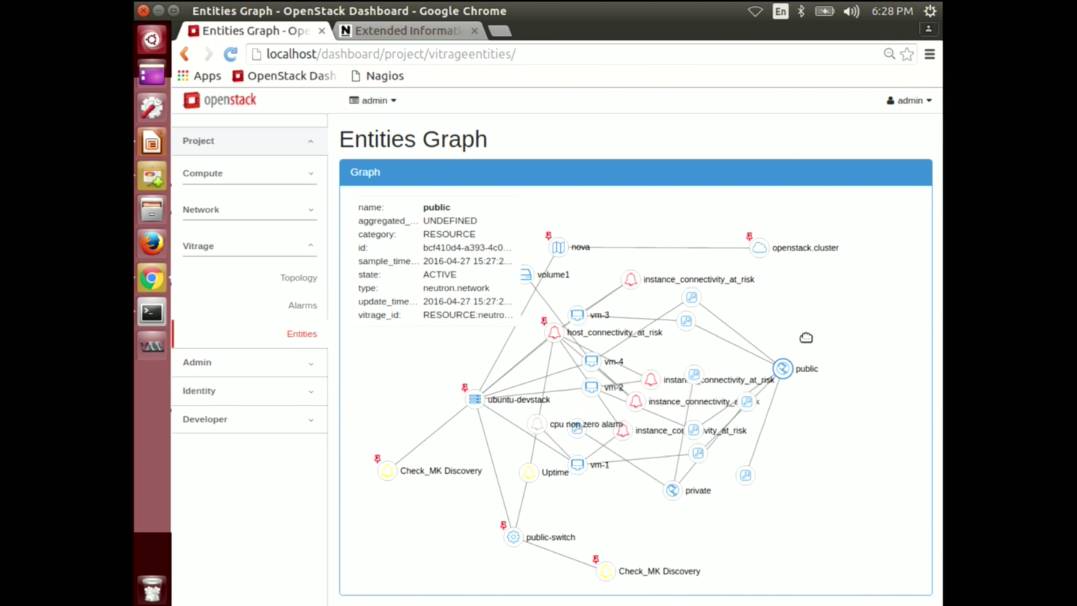
项目不错,而且开源还有 Demo,4 分的原因是 Demo 只有展示,没有现场定义个模版然后触发个报警这样的演示。
3. Intelligent Workload HA in Openstack
评分:★★★★
简介:一般来说,我们在 OpenStack 上做 HA 都是 Reactive 的,什么意思呢,就是出了事情去迁移 Workload,TATA 介绍了他们的基于 Proactive 算法的自己整合的一个 Workload 监控和迁移系统。
评论: 演讲先简单说明了现有系统的不足,例如 Ceilometer 没有网络冗余,pacemaker 只能使用管理网(笔者注:这是使用架构问题,pacemaker 可不背这个锅),Zookeeper 无法在很大的 Scale 下使用,Consul 需要很多的消息,nagios、sensu、zenoss 则是没有自动恢复的实现(笔者注:想立项要经费直说,为何立这么多敌……)。基本架构是这样的:
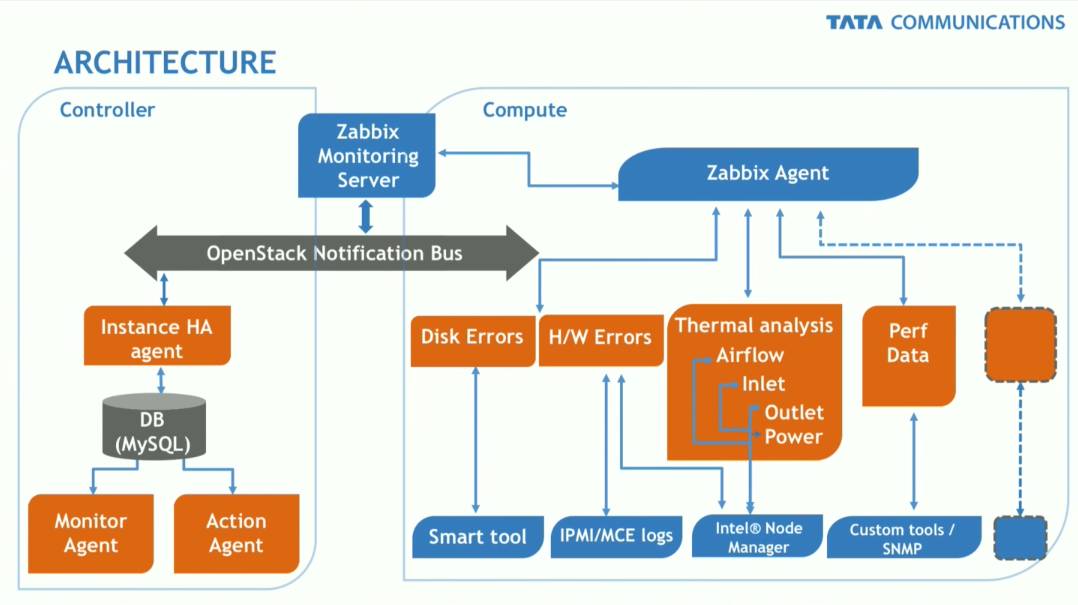
有意思的地方是继承了 IPMI 工具和 Intel Node Manager 等等。然后有了监测指标,我们就可以定义动作了:
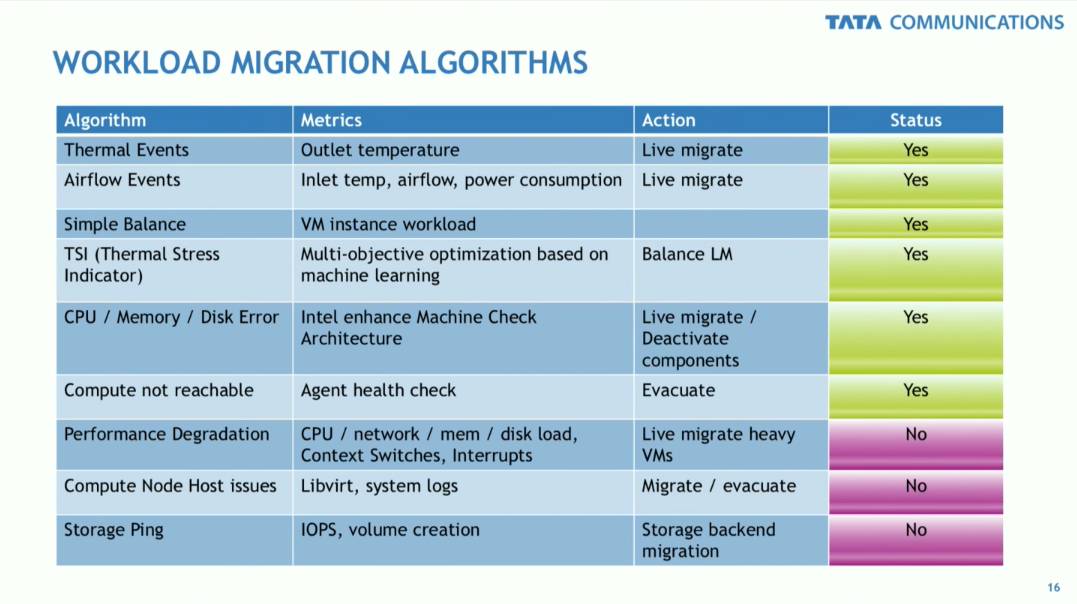
例如,如果因为某些虚拟机的 Workload 造成整个宿主机的负载问题做主动迁移、根据宿主机负载做 VM 的负载均衡等等,确实对一些用户有需求。
最后的 Demo 展示了因为虚拟机多而导致宿主机的 CPU 温度升高然后被自动调度到其他宿主机的例子,挺有意思的。智能化的 Workload 平衡、主动化的 HA 是否重要呢?见仁见智,4 分。
4. Senlin Clustering Service Deep Dive
评分:★★★☆
