Karmada 千级容器集群:工商银行业务容灾管理设计利器
Posted 白鹿第一帅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Karmada 千级容器集群:工商银行业务容灾管理设计利器相关的知识,希望对你有一定的参考价值。
前言
华为云 AI 主打智慧园区、智慧物流两个行业数字化转型的解决方案。AI 开发的难点较多,在未接触 ModelArts 之前,首先在数据的预处理方面,标注会花费大量的时间;在训练的时候需要购置很多的 GPU 的一些设备,这是价值不菲的;在部署方面非常的困难、繁琐。近年来随着云原生技术的不断成熟,越来越多的企业选择云原生作为数字化转型的核心支撑,华为云率先提出云原生 2.0 的理念,将引领企业云化建设从“On Cloud”迈向“In Cloud”,进入智能升级新阶段。
一、工行业务背景
近几年互联网的崛起对金融领域的金融模式、服务模式产生了巨大的冲击,迫使行业不得不做出巨大的革新。银行业务系统“入云”已经是大势所趋,在这方面工商银行已经处于行业一线,截止目前已经形成了基础设施云(Iaas)、应用平台云(Paas)、金融生态云(SaaS)以及具有工行特色的分行云(BCloud)四位一体的云平台架构。
1.1、工行云计算架构组成
工行云平台具体架构如下图所示:
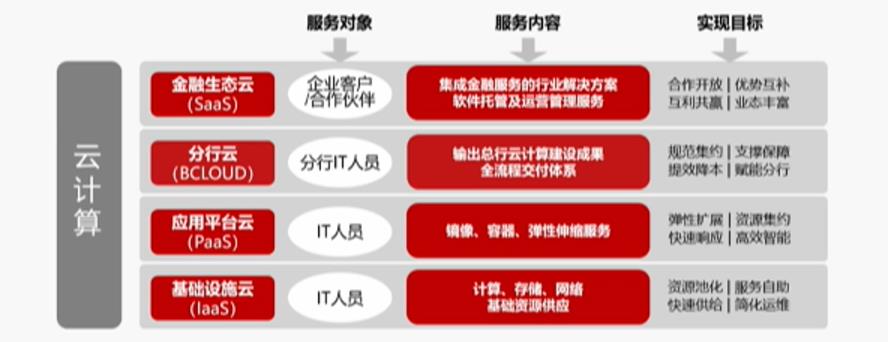
以上四大模块各自分发所负责的内容如下:
- 基础设施云(IaaS):面向基础设施运维人员,提供计算、存储、网络等底层资源快速供给的能力。
- 应用平台云(PaaS):面向应用运维人员,提供软件资源(环境、中间件和应用程序)快速供给及快速部署的能力。
- 金融生态云(SaaS):面向企业客户,联合合作伙伴,提供与工行金融服务紧密集成的行业解决方案,同时为合作伙伴提供 SaaS 软件托管及运营管理服务。
