全球最大金融级分布式MySQL集群实践:5个9可用性20万TPS快乐运维
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全球最大金融级分布式MySQL集群实践:5个9可用性20万TPS快乐运维相关的知识,希望对你有一定的参考价值。
作者丨姜承尧
腾讯金融科技是腾讯集团旗下为用户提供互联网支付与金融服务的综合平台。其前身始于 2005 年成立的财付通,2015 年 9 月正式升级为 FiT(Financial Technology)。用户所熟知的微信支付、QQ 钱包、理财通、微证券、香港钱包等业务,后台都由 FiT 的数据平台系统支撑。这其中不仅存储着交易类信息数据,还包括极其重要的用户资金数据。
对于金融业务来说,数据安全与可靠性是重中之重,因此传统银行使用 Oracle RAC 架构打造自己的数据库平台。随着移动互联网的普及,支付活动变得更为高频,比如商户的扫码支付,用户间的微信红包和转账。对于 FiT 团队来说,除了数据的安全和可靠之外,还需要面对海量用户的支付请求挑战。因此我们遇到的主要挑战为:
金融级数据一致性要求:由于需要存储大量用户资金数据,要求金融级高可用容灾能力,为用户资金保驾护航;
海量存储需求:在移动互联网时代,交易量大幅提升,需要能安全可靠存储海量数据的能力;
用户体验要求:在每秒百万级支付场景下,要求数据库能提供平滑的响应时间,例如 FiT 的事务响应耗时要求尽可能控制在 20ms 内。
从早期的财付通起,FiT 就将开源关系型 MySQL 作为后台存储数据库。MySQL 数据库提供的完整 ACID 事务特性支持,海量并发查询的 MVCC 特性,以及灵活的复制拓扑架构与性能,这些特性都非常符合 FiT 海量支付的金融场景应用。
Oracle 数据库虽然在传统金融领域使用较为广泛,但 License 费用和硬件投入成本较高,并且其集中式的架构也越来越不符合当前海量移动支付金融的场景要求。其他开源关系型数据库在稳定性、可靠性、性能方面也不符合 FiT 的生产需要。
近年出现的分布式 NoSQL 数据库,提供了在线扩缩的能力与灵活性。但在实际应用场景下,大多数 NoSQL 数据库并不支持事务特性,这在金融场景下是难以接收的。其次,从长期来看由于没有提供标准的 SQL 接口,导致开发的学习成本和后期运维成本也将直线上升。
分布式 NoSQL 数据库提供的自动在线扩缩容能力,根据我们的实际经验来看,在真实生产场景下,对于在线业务的响应耗时要求也是难以接受的,最后依然退化为 DBA 手工扩缩容。
FiT 使用 Oracle MySQL 社区版打造全球最大的支付与金融数据库集群,MySQL 5.7 版本已能完整支持金融场景的业务需求。无损复制(lossless replication)提供了完美的金融级数据可靠性保障,并行复制功能则解决了困扰 MySQL 多年的主从数据延迟问题,而通过官方不断地优化,5.7 版本较之之前版本又有了较大的性能提升。总之,社区版 Oracle MySQL 版本已能较为完美地支持金融级支付业务。
为了满足微信海量金融支付场景的需求,FiT 采用了分布式 MySQL 数据库架构,将数据打散至数千台数据库实例。对于核心用户资金类数据,设计将其分布存储在数千个分片(Shard)。
在金融场景下,数据一致性要求非常之高,数据库团队不仅要考虑服务器宕机,还要考虑机房宕机,城市宕机的容灾场景,确保在任何场景下数据都不存在丢失风险。例如机房光钎挖断,多个机房光钎挖断,甚至是一个城市成为孤岛的场景。为了应对上述的容灾挑战,FiT 内部的金融级 MySQL 集群数据库支持三中心的同 / 近城容灾,三地五中心的跨城容灾架构,任何一个分片的数据都实时同步到多个机房,当机房宕机时,通过 Raft 分布式共识机制选出新的主机,继续提供数据服务。更重要的是,FiT 的 MySQL 节点可以实现自动地跨机房、跨城切换,确保数据没有丢失风险。同时,数据库集群拥有自愈能力,即宕机的数据库节点恢复后,能自动恢复并加入到原集群,无需任何人工介入,大大提升 DBA 的运维效率。
传统金融行业使用两地三中心的架构,在这种架构下,生产数据中心提供服务,当发生故障时同城灾备中心可接管,其中生产数据中心与同城灾备中心距离不超过 100KM。通常异地灾备中心是一个异步机制,无法真正接管并提供服务。
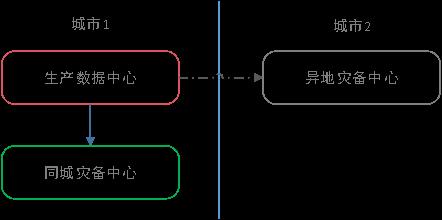
两地三中心架构