简介:由 IBM 三名中国同事出品的 Senlin 的介绍,重点介绍了 Senlin 项目的意义和架构,其次是本 Cycle 的一些 Feature、计划的 Feature 等。
评论: 很多时间依然在科普上,说明还是任重道远啊。替启明做一些普及工作吧,首先为什么要有 Senlin 这个项目?主要是 Heat 的设计是基于 AWS 的,不够通用,目前我们认为 Heat 的作用更多的在于基于模版的资源管理,它的重点不在与 AutoScaling、HA,而是作为一个引擎来帮其他服务或者开发者做资源管理的工作。
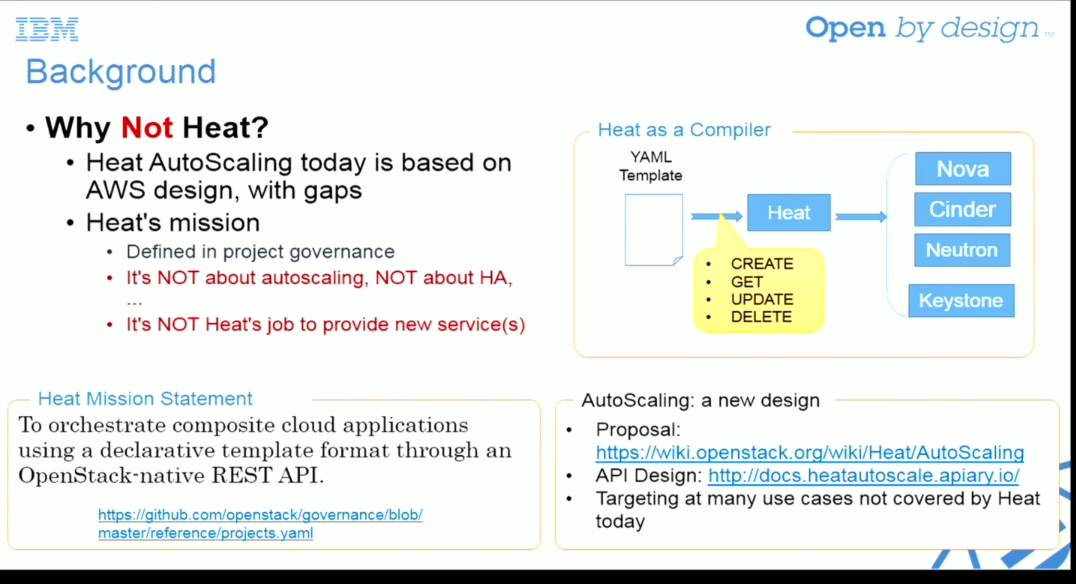
而 Senlin 的架构完全是为 HA 和 AutoScaling 设计的,甚至可以不用在 OpenStack 上,和其他 CMS 整合。例如有 receiver 模块可以直接集成各种 webhook、message,而不只是 Ceilometer 的消息;比如 policy 可以有替换、删除、扩展、负载均衡、健康、亲和性等,而不只是 low-level 的 CRUD 这些语义;比如 profiles 模块可以是 Heat 的 stack,也可以是 Nova 的 server,后面可以再接 openstacksdk,这样你可以为不同的云后面接 API(比如都是 OpenStack 版本也可能不同呢)或者做跨云的资源管理,因为这个架构的灵活性都是可能的。
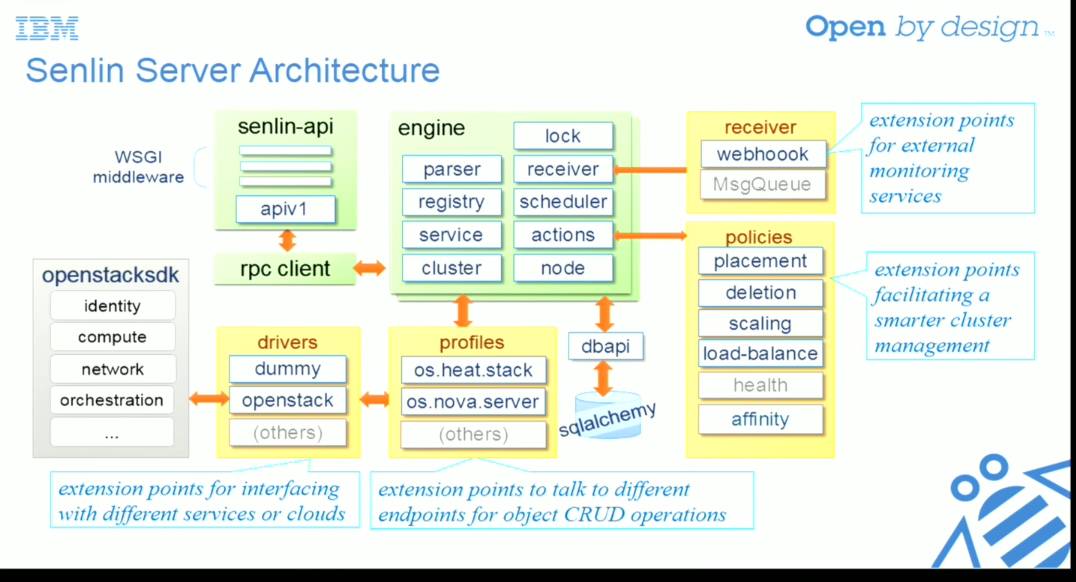
大概就是这样,祝这个第一个由国人发起、拼音命名的 OpenStack TC 项目健康发展!
5. Deploy an Elastic, Resilient, Load-Balanced Cluster in 5 Minutes
评分:★★★★☆
简介:通过 Senlin 项目在 OpenStack 上搭建一个弹性、自动伸缩的集群。
评论: 同样是介绍 Senlin,但是这个介绍更加实战,首先对 Senlin 能做 Heat 不能做的 Case 作了具体的说明:

然后启明的介绍和上一篇是类似的,最后做了一个 Demo 可以看到模版如何撰写,Profile 是什么样的等等。
如果关于 Senlin 的 presentation 中你只能看一个,而且你对 Senlin 没什么直接印象,那一定是看下面这个。
6. OpenStack Stable
评分:★★★★
简介:稳定版是一个 OpenStack Provider 们很关心的问题,这个 Presentation 介绍了什么是稳定版,如何制作,如何保持稳定版的新鲜,目前的困难和下一步计划,对提供 OpenStack 的供应商来说还是值得一看的。
评论: 不对外提供 OpenStack 的人很难理解其中的苦衷,但是每个为企业提供服务的 OpenStack 厂商都深受其苦,原因不乏 OpenStack 官方更新过快、OpenStack 目前 Bug 修复没有很严格的评定标准和 backport 标准,这对维护包的 maintainer 来说简直是一个灾难。
演讲最后介绍了目前开发的一些脚本和工具等来更加自动化未来的稳定版维护,hope it works.
7. Automated Security Hardening with OpenStack-Ansible
评分:★★★★
简介:如何提供一个安全的 OpenStack 云?目前一些 OpenStack 供应商可能需要雇佣专业的安全公司来保障其部署架构和部署结果是安全的,Rackspace 的架构师介绍了 Openstack Ansible Security 这个项目。
评论: 其实这个世界上安全工具和守则已经挺多了,关键是你的意识是否到位。例如有现成的 Security Technical Implementation Guide(STIG)项目,那么你是否按照要求做了配置和打了补丁?相信很多公司都没做到。