- 分行云(BCloud):面向工行的“公有云”,提供分行应用软件托管、DevOps、运维管理能力并输出总行新的一些云计算建设成果。
1.2、工行云平台技术栈
工行云平台基于业界领先云产品和开源主流技术,结合工行特色实现金融级自主定制,技术栈如下图所示:
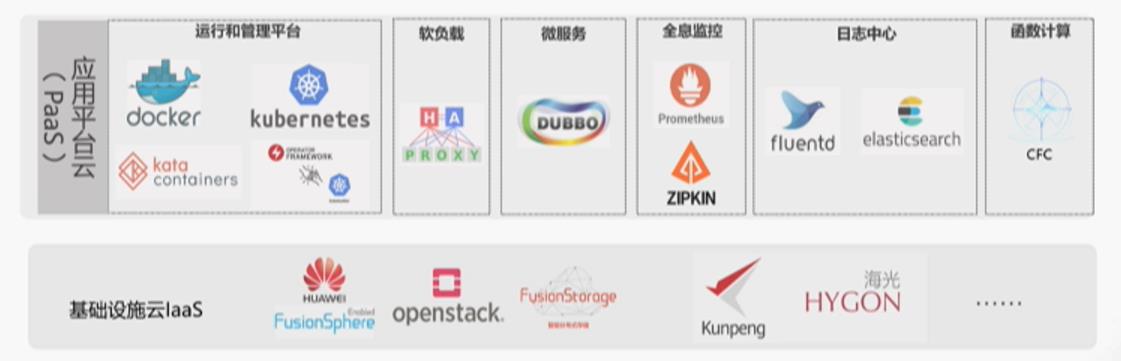
- 基于华为云 Stark 8.0 产品结合运营运维需求进行客户化定制,构建新一代基础设施云。
- 通过引入开源容器技术 Docker、容器集群调度技术 Kubernetes 等,自主研发建设应用平台云。
- 基于 HaProxy、Dubbo、ElasticSerch 等建立负载均衡、微服务、全息监控、日志中心等周边配套云生态。
1.3、工行金融云成效
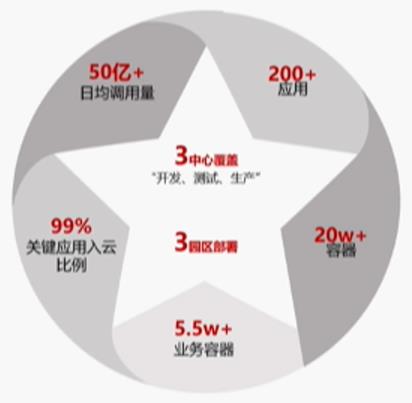
1.3.1、入云规模同业最大
应用平台云容器规模超 20w,业务容器规模 55000+,核心应用基本全面入容器云,入云情况如下图所示:
1.3.2、业务如云场景广
应用入云涉及业务广,并支撑多个关键领域,如以个人金融、线上渠道为代表的核心业务应用;以分布式服务框架、mysql 数据库为代表的技术支撑应用;以物联网、区块链、机器学习、大数据为代表的新技术领域应用,综合情况如下图所示:
1.4、容灾及高可用保障
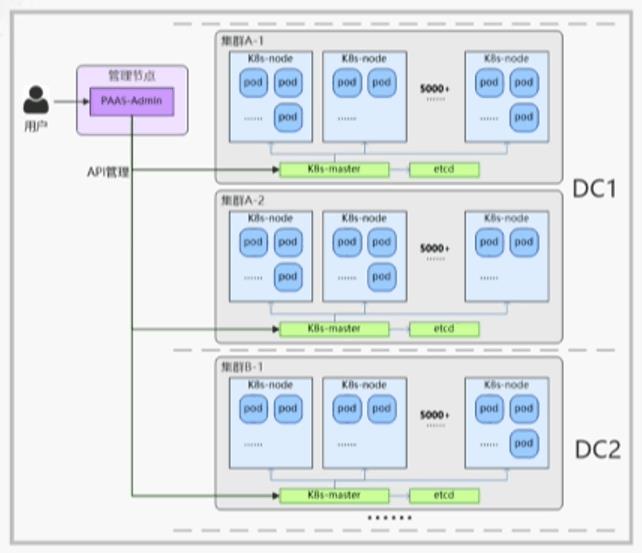
- 云平台支持多层次故障保护机制,确保同一业务的不同实例会均衡分发到两地三中心的不同资源域,在低粒度下细分故障域,确保单个存储、单个集群甚至单个数据中心发生故障时,不会影响业务的整体可用性,调度情况如下图所示:

- 在故障情况下,基于 k8s 自身优势,云平台通过容器重启及自动漂移,实现故障的自动恢复,如下图所示:

