OpenStack——Nova组件
Posted 小白的成功进阶之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenStack——Nova组件相关的知识,希望对你有一定的参考价值。
OpenStack(四)——Nova组件
一、Nova计算服务
- 计算服务是openstack最核心的服务之一,负责维护和管理云环境的计算资源,它在openstack项目中代号是nova。
- Nova自身并没有提供任何虚拟化能力,它提供计算服务,使用不同的虚拟化驱动来与底层支持的Hypervisor(虚拟机管理器)进行交互。所有的计算实例(虚拟服务器)由Nova进行生命周期的调度管理(启动、挂起、停止、删除等)
- Nova需要keystone、glance、neutron、cinder和swift等其他服务的支持,能与这些服务集成,实现如加密磁盘、裸金属计算实例等。
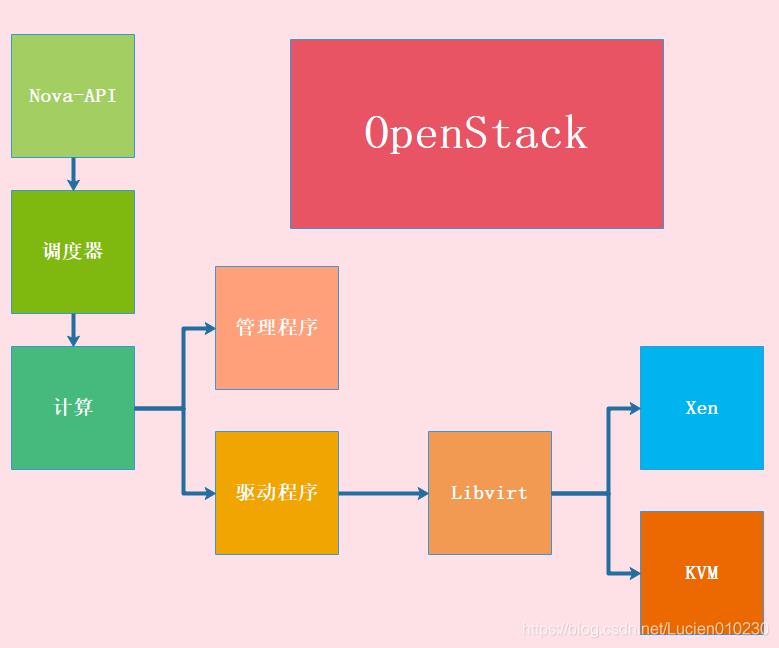
二、Nova的架构
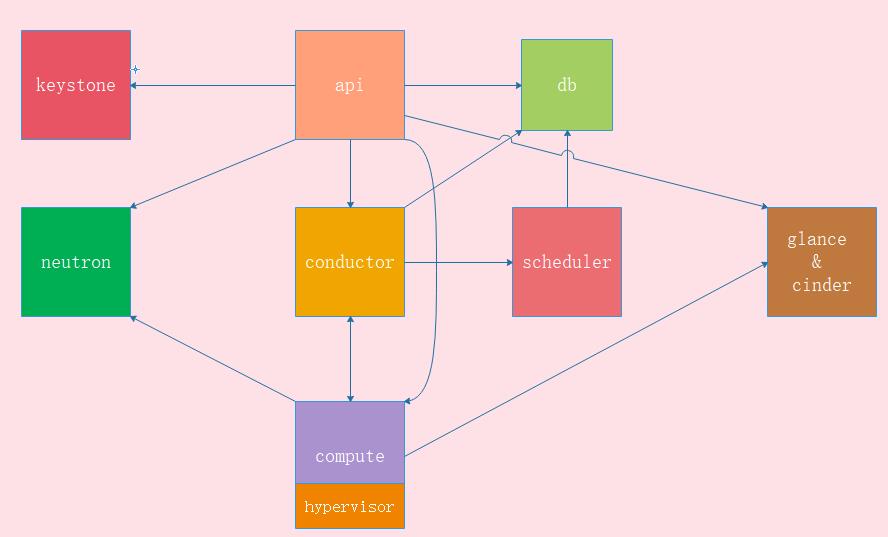
- DB:用于数据存储的sql数据库
- API:用于接收HTTP请求、转换命令、通过消息队列或HTTP与其他组件通信的nova组件
- Scheduler:用于决定哪台计算节点承载计算实例的nova调度器
- Network:管理IP转发、网桥或虚拟局域网的nova网络组件
- Compute:管理虚拟机管理器与虚拟机支架你通信的nova计算组件
- Conductor:处理需要协调(构建虚拟机或调整虚拟机大小)的请求,或处理对象转换
三、Nova组件介绍
1、API
- API是客户访问nova的http接口,它由nova-api服务实现,nova-api服务接收和响应来自最终用户的计算api请求。作为openstack对外服务的最主要接口,nova-api提供了一个集中的可以查询所有api的端点。
- 所有对nova的请求都首先由nova-api处理。API提供REST标准调用服务,便于与第三方系统集成。
- 最终用户不会直接改送RESTful API请求,而是通过openstack命令行、dashbord和其他需要跟nova交换的组件来使用这些API。
- 只要跟虚拟机生命周期相关的操作,nova-api都可以响应
- Nova-api对接收到的HTTP API请求做以下处理:
- 检查客户端传入的参数是否合法有效
- 调用nova其他服务来处理客户端HTTP请求
- 格式化nova其他子服务返回结果并返回给客户端
- Nova-api是外部访问并使用nova提供的各种服务的唯一途径,也是客户端和nova之间的中间层
2、Scheduler
- Scheduler可译为调度器,由nova-scheduler服务实现,主要解决的是如何选择在哪个计算节点上启动实例的问题。它可以应用多种规则,如果考虑内存用率、cpu负载率、cpu构架(intel/amd)等多种因素,根据一定的算法,确定虚拟机实例能够运行在哪一台计算服务器上。Nova-scheduler服务会从队列中接收一个虚拟机实例的请求,通过读取数据库的内容,从可用资源池中选择最合适的计算节点来创建的虚拟机实例。