那怎么办?专门雇一个人每天看 STIG 文档检查所有机器的配置吗?显然不现实,我们可以用 Ansible 来做这件事情。那就是 openstack-ansible-security,它会帮你自动检查和配置 STIG 上的安全建议,帮助你达到 PIC-DSS 的标准。

值得一说的是 OpenStack 还有 syntribos(Web 安全测试)、bandit(代码安全检查)、OSSA(安全建议)等等项目,一直在提升 OpenStack 的安全性。4 分的原因是明明 10 分钟能说清楚的事情硬说了 32 分钟,而且目前不支持 CentOS7,否则应该是 4.5 分。
8. Open Stack at Carrier Scale
评分:★★★
简介:介绍了 AT&T 总结的运营商云和传统私有云的架构、设计等等上面的区别。
评论: 前面介绍了 AT&T 的规模很大:

然后介绍了运营商区别的种种特别之处:

着重说明了网络层面的不同需求:

可惜如何解决这些 challenge 说的比较简单,也可能是笔者不做运营商 get 不到其中的 point。总之对了解运营商云还是有一定帮助的。
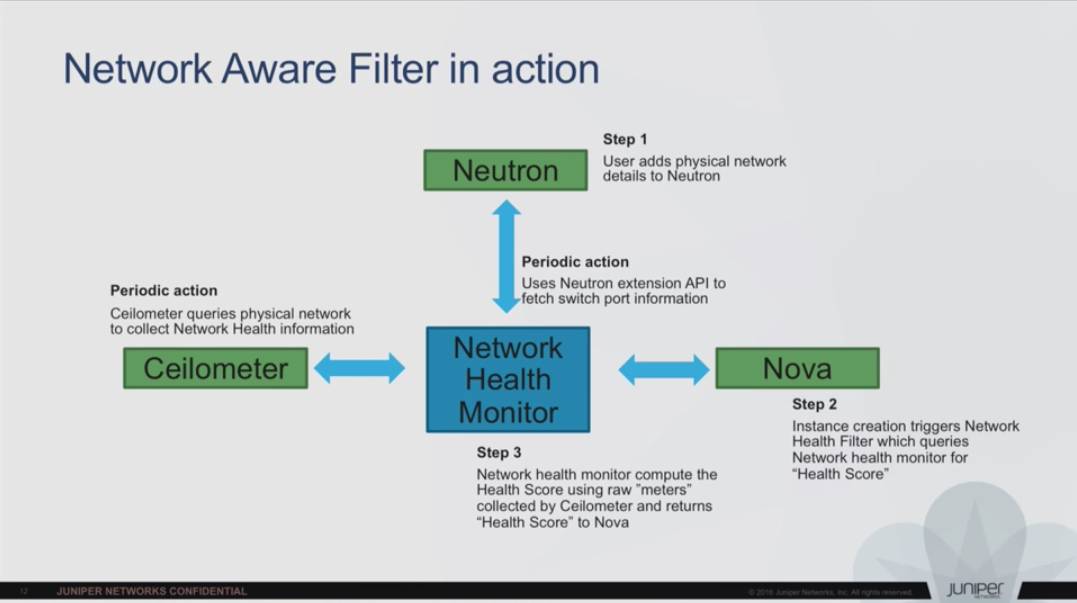
9. Ceilometer, Nova and Neutron - Working Together to Provide a Healthy Network for Your Cloud
评分:★★★
简介:如何用 Ceilometer 辅助打造一个更健康的云网络。
评论: 笔者看完表示被老印的奇思妙想深深的伤害了…… 他们为什么这么喜欢在调度上做文章,类似于前边的 Intelligent Workload HA in Openstack,你可以通过监控工具把交换机上端口状态、带宽等等数据取出来,发到 Network Health Monitor 里边,计算出一个 Health Score 放到 Nova 的 Schedular 里,实现调度层面的网络负载均衡。