1.5、PaaS 层多集群现状
k8s 集群总数近百个,并且在不断地扩张中,细究主要原因我们将其分为以下四点。
1.5.1、集群种类多
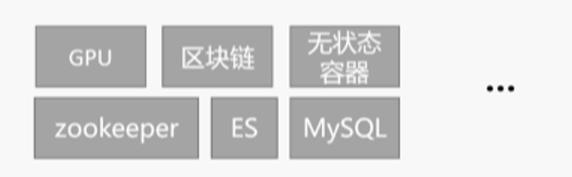
由于业务场景较为广泛,支持 GPU 的设备、中间件、数据库、底层的容器网络,不同的需求导致产生不同的解决方案,所以需要为不同的业务场景定制不同的集群,如下图所示:
1.5.2、k8s 集群 node 数量限制
受到 k8s 本身性能的限制,每个集群都有自己数量的上限。
1.5.3、业务扩展快
截至目前,包括传统应用在内的各个业务在源源不断地切入到容器云内。
1.5.4、故障域分区多
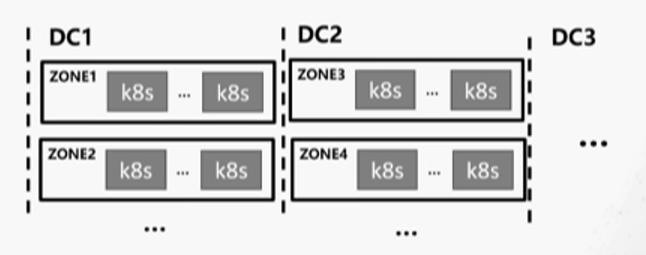
以上述 1.4 内容为例,两地三中心的设计,包括三个 DC,每个 DC 内部又通过不同的网络区域防火墙进行隔离,以实现故障域分发,如下图所示:
1.6、针对多集群现状的解决方案
- 容器云云管平台超级管理员接纳、运维多集群。
- 上层业务应用自主选择集群,包括网络区域在内的等等内容。
- 集群内同一模版故障域自动打散。
1.7、解决方案下存在的问题
- 无跨集群自动伸缩。上了容器云之后,在业务峰值时集群内部缺乏自动伸缩能力。
- 无跨集群调度能力。
- 集群对上层用户不透明。
- 无跨集群故障自动迁移能力,整体上依靠“两地三中心”架构上的冗余,在自动化恢复上的高可用能力存在缺失。
二、架构选型
2.1、实现目标
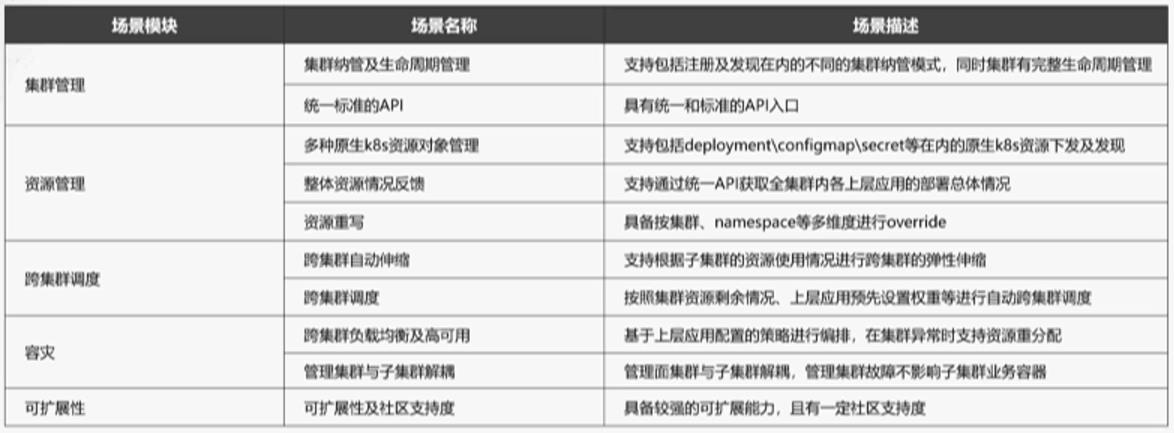
基于以上存在的问题,我们定下了相应的目标,并对目前业界所采用的方案进行了技术选型,五个多云的集群模块目标如下表所示:
2.2、为什么希望部分模块是具有社区支持度的开源项目?
