深入撩撩分布式事务
Posted 西二旗阵地上的Tsinghua兵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入撩撩分布式事务相关的知识,希望对你有一定的参考价值。
上回撩到分布式事务,由于时间仓促,在门口蹭了蹭就收兵了。这次深..入..使..劲..撩撩
单机(单物理库)场景下的事务。
凡事讲究个循序渐进,我们从单物理库事务撩起。如下图所示的场景(注:代码为示例代码,非线上实操代码,下同):
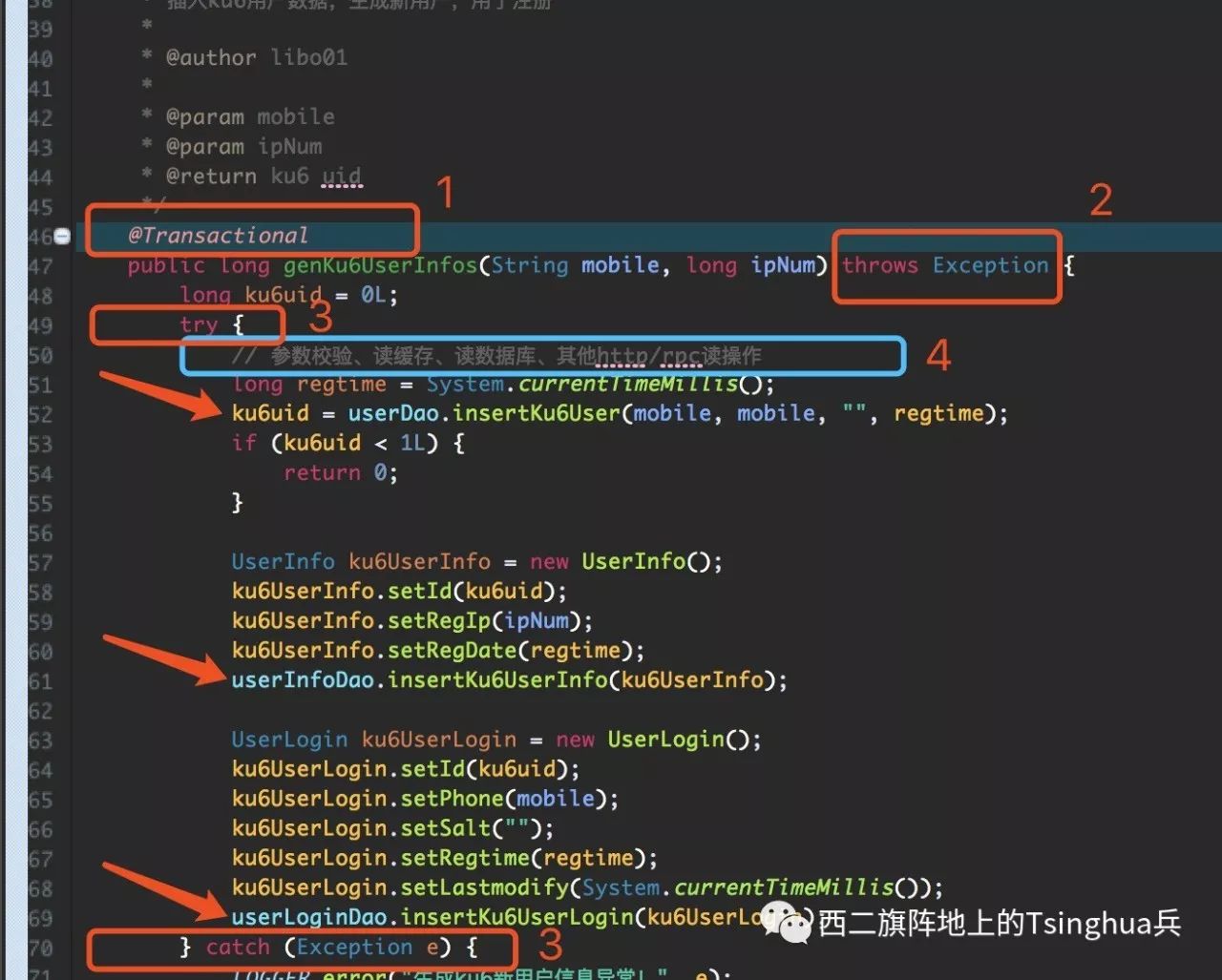
某个用户注册流程,涉及如图箭头所示3表插入(3表都在同一物理库)。如果其中某个插入过程发生异常或者过程中遭遇服务重启,可能只有部分表数据写入,导致业务错误。我们的期望是3个插库操作要么都成功,要么都失败,保持“业务的原子性”。由于3表都在同一数据库,解决方案很简单:使用Spring的事务管理即可(图中红框1)。
顺带强化下Spring事务管理的注意事项:
(1)如果使用mysql,数据表engine需要为InnoDB等支持事务类型。
(2)如果集成Spring和SpringMVC,SpringMVC的扫描包<context:annotation-config>需配置只扫@Controller,否则位于service层的事务注解所在service bean会在两种容器中都有实例,且一般SpringMVC context都在Spring后初始化,导致调用的service bean是SpringMVC容器初始化的,事务管理不起作用。
(3)checked异常不会触发事务回滚。即:事务内部catch了的异常(如图红框3),和事务方法上已显式throws了的异常(如图红框2)。
(4)触发回滚的异常类型,默认需为RuntimeException(当然,可通过noRollbackFor或RollbackFor=Exception.class指定异常类型回滚)。