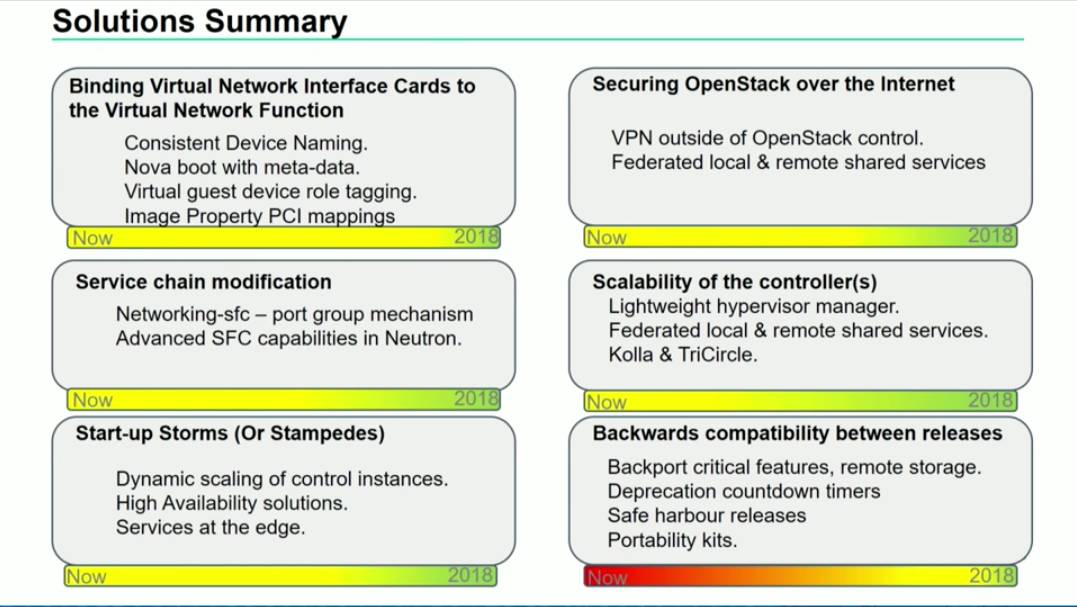
10. Distributed NFV & OpenStack Challenges and Potential Solutions
评分:★★★☆
简介:使用 OpenStack 搭建 NFV 网络所遇到的挑战与一些解决方案。
评论: 主要的挑战是这些:
一、启动虚拟机时需要保证虚拟网卡的名字和顺序的一致性;
二、Service Chain 的修改;
这个需要 networking-sfc v2 对 nsh 的支持。
三、数据安全性
目前主要靠 VPN 解决,希望将来能有设计上更加安全的架构来解决。
四、OpenStack Controller 的 Scalability
主要是运营商的 Scalability 往往比较大而且分布很广,那么控制面怎么设计就会很麻烦,短期的解决方案是边缘(Edge)区域不设置控制平面,或者直接用 libvirt 来控制,远期思路是有一个轻量级的控制平面。类似于华为之前提的 TriCircle 之类的。
五、启动风暴
很好理解,主要是大量虚拟机启动时会对控制平面和网络形成一个冲击,解决思路主要是网络上尽量本地响应,控制平面也尽量能扩展到边缘,就像上面说的那个问题。
六、OpenStack 的向下兼容
OpenStack 的更新很快,可能导致出现很多版本不一致的 OpenStack,而且由于 VNF 的兼容性问题还不能轻易升级,解决方案是 back-port,社区提供长期支持版本等等。
讲的也挺好的,可惜笔者确实没什么运营商经验,所以难以评判。
11. Nova Cells V2 What s Going On?
评分:★★★★
简介:Nova Cells 是 Nova 社区提供的一种增强 Nova 的 Scalability 的手段,从 Nova Cells v1 开始已经被成功应用到一些部署环境中,本场 Presenatation 将介绍 Cells v2 的设计初衷、架构和目前的实现。