- 希望整体的方案是在企业内部自主可控的。
- 不希望花费更多的能力去重复“造轮子”。
- 希望整体管理的多集群模块是从云管平台中隔离出来,下沉到下面的多集群管理模块之中。
基于以上的目标,社区做了相当多的调研,包括但不局限于社区中众多的项目。
2.3、Kubefed 的优势与不足
优势:本身可以解决部分问题,具有集群生命周期管理,具有部分 Override,以及一些基础调度的能力,其能力如下图所示:
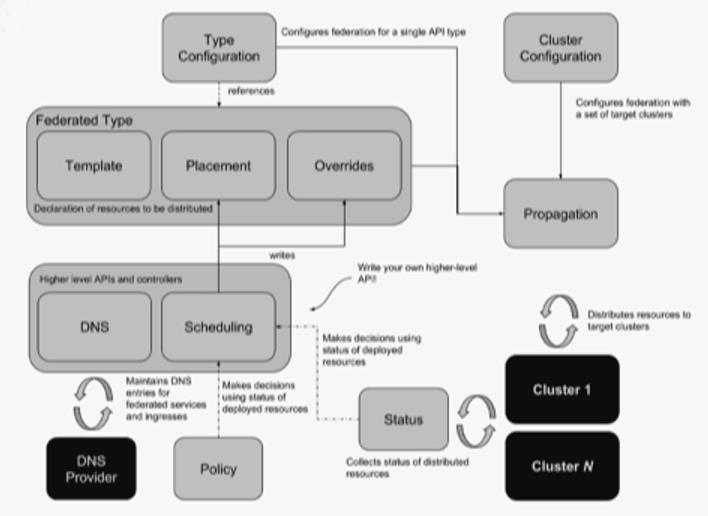
不足:调度层面太过于基础,且 Kubefed 负责的社区团队不准备在调度方面下更大的精力以支持如自定义的调度,包括不支持按资源余量的调度;最为人所诟病的一点——本身不支持原生 k8s 对象,需要在管理集群中使用其所新定义的一些 CRD,对于已经使用了很久原生 k8s 资源对象的上层应用,包括云管平台在内对接的一些 API 则需要进行重新开发,而这部分的成本是非常巨大的;整体上不具备故障自动迁移能力。基于以上不足,综合考量,Kubefed 我们暂不考虑。
2.4、RHACM 的优势与不足
RHACM 是红帽与 IBM 主导的项目,其功能架构如下图所示:
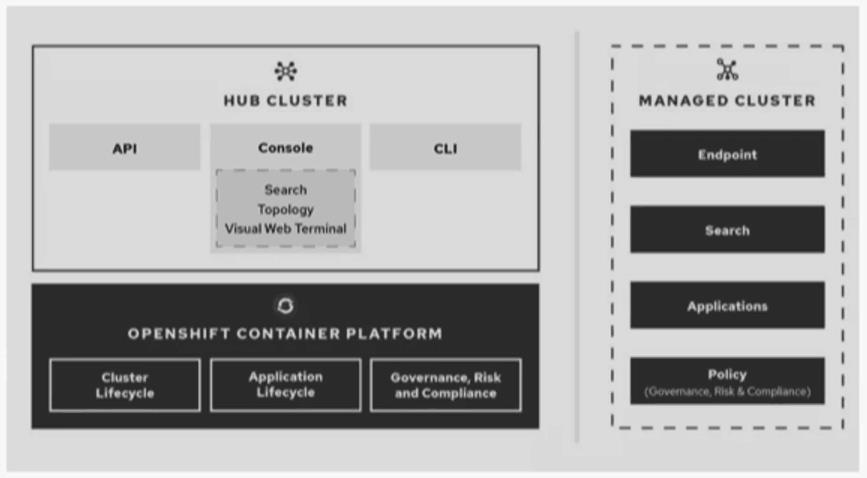
- 功能比较健全,但仅支持 Openshift,对于存量大量 k8s 集群的现状而言,改造的成本是巨大的。
- 暂未开源,社区支持力度不够。
2.5、Karmada 现真身
Karmada 整体的功能视图如下图所示:
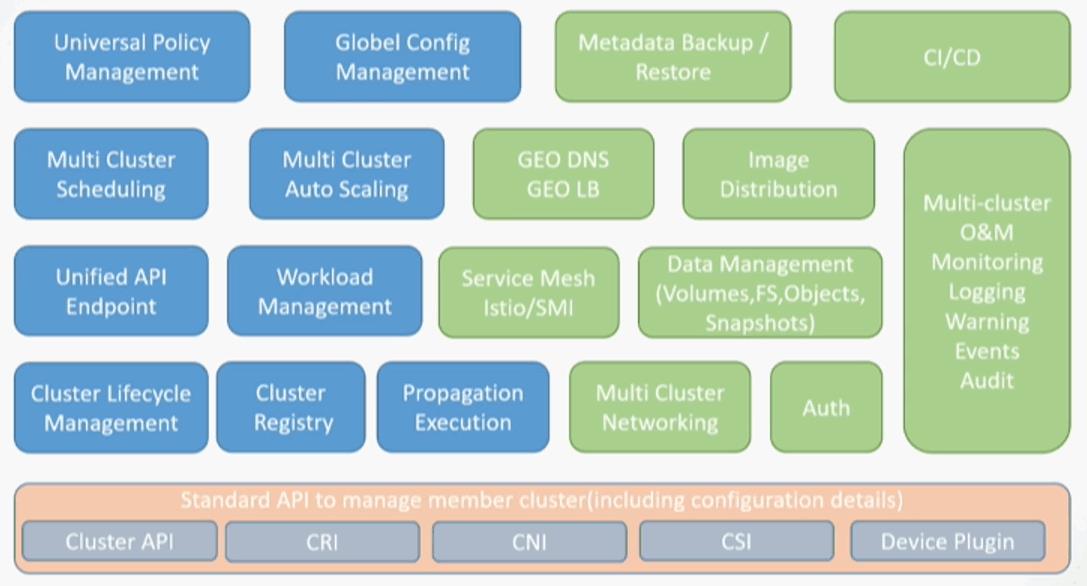
Karmada 相当契合我们在上述 2.1 小节中的实现目标要求,具有整体的集群生命周期管理、集群注册,包括多集群的伸缩、调度、统一的 API、底层的标准 API 支持,并且 CNI、CSI 在其整体的功能视图中,对 CI/CD 有整体上的规划与考虑,所以工行最终决定投入到该项目中,与华为在内的一系列伙伴共建该项目并回馈到社区中。
三、为什么选择 Karmada?