(5)注意事务的传播特性和隔离级别。一般地,隔离级别依赖数据库本身的隔离级别,MySQL默认为Repeatable Read(可重复读)。
(6)Spring事务管理基于AOP实现,即粗暴的说就相当于在你打@Transactional注解的方法所用的JDBC连接session中将方法中的多个sql使用start transaction;commit;rollback;三段式包裹。当AOP使用JDK Dynamic Proxy时,同一个service中非事务方法调起事务方法,事务失效。但改用cglib Proxy时,没有这个问题。至于原因,简言之:JDK Dynamic代理是在接口类对应的具体实现方法上进行织入代理,当同一个service中非事务方法调起事务方法时,该非事务方法调用的已经是实现类原始的方法,而非通过事务注解增强的代理方法;而cglib则是对具体实现类的方法通过继承方式代理。还不懂?找度娘搞一发
(7)由于Spring事务最小粒度到方法,所以对于打事务注解的方法,务必保证是真正需要事务控制的逻辑。事务需尽可能短,事务中不可有不必要的网络调用(读cache、读库、http/RPC纯读操作等)如图蓝框4所示。否则,平时浪的飞起,高峰期系统并发上来后,莫名其妙的频繁FullGC可能和它有关了(根据CAP理论,事务保证原子性实际是牺牲并发度换来的,事务控制的方法在性能上和加锁方法相似,耗时的网络读操作放在其中,导致该方法成为瓶颈;外围可能很多调用该方法的地方只能排队且越堆越多,而这些方法可能持有大量对象的引用,所以你懂得)。
单机场景下事务已经被我们扒的精光了,下面该更进一步了
2. 分布式事务。
将上述单机事务扩展,如果1中的三个数据表在不同的物理库上,如之奈何?我们知道Spring的Transaction Manager是作用于DataSource的,本质就是start transaction;commit;rollback;三段式。事务在单物理库内通过锁、redo/undo log及MVCC实现,对于跨物理库的事务无能为力。
除了跨物理库事务,更一般地,我们的业务系统经常会通过http/rpc、消息中间件和其他若干系统交互,如何保证一致性?以下图场景为例:
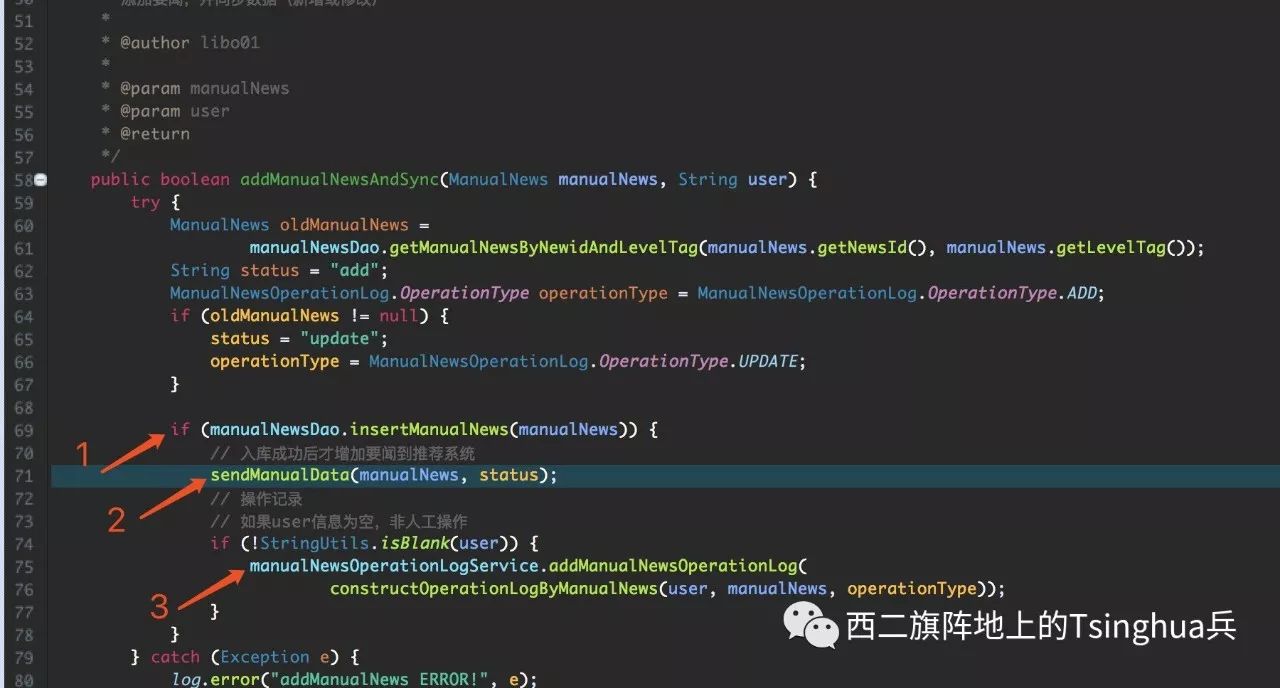
其中,箭头1和3为数据库插入操作,2为使用kafka发数据推送消息。简单起见,我们仅研究1和2,如何保证1和2的一致性?即,1插库成功后,即将执行2时该代码所在实例重启了或者2依赖的消息系统挂了、调用网络不可用等等,导致最后业务状态变成:本地系统显示成功写入了一条数据,然而下游系统却没有收到同步的数据。
怎么办?上回说到过分布式事务有很多实现方式:1/2/3阶段提交、TCC、本地消息表、事务消息、业务补偿等等。
在此,我们采用常用的本地消息表+业务补偿实现最终一致性来fix它:在步骤1之后,从70行开始添加一个将2即将发送的消息连同其状态字段入和1同库的消息表,并将该插入消息表操作和1放在同一个@Transactional事务中。由于同物理库,上述两个步骤能保证原子性,且消息表状态字段记录了消息的发送状态。在2之后,从72行开始,添加更新消息表状态操作。再来看和前段描述相同的场景,如果2阶段发生异常或者在即将执行2前系统重启,那么之前写入的消息状态不会更新。起一个Quartz定时任务,数分钟批量将数据库消息表中状态位仍为未发送成功的消息重发、置位即可。
当然,新的问题又来了(要想不丢,则不太可能不重,除非消息中间件支持exactly once,然而通常代价是很高的):这样重发,可能第一次已经发送消息系统成功了,只是因为重启、网络等原因没有收到响应。消息系统中可能有重复的消息。去重成为下一个议题。常见地,我们借助全局id生成器(比如数据库自增id、redis incr等等)为消息设置key,通过以此key为key的redis set数据结构为buffer或者consumer端使用数据库唯一索引等策略实现去重。
分布式事务博大精深,本次仅实操了一种常见体位,持续解锁淫技中
libo09@mails.tsinghua.edu.cn
以上是关于深入撩撩分布式事务的主要内容,如果未能解决你的问题,请参考以下文章