传统两地三中心的架构最大的缺点是当发生网络抖动时,由于生产数据中心与同城灾备中心采用强同步模式,这时会导致整个数据库服务的不可用。此外,在两地三中心架构下,每个机房的角色是不一样的,主 -> 同城备 -> 异地备,只有主才能提供服务,绝大部分时候,另外两个机房都处于 Standby 状态,资源利用率也较低。
FiT 使用 N 中心的分布式多活数据中心架构,可避免单机房网络抖动导致数据库服务不可用的场景。另一方面,每个机房都是主机房,都有写流量,充分利用硬件与机房资源,使得容灾能力得到巨大提升。
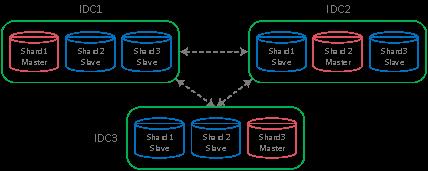
三中心的分布式多活架构
从上面的架构图中可以看到,每个 IDC 机房都有分布式数据库中每个分片的主节点,即每个机房都可以进行写入,机房是多活的。通过 MySQL 原生的无损半同步复制机制实时将数据同步到另外 2 个机房,确保数据一致性。为了避免网络抖动导致的服务不可用,可以将半同步复制设置为大多数原则,只要有大部分机房(上述就是 2 个)收到数据,事务即可提交。若 IDC 1 到 IDC 3 的网络发生抖动,由于 IDC1、IDC2 没有受到影响,满足大多数原则,数据服务依然可用。同样地,IDC 3、IDC 2 之间的网路之间没有受到影响,IDC 3 的数据服务依然可用。若 IDC1 的整个出口网络发生故障,则会在 IDC2、IDC3 中选出最新的主机继续提供服务。
在三中心架构下,每次事务提交的日志需要实时同步其他机房,可能带来的影响仅仅是每个事务的耗时最大增加 2ms,对绝大部分业务都可接受。对于三个中心所在的地理位置,其实并没有特别的要求,可以是深圳的三个 IDC,即一地三中心。也可以是深圳,东莞三个 IDC,即两地三中心。甚至可以是深圳、东莞、惠州的三地三中心架构。这里的主要限制是网络延迟,尽量选择多个 IDC 的网络延迟在 5ms 以下。
在三中心架构下,若某一个分片的主机发生宕机,则会切换到另一个 IDC 机房。然而,传统基于 VIP 切换的高可用架构无法适应跨核心路由器的架构。FiT 采用名字服务解决此问题,即每个数据库实例都有一个名字,例如 shard1.user.com,业务连接的不再是传统 IP,而是名字服务,由名字服务负责对 IP 的管理。为了实现业务透明性,FiT 使用 DNS 协议,自研了 DNS 服务器,并通过 Paxos 分布式共识算法确保每个名字数据的一致性。同时,在 DNS 基础上,我们还实现了类似传统 LVS 的负载均衡功能,从而在跨 IDC 场景下,依然可以实现对于业务透明的读写分离解决方案。
FiT 核心用户资金账户库有数千个分片,通过 LXC 资源隔离机制的多实例架构,存放在近数千台物理服务器上。加之其他业务,目前总共有近万个数据库实例。对于如此巨大的服务器数量,以及复杂的容灾架构,内部自研了一套智能云数据库管理平台 FMHA,所有上述的数据库管理,包括容灾、备份、查询、工单、DNS 等都由 FMHA 提供。对于数据库容灾切换,使用 Raft 算法进行自动选主,当宕机节点恢复时又可自动加入到原集群,所有的操作都是自动且自愈的,无需人工介入。
FMHA 是 For Make Happy Again 的缩写,我们希望 FMHA 能够带给 DBA、运维和开发人员快乐,提升工作效率,从枯燥的运维中解放出来。对于目前近万个 MySQL 实例,DBA 运维团队的人数一直控制在不到 20 人。
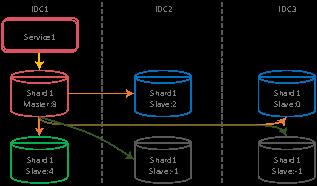
一个分片,四个实时同步副本,存放在三个数据中心
前面讲到 FiT 的分布式 MySQL 集群中,每个分片都是基于机房级进行数据实时复制。但是为了提供更好的业务体验,我们并不是简单地将数据副本存放在三个机房中。简单总结来说,FiT 的设计是一个分片数据有四个实时同步的副本,存放在三个数据中心中,并通过优先级算法机制进行数据库的容灾切换。
这样设计的好处是便于控制容灾切换,从而更有利于提升业务的整体性能。在图 3 中,红色,绿色,蓝色的 DB 表示是实时进行半同步复制的节点,灰色节点是异步节点。其中优先级分别是 8、4、2、0、-1。Master 节点的优先级最高,优先级为 4 的节点是同机房的节点,这表示发生容灾切换时,即使跨 IDC 的机房副本数据更多,亦是将优先级为 4 的节点提升为主。这样同机房切换优先设计的优势是当发生切换后,上层服务尽可能访问的还是同机房的主机,业务在响应延迟上不会受到影响。而这对于微信支付这样海量并发访问的系统尤为重要。
