消息队列之 Kafka
Posted 架构文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息队列之 Kafka相关的知识,希望对你有一定的参考价值。
Kafka 是 LinkedIn 公司的一款开源 MQ。在没有 Kafka 之前,大部分的业务与业务之间都是通过端对端的连接,错综复杂。
试想用一种极为简单的 Pipeline 将这些数据进行一次 Aggregate。
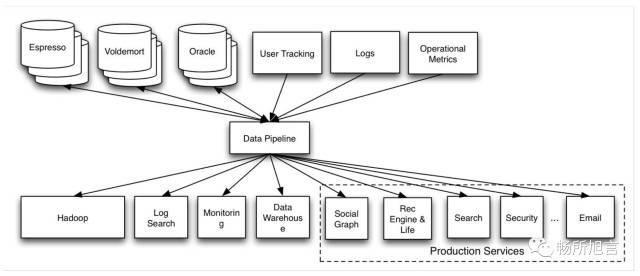
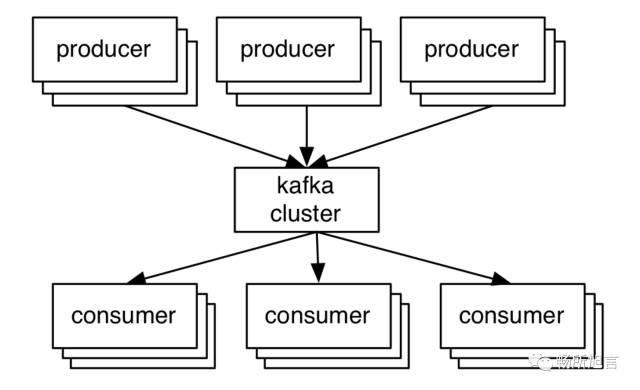
将上面产生数据的作为生产者,下面对数据处理的作为消费者,就自然而然的形成了消费者和生产者,中间的 Pipeline 就是一个消息队列。
Kafka 在数据库的 Replicate 场景
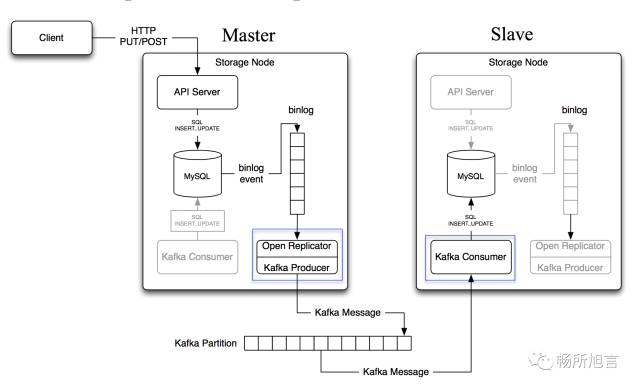
在此构架上面,主要需要保证如下几个方面:
message integrity:
no message loss
in order delivery
exactly once
message schema
message schema registry
message seri/desr
perfomance:
high throughput
low latency
handle large message
message integrity guarantees
producer :
bathing the message
send message async
