分布式事务原理及解决方案
Posted JAVA高级架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务原理及解决方案相关的知识,希望对你有一定的参考价值。
1 引言
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在这几年越来越火的微服务架构中,几乎可以说是无法避免,本文就围绕单机事务,分布式事务以及分布式事务的处理方式来展开。
2 事务
事务提供一种“要么什么都不做,要么做全套(All or Nothing)”的机制,她有ACID四大特性
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
2.1 单机事务
以mysql的InnoDB存储引擎为例,来了解单机事务是如何保证ACID特性的。
2.2 分布式事务
单机事务是通过将操作限制在一个会话内通过数据库本身的锁以及日志来实现ACID,那么分布式环境下该如何保证ACID特性那?
2.2.1 XA协议实现分布式事务
2.2.1.1 XA描述
X/Open DTP(X/Open Distributed Transaction Processing Reference Model) 是X/Open 这个组织定义的一套分布式事务的标准,也就是了定义了规范和API接口,由各个厂商进行具体的实现。 X/Open DTP 定义了三个组件: AP,TM,RM
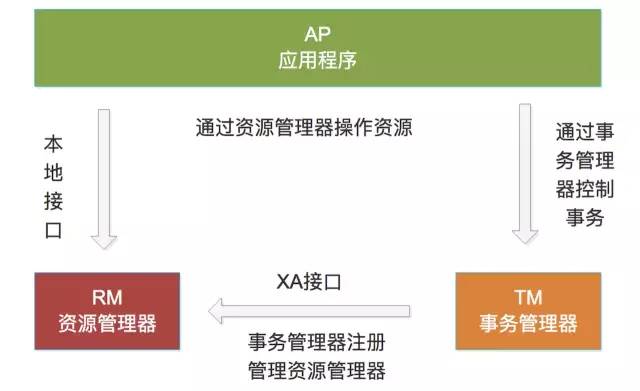
AP(Application Program):也就是应用程序,可以理解为使用DTP的程序
RM(Resource Manager):资源管理器,这里可以理解为一个DBMS系统,或者消息服务器管理系统,应用程序通过资源管理器对资源进行控制。资源必须实现XA定义的接口
TM(Transaction Manager):事务管理器,负责协调和管理事务,提供给AP应用程序编程接口以及管理资源管理器
其中在DTP定义了以下几个概念
事务:一个事务是一个完整的工作单元,由多个独立的计算任务组成,这多个任务在逻辑上是原子的
全局事务:对于一次性操作多个资源管理器的事务,就是全局事务
分支事务:在全局事务中,某一个资源管理器有自己独立的任务,这些任务的集合作为这个资源管理器的分支任务
控制线程:用来表示一个工作线程,主要是关联AP,TM,RM三者的一个线程,也就是事务上下文环境。简单的说,就是需要标识一个全局事务以及分支事务的关系
如果一个事务管理器管理着多个资源管理器,DTP是通过两阶段提交协议来控制全局事务和分支事务。
第一阶段:准备阶段 事务管理器通知资源管理器准备分支事务,资源管理器告之事务管理器准备结果
第二阶段:提交阶段 事务管理器通知资源管理器提交分支事务,资源管理器告之事务管理器结果
2.2.1.2 XA的ACID特性
原子性:XA议使用2PC原子提交协议来保证分布式事务原子性
隔离性:XA要求每个RMs实现本地的事务隔离,子事务的隔离来保证整个事务的隔离。
一致性:通过原子性、隔离性以及自身一致性的实现来保证“数据库从一个一致状态转变为另一个一致状态”;通过MVCC来保证中间状态不能被观察到。
2.2.1.3 XA的优缺点
优点:
对业务无侵入,对RM要求高缺点:
同步阻塞:在二阶段提交的过程中,所有的节点都在等待其他节点的响应,无法进行其他操作。这种同步阻塞极大的限制了分布式系统的性能。
单点问题:协调者在整个二阶段提交过程中很重要,如果协调者在提交阶段出现问题,那么整个流程将无法运转。更重要的是,其他参与者将会处于一直锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致:假设当协调者向所有的参与者发送commit请求之后,发生了局部网络异常,或者是协调者在尚未发送完所有 commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求。这将导致严重的数据不一致问题。
容错性不好:如果在二阶段提交的提交询问阶段中,参与者出现故障,导致协调者始终无法获取到所有参与者的确认信息,这时协调者只能依靠其自身的超时机制,判断是否需要中断事务。显然,这种策略过于保守。换句话说,二阶段提交协议没有设计较为完善的容错机制,任意一个节点是失败都会导致整个事务的失败。