3.1、技术架构.
Karmada 目前经在社区中开源,相关信息及技术架构大家可以移步社区查看,主要架构如下图所示:
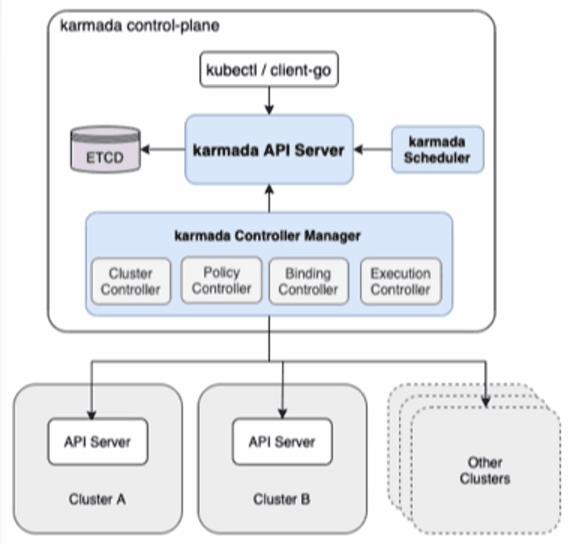
3.2、技术优势
- Karmada 以类 k8s 的形式部署,以作为管理面集群,改造成本较低。
- Karmada-Controller-Manager 管理包括 cluster、policy、binding、works 等多种 CRD 资源作为管理端资源对象,没有侵入到原生的 k8s 资源对象。
- Karmada 仅管理资源在集群间的调度,子集群内分配高度自治,这对于分布式系统是必须的。
3.3、Karmada Resources 如何分发?
Karmada Resources 分发流程示意图如下图所示:
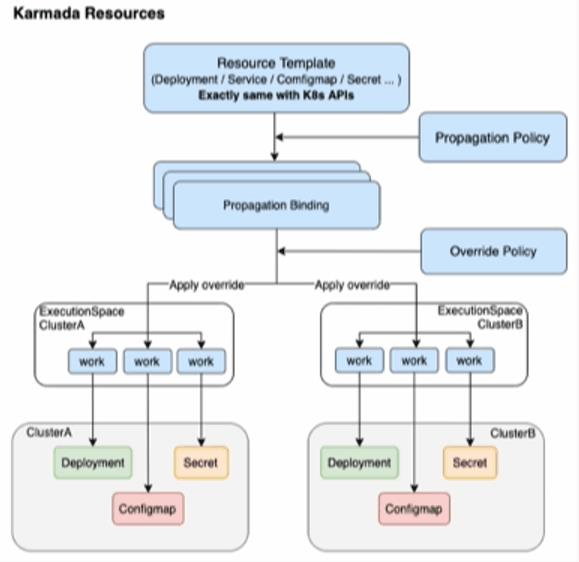
Karmada Resources 分发流程如下:
- 集群注册到 Karmada。
- 定义 Resource Template。
- 制定分发策略 Propagation Policy。
- 制定 Override 策略。
- 看 Karmada 干活。
3.4、Propagation 机制
Propagation 机制分发如下:

Propagation Policy 信息配置如下图所示:
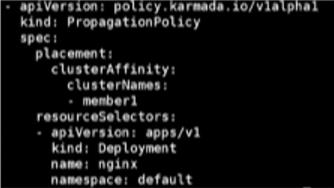
- 集群亲和性。
- 集群容忍。