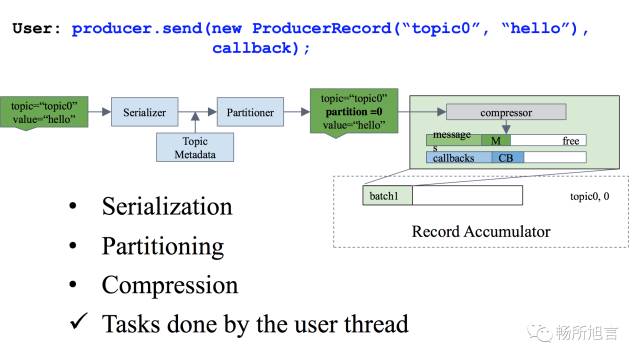
在 Sender Thread 中,从 Record Accumulator 里面的 Message Buffer Poll Message 发送到 Broker
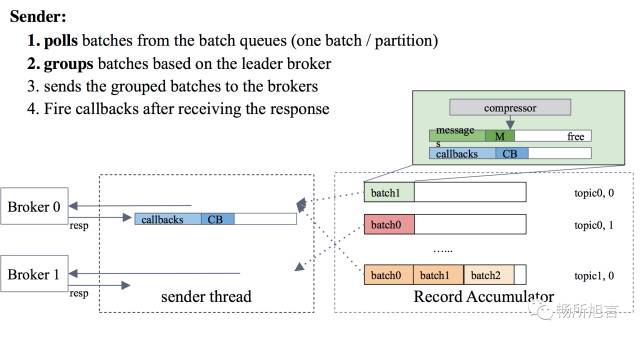
为了 Fail Over,需要将数据进行 Replicate,将所有在 ISR 中的 Broker 都回应 Ack,再返回
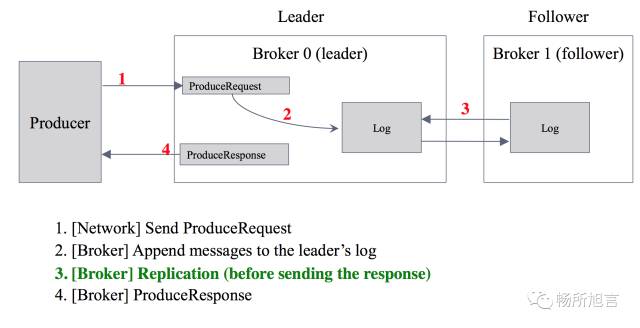
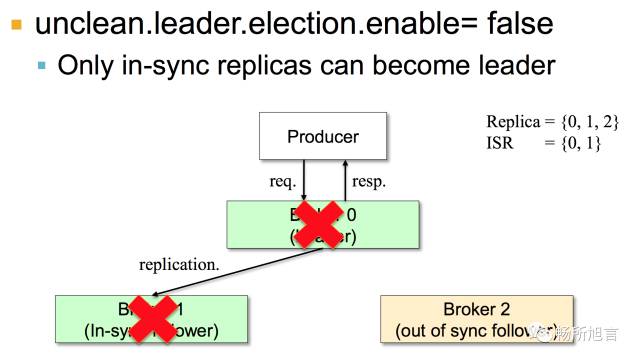
ISR 在 Producer 中,将 Ack 设置为 0,那么不行的 Replicate 就可以返回,这点类似于 UDP 协议。如果设置为 1,即使将 Leader Commit,也可以返回 Ack。但是如果 Leader 在没有 Replicate 之前宕机,那么该条消息就会丢失,最后设置为 -1,消息是不会丢失,但是对于之前的延迟是加强。

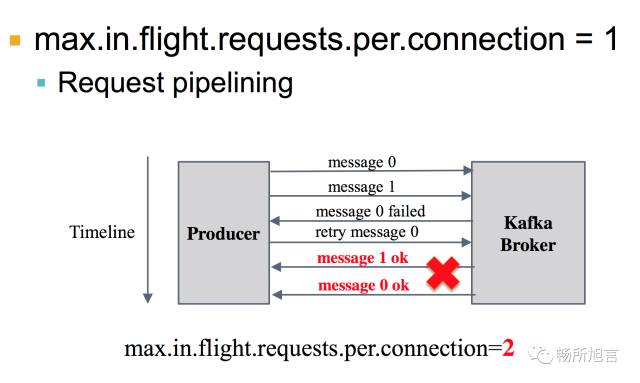
为了保证 In Order Delivery 需要将 max.in.flight.requests.per.connection = 1。因为当消息为 0,发送到 Broker 过后,由于种种原因 Broker 没有接受成功,就需要 Retry,然而如果此时此刻消息 1 已经成功 Send 到 Broker,就导致原本应该先看 Message0 结果变成了 Message1。