评论: Nova Cells v1 其实不错,可以有效解决数据库和消息队列的扩展性问题,但是两级调度的设计里,上一级调度往往缺乏细粒度的信息,而且消息队列的使用是基于 Relay 的,代码存在 Race Condition,缺乏一些 Feature 等等。这导致目前实际上 Nova Cells 的部署案例很少、熟悉的开发者也很少、从无 Cell 架构升级也很困难。
社区从老版的 Cells 的设计也学到很多,包括不要重复数据、应该尽量进入默认选项还有 Parent Cell 这个设计导致 Parent Cell 的 Scale 并不好。
下面就要说 Nova Cells v2 的设计了,新的 nova_api 数据库将全局性的数据保存在一个地方、Nova cells 将成为默认的部署方式、全局信息尽量得少。
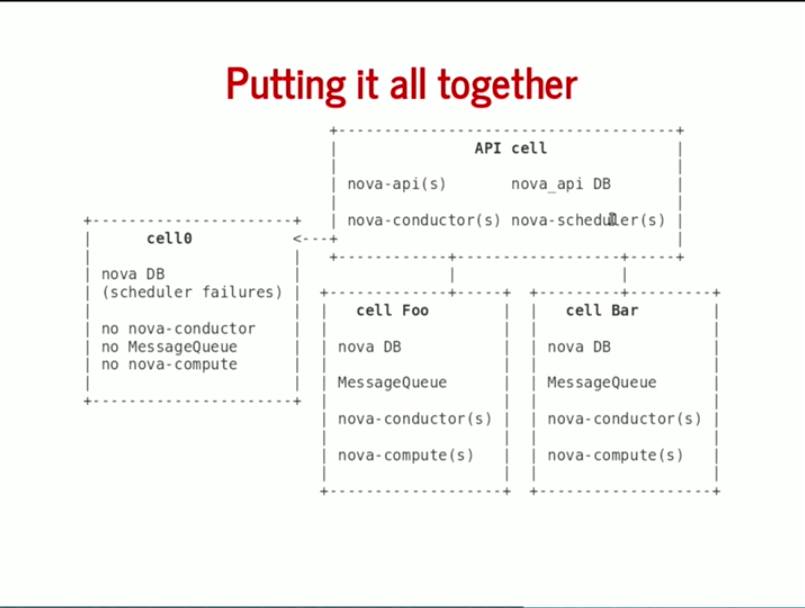
其中 API Cell 运行 API 服务和 API DB,一个 cell0 用来保存 Fail 的主机,其他的 Cell 运行自己的 DB、MQ、Conductor 和 Compute 服务。与 v1 的重要区别是没有了 nova-cell 这个服务,树型架构被舍弃了,cell 内不在保留 scheduler。不过现在还在开发,所以这个架构设计也不是最终结果。
讲的很平淡,但是 Nova Cells v2 是个对大规模部署很重要的事情,所以建议一看。
12. Troubleshooting oslo.messaging RabbitMQ issues
评分:★★★★
简介:RabbitMQ 是 OpenStack 里最受诟病的组件之一,在找到更好的解决方案之前,你先要能 Debug 问题所在。