- 创建虚拟机实例时,用户会提出资源需求,如cpu、内存、磁盘各需要多少。Openstack将这些需求定义在实例类型中,用户只需指定使用哪个实例类型就可以了
①、Nova调度器类型
- 随机调度器(chance scheduler):从所有正常运行nova-compute服务的节点中随机选择。
- 过滤器调度器(filter scheduler):根据指定的过滤条件以及权重选择最佳的计算节点。Filter又称为筛选器
- 缓存调度器(caching scheduler):可看作随机调度器的一种特殊类型,在随机调度的基础上将主机资源信息缓存在本地内存中,然后通过后台的定时任务定时从数据库中获取最新的主机资源信息。
②、调度器调度过程
- 【1】通过指定的过滤器选择满足条件的计算节点,比如内存使用率小于50%,可以使用多个过滤器依次进行过滤。
- 【2】对过滤之后的主机列表进行权重计算并排序,选择最他的计算节点来创建虚拟机实例。
3、Compute
①、主要功能
- Nova-compute在计算节点上运行,负责管理节点上的实例。通常一个主机运行一个Nova-compute服务,一个实例部署在哪个可用的主机上取决于调度算法。OpenStack对实例的操作,最后都是提交给Nova-compute来完成。
- Nova-compute可分为两类,一类是定向openstack报告计算节点的状态,另一类是实现实例生命周期的管理。
简单来说:
1、负责执行具体的与实例生命周期/管理实例相关的工作
2、报告节点状态(写入数据库,保证scheduler读取数据库,数据库信息的实时性、celimetor,监控和管理openstack实例资源并汇入给用户/openstack本身/运维人员)
②、工作过程
- 定期向OpenStack报告计算节点的状态
- 每隔一段时间,nova-compute就会报告当前计算节点的资源使用情况和nova-compute服务状态。
- nova-compute是通过Hypervisor的驱动获取这些信息的。
- 实现虚拟机实例生命周期的管理
- OpenStack对虚拟机实例最主要的操作都是通过nova-compute实现的。
- 创建、关闭、重启、挂起、恢复、中止、调整大小、迁移、快照
- 以实例创建为例来说明nova-compute的实现过程。
- 为实例准备资源
- 创建实例的镜像文件
- 创建实例的XML定义文件
- 创建虚拟网络并启动实例
4、Conductor
- 由nova-conductor模块实现,旨在为数据库的访问提供一层安全保障。Nova-conductor作为nova-compute服务与数据库之间交互的中介,避免了直接访问由nova-compute服务创建对接数据库。
- Nova-compute访问数据库的全部操作都改到novaconductor中,nova-conductor作为对数据库操作的一个代理,而且nova-conductor是部署在控制节点上的。
- Nova-conductor有助于提高数据库的访问性能,nova-compute可以创建多个线程使用远程过程调用(RPC)访问nova-conductor。