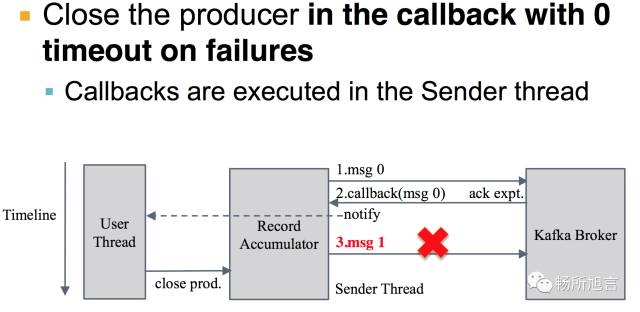
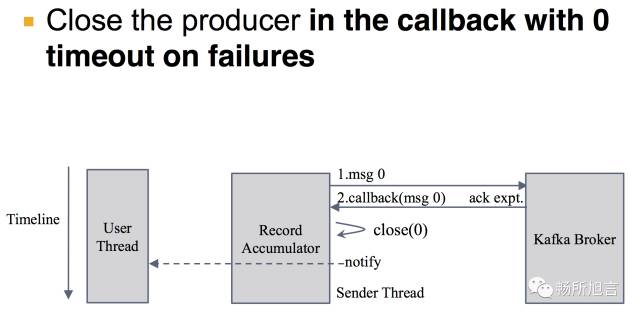
以及还需要在 Producer 的 Callback 之中将 Timeout 设为 0,将其 close 掉。
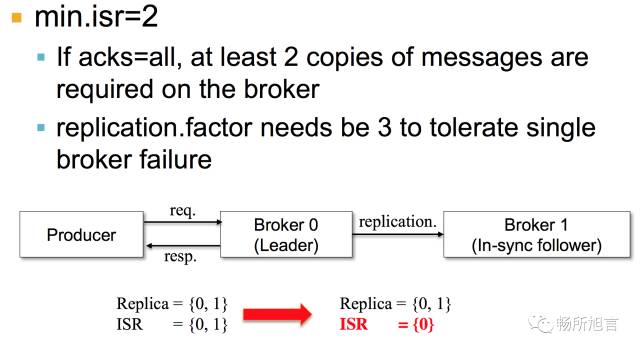
为了数据存在多份,需要将 min.isr = 2。将 ISR 至少保证两个 Broker,在这两个 Broker 里面保存最新的成功提交消息。
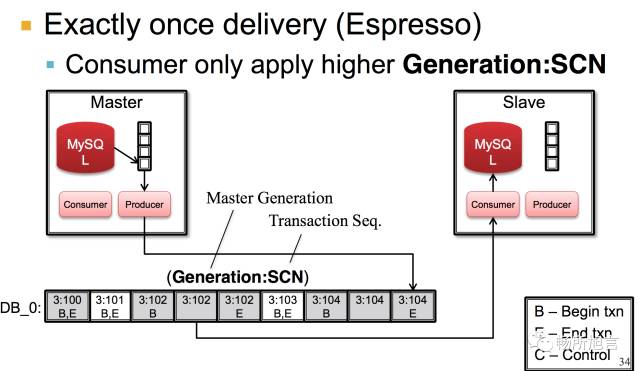
Exactly Once Delivery 在 Consumer 端进行处理,因为它是一个 Distribution Data System。同时也会有一个 Election,所以才会有一个全局递增的 Epoch。以及根据业务的一个 Transition Sequence Number,所以这两个都是全局唯一的,当 Consumer Poll 对比自己最后一条消息的 ETS,小的数据就直接扔掉。
Performance — Ack All 里面会 Increase Latency
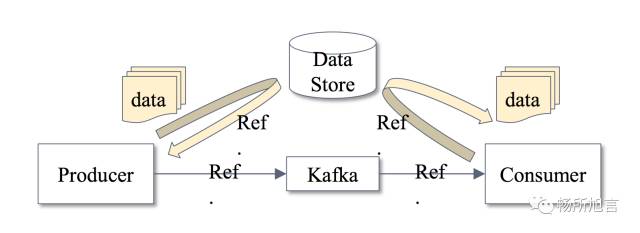
由于需要依赖外部存储,所以不是那么方便。最后在 Producer 和 Consumer 做了 Split 和 Assembly。
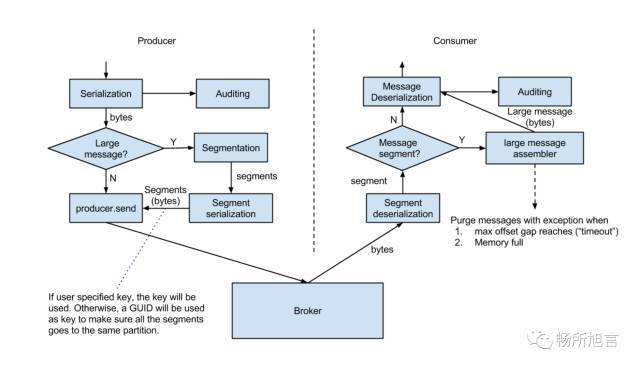
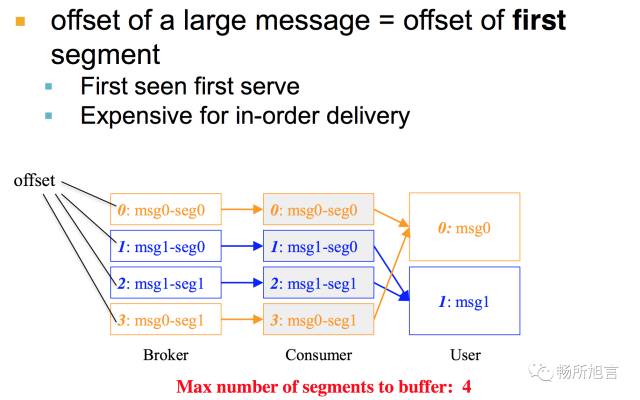