评论: 先介绍了 oslo.messaging 和 OpenStack 中 RPC 的使用场景。演讲者先提到了最有意思的报错是 MessagingTimeout: time out waiting for a reply to message ID xxxx 这个,却是,这是我们最常见的报错之一…… 这个报错是怎么怎么来的呢,首先三个 RPC 场景——Cast、Notify、Call 三个场景只有 Call 会出这个问题,因为 Call 需要返回值(客户端),那么 MQ 没有成功把消息发给服务端、或者服务端没有正确处理、或者服务端没有将返回发给 MQ、或者 MQ 没有正确把消息发给 Client,都可能会报这个错!
第一个 Tip 是打开 oslo.messageing 的 debug 日志,第二个是看服务的日志。还有在 MQ 上看 Queue 的消费者情况,是不是消费者挂了?或者集群分区了?一般来说,重启相关服务或者强制关闭连接是比较靠谱的……
有一些建议是不要打开 amqp_auto_delete,最好不要打开 Queue mirroring,如果你实在需要消息高可用(比如涉及支付系统),那么可以考虑只对 notification 开,RPC 是不需要的。
此外还有跟 RabbitMQ 本身的一些 debug 建议,比如内存使用、DB 状态、文件描述符、TCP 连接 backlog 大小等等。
说一些笔者想说的重点,https://review.openstack.org/#/c/249508 这个 Patch 还是很重要的,可以把 Notification 和 RPC 用的 MQ 分开,如果你看过 Performance Analysis in Large-scale Deployment - A Single Thousand nodes Cluster 或者 Tuning RabbitMQ at Large Scale Cloud 这两个 Presentation,你会看到他们的设计也没有特别标新立异的地方,关键还是把热点分离。
以上是关于集群服务消息队列Nova Cells...丨OpenStack的12个关键技术突破口的主要内容,如果未能解决你的问题,请参考以下文章