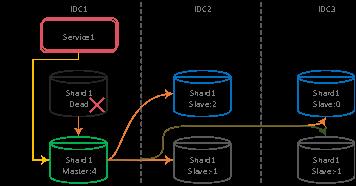
基于优先级的切换,尽可能确保上层服务和数据同机房
基于优先级算法切换解决了同机房切换后,业务访问 DB 的响应延迟问题。然而,当发生数据库所在机房级宕机的场景,比如 DB 所在的机架宕机,但是上层服务没有故障,则此时虽然数据库能够切换到跨 IDC 机房,但上层服务会的每一次数据库访问都会跨 IDC,响应耗时将随着事务中 SQL 数量而不断放大。
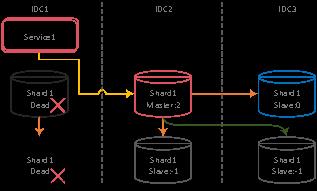
DB 发生机房级切换后,上层服务会出现跨 IDC 的数据库请求
为此,FMHA 在实现切换逻辑时会判断是否发生了机房级切换,若是,则会发送消息到队列,上层服务通过订阅发现切换消息后,会自动发起跨机房的上层服务切换。这样能确保及时发生机房级容灾切换,不会对上层服务的响应延迟造成任何影响。即数据层的切换与上层服务的切换是联动进行,确保提供更好的用户体验。
金融行业,数据一致性要求尤为严格,容不得一点错误。FiT 的 MySQL 集群通过 Raft 算法机制进行选主,并通过数据库本身的半同步复制机制进行了数据一致性的保障,但任何算法实现都会存在 bug,如何确保依赖的算法库不会存在 bug?比如 5.7.19 版本前,如若启用并行复制特性,则有可能导致主从数据的不一致。
为此,FMHA 平台会提供基于分钟级的数据核对,准实时地核对主从数据副本的一致性,而这种核对基于逻辑记录,而不依赖数据库本身的同步机制。这对数据一致性来说,又多了一层兜底机制,并能在分钟级别发现可能存在的主从数据副本不一致的情况。
除了数据库机制,FiT 还会通过业务层进行事务核对、会计核对,确保用户资金的安全。至今,FiT 从未发生过一起的用户或商户的数据库资金丢失。
备份系统是兜底中的兜底系统。FiT 的 Medusa 备份系统会定期对每个实例进行全备,并实时进行增量备份。更为重要的是,Medusa 平台会通过一定的调度算法对每个备份进行检验,一是确保备份文件是可靠的,能够恢复的。另一方面,备份恢复的实例将会连上线上系统,并最终进行数据核对,确保备份的数据内容也是安全可靠。
目前 FiT 的分布式 MySQL 数据库集群承担了整个腾讯支付与金融业务,MySQL 实例数量近万。这其中不仅包括交易信息流数据的存储,还包括在线核心账户资金的数据存储,比如微信支付的用户余额数据。在核心支付场景下,通过 FiT 设计的分布式 MySQL 数据库集群架构,以及业务等团队的不断打磨,连续两年数据库可用性达到 99.999%,并在春节除夕时支撑了红包业务超 20 万的 TPS 请求。
在容灾方面,FiT 的 MySQL 数据库集群主流架构模式为一地三中心和三地五中心的金融级数据库集群架构,即使发生机房级,甚至是城市级灾难,数据库集群都能自动地进行切换与自愈,数据库的整体切换时间在 30 秒内。即 RPO 0,RTO 30 秒。此外,容灾团队会定期设计各种灾难场景,不断对数据库进行各种故障恢复演练。这不仅仅是只在测试环境中验证,更重要的是,容灾团队会在线上核心用户余额数据库上进行验证。由于分布式 MySQL 集群架构,容灾团队可以灰度按分片逐批次进行验证。灰度演练这种方式,既能在线测试容灾可靠性,又能考验容灾演练时的用户体验。
FiT 的数据库已是世界最大的金融级分布式 MySQL 集群,然而支付与金融的业务每年还在不断增长,对于数据库和业务团队的挑战仍然在不断涌现。对于数据库团队来说,在保障现有系统的健壮性前提之下,我们也在探索下一代金融级数据库架构的演进。
MGR(MySQL Group Replication)的出现给予了我们新的思路和架构方向,并且我们在两年前就已在部分在线金融业务上尝试 MGR 的应用,并逐步将一些核心系统的数据库迁移至 MGR 集群。MGR 不但通过 Paxos 分布式共识算法保证了数据的一致性,更为重要的是,MGR 提供的多节点多主(Mulit-Master)模式将推动 MySQL 乃至整个数据库系统进入到崭新的多写(Multi-Write)新时代。
点个在看少个 bug 以上是关于全球最大金融级分布式MySQL集群实践:5个9可用性20万TPS快乐运维的主要内容,如果未能解决你的问题,请参考以下文章 巨杉 Tech | SequoiaDB SQL实例高可用负载均衡实践