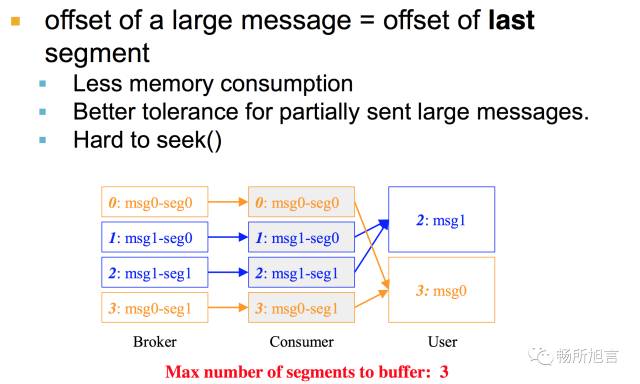
在 Consumer 进行 Assembly 过程中要保证 In Order Delivery,需要对 Message 进行 Buffer,在进行存储的过程中可以分为两种,一种去 Offset 的头,一种去 Offset 的尾部。
每个人需对消息格式有一个固定的标准,而不是每人自定消息格式。如果这样的话,发出去的消息其他人没办法使用。我们要求所有经过 Kafka 的消息都必须用固定的 Format,加入一个集中式的 Schema 管理部件,每次发送消息的时候,它做的过程就是把我们的消息通过 Schema 序列化成 Var Bytes,我们不会把 Schema 随消息一起发出去,它做的事情是把 Schema 注册到 Schema Registry 拿到一个 Schema ID,把这个 ID 随着消息一起发送到 Kafka,当 Consumer 拿到这个消息的时候,会先去看 Schema ID,然后到 Schema Registry 把 Schema 拿回来,就可以把这个消息反序列化出来。在整个过程当中,最主要的好处是消息的 OverHead 比较小,这是一个最基本的数据的收发过程和数据的格式标准。
以上是这次 LinkedIn 的分享学习。
出处:
https://mp.weixin.qq.com/s/uSGmlk2OzryWfHv_enbwCw
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习
更多精彩文章,请点击下方:阅读原文
以上是关于消息队列之 Kafka的主要内容,如果未能解决你的问题,请参考以下文章