- 在一个大规模的openstack部署环境里,管理员可以通过增加nova-conductor的数量来应付日益增长的计算节点对数据库的访问量
5、PlacementAPI
- 以前对资源的管理全部由计算节点承担,在统计资源使用情况时,只是简单的将所有计算节点的资源情况累加起来,但是系统中还存在外部资源,这些资源由外部系统提供。如ceph、nfs等提供的存储资源等。面对多种多样的资源提供者,管理员需要统一的、简单的管理接口来统计系统中资源使用情况,这个接口就是PlacementAPI。
- PlacementAPl由nova-placement-api服务来实现,旨在追踪记录资源提供者的目录和资源使用情况。
- 被消费的资源类型是按类进行跟踪的。如计算节点类、共享存储池类、IP地址类等。
四、Nova的Cell架构
- 当openstack nova集群的规模变大时,数据库和消息队列服务就会出现瓶颈问题。Nova为提高水平扩展及分布式、大规模的部署能力,同时又不增加数据库和消息中间件的复杂度,引入了Cell概念。
- Cell可译为单元。为支持更大规模的部署,openstack较大的nova集群分成小的单元,每个单元都有自己的消息队列和数据库,可以解决规模增大时引起的瓶颈问题。在Cell中,Keystone、Neutron、Cinder、Glance等资源是共享的。
- API节点上的数据库
- nova_api数据库中存放全局信息,这些全局数据表是从nova库迁过来的,如flavor (实例模型) 、 instance groups (实例组)、quota (配额)
- nova_cello数据库的模式与nova一样,主要用途就是当实例调度失败时,实例的信息不属于任何一个Cell,因而存放到nova_cell0数据库中。
1、单cell架构
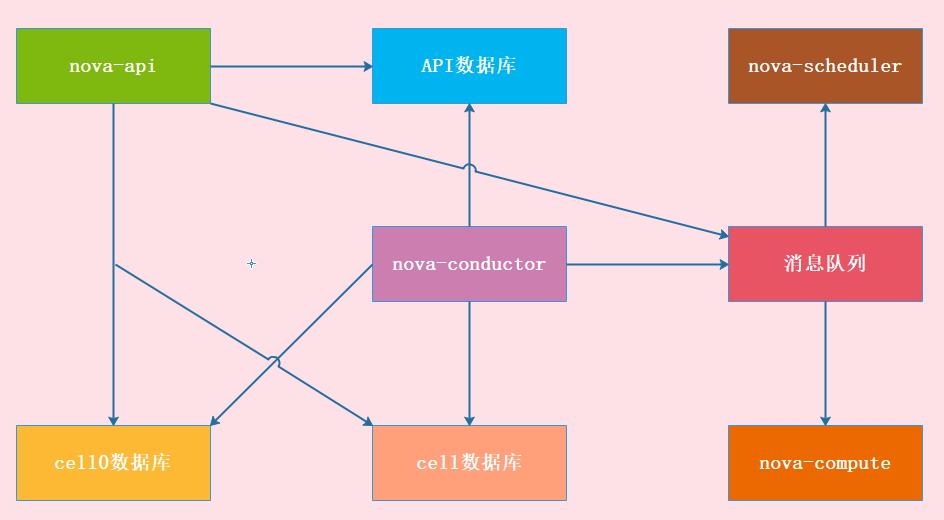
举例:创建虚拟机
- Nova-api 接收、响应请求
- 交给conductor处理/协调
- conductor——》scheduler调度器——》最适合创建虚拟机的节点
- 如果scheduler调度失败
- 将调度失败的信息,存放在cell0中
- nova-api会读取cell0数据库,获取到失败的信息/原因,返回给客户端
- 如果scheduler调度成功
- conductor就会将这个任务交给cell1处理(rabbitmq-cell接收、响应)
- rabbitmq-cell——》conductor-cell——》交给节点上的compute进行具体创建——》compute汇报给cell1数据库——》响应给conductor-cell——》rabbitmq-cell——》nova的conductor
- nova-conductor接收到cell的返回之后,保存在api数据库中(保存实例创建成功的信息)
- nova-api组件,会读取api数据库,返回/响应给客户端
以上是关于OpenStack——Nova组件的主要内容,如果未能解决你的问题,请参考以下文章