- 按集群标签、故障域分发。
Resource Binding/Cluster Resource Binding 信息配置如下图所示:
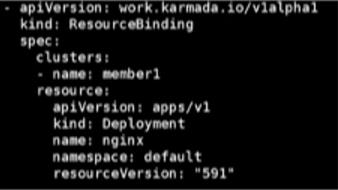
- 支持 cluster\\namespace scope。
3.5、Work 机制
具体的 Work 分发机制如下图所示:
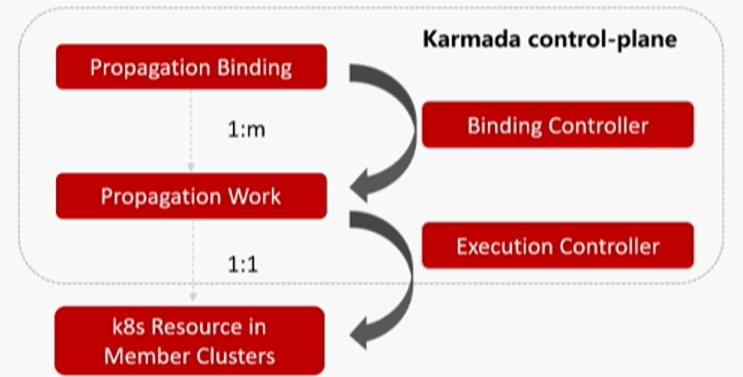
Work 信息配置如下图所示:
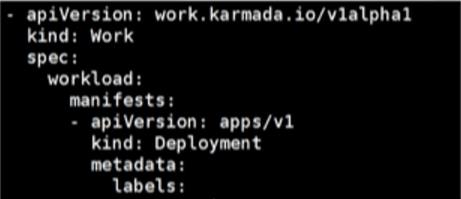
- Works 仅是 k8s Resource 的封装。
- Works 的 status 作为子集群 resource 的反馈。
3.6、Karmada 优势
经过验证我们将 Karmada 的优势分为以下四块。
3.6.1、资源调度
- 自定义跨集群调度策略。
- 对上层应用透明。
- 支持两种资源绑定调度。
3.6.2、容灾
- 动态 binding 调整。
- 按照集群标签或故障域自动分发资源对象。
3.6.3、集群管理
- 支持集群注册。
- 全生命周期管理。
- 统一标准的 API。
3.6.4、资源管理
- 支持 k8s 原生对象。
- works 支持子集群资源部署状态获取。
- 资源对象分发既支持 pull 也支持 push 方式。
四、落地展望
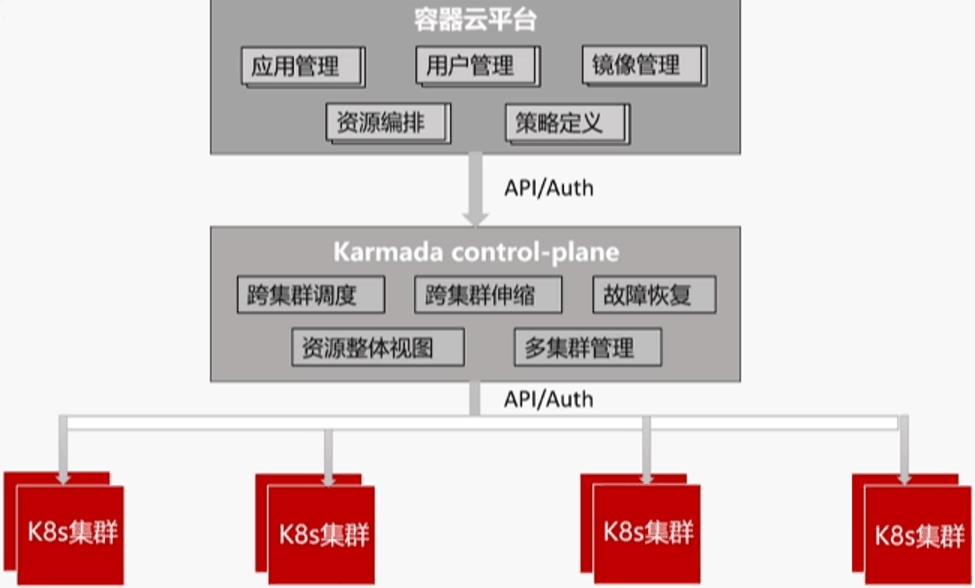
4.1、云平台集成
目前为止,在工行的测试环境中,Karmada 已经对现存集群进行了纳管,存在的问题是如何与整体云平台进行集成。
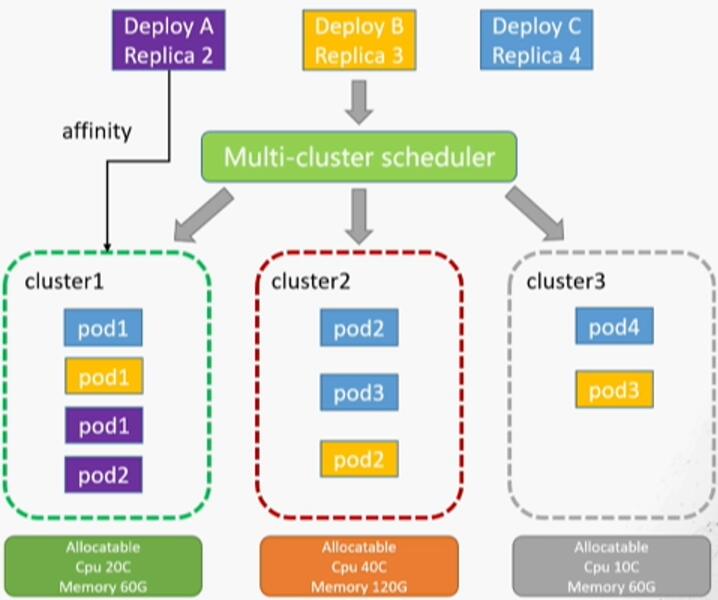
4.2、跨集群调度
- 故障域打散。
- 应用偏好设置、权重。
- 集群资源余量调度。
我们最终的期望实现效果如下图所示:
4.3、跨集群伸缩
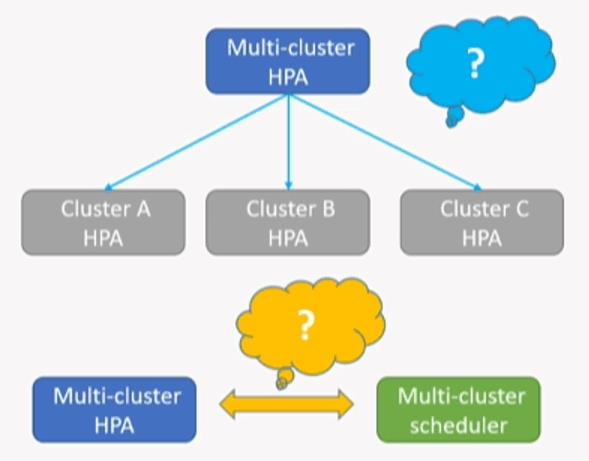
- 跨集群伸缩与子集群伸缩之间的关系。
- 跨集群伸缩与跨集群调度间的关系。
4.4、跨集群故障恢复与高可用
- 子集群健康状态的判断策略。可能只是与管理集群失联,子集群本身业务容器均无损。
- 自定义的故障恢复策略。Like RestartPolicy、Always、Never、OnFailure。
- 重新调度和跨集群伸缩的关系。
总结
本文介绍了工行云平台的现状,包括容灾和多 k8s 集群,调研了业界多集群管理方案及选型,从而确定选择 Karmada,介绍了包括其优势、技术架构以及具体的机制,最后介绍了 Karmada 在工行的落地情况以及在未来中希望产生和应用的场景。从 Karmada 近日宣布开源之后,我们希望有越来越多的开发者加入到社区中,共建多云管理的社区生态。
我是白鹿,一个不懈奋斗的程序猿。望本文能对你有所裨益,欢迎大家的一键三连!若有其他问题、建议或者补充可以留言在文章下方,感谢大家的支持!
以上是关于Karmada 千级容器集群:工商银行业务容灾管理设计利器的主要内容,如果未能解决你的问题,请参考以下文章