2.2.2 TCC协议实现分布式事务
2.2.2.1 TCC描述
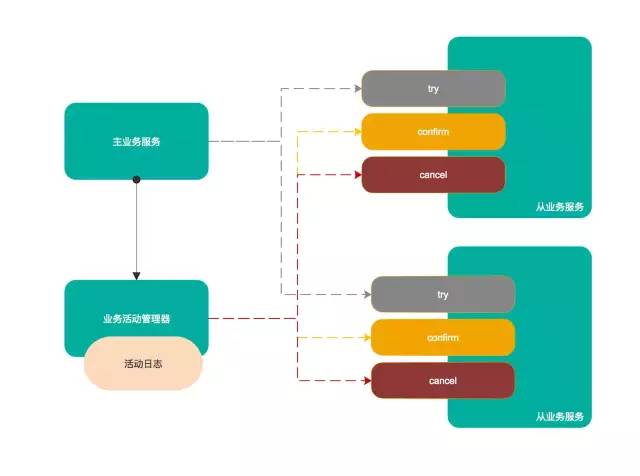
TCC(Try-Confirm-Cancel)分布式事务模型相对于 XA 等传统模型,其特征在于它不依赖资源管理器(RM)对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
第一阶段:CanCommit
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
事务询问:协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应
响应反馈:参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态;否则反馈No。
第二阶段:PreCommit
协调者在得到所有参与者的响应之后,会根据结果执行2种操作:执行事务预提交,或者中断事务
执行事务预提交
发送预提交请求:协调者向所有参与者节点发出 preCommit 的请求,并进入 prepared 状态。
事务预提交:参与者受到 preCommit 请求后,会执行事务操作,对应 2PC 准备阶段中的 “执行事务”,也会 Undo 和 Redo 信息记录到事务日志中。
各参与者响应反馈:如果参与者成功执行了事务,就反馈 ACK 响应,同时等待指令:提交(commit) 或终止(abort)
中断事务
发送中断请求:协调者向所有参与者节点发出 abort 请求 。
中断事务:参与者如果收到 abort 请求或者超时了,都会中断事务。
第三阶段:Do Commit
该阶段进行真正的事务提交,也可以分为以下两种情况
执行提交
发送提交请求:协调者接收到各参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送 doCommit 请求。
事务提交:参与者接收到 doCommit 请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
响应反馈:事务提交完之后,向协调者发送 ACK 响应。
完成事务:协调者接收到所有参与者的 ACK 响应之后,完成事务。
中断事务
协调者没有接收到参与者发送的 ACK 响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
发送中断请求:协调者向所有参与者发送 abort 请求。
事务回滚:参与者接收到 abort 请求之后,利用其在阶段二记录的 undo 信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
反馈结果:参与者完成事务回滚之后,向协调者发送 ACK 消息。
中断事务:协调者接收到参与者反馈的 ACK 消息之后,完成事务的中断。
2.2.2.2 TCC的ACID特性
原子性:TCC 模型也使用 2PC 原子提交协议来保证事务原子性。Try 操作对应2PC 的一阶段准备(Prepare);Confirm 对应 2PC 的二阶段提交(Commit),Cancel 对应 2PC 的二阶段回滚(Rollback),可以说 TCC 就是应用层的 2PC。
隔离性:隔离的本质是控制并发,放弃在数据库层面加锁通过在业务层面加锁来实现。【比如在账户管理模块设计中,增加可用余额和冻结金额的设置】
一致性:通过原子性保证事务的原子提交、业务隔离性控制事务的并发访问,实现分布式事务的一致性状态转变;事务的中间状态不能被观察到这点并不保证[本协议是基于柔性事务理论提出的]。
2.2.2.3 TCC的优缺点
优点:
相对于二阶段提交,三阶段提交主要解决的单点故障问题,并减少了阻塞的时间。因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行 commit。而不会一直持有事务资源并处于阻塞状态。缺点:
三阶段提交也会导致数据一致性问题。由于网络原因,协调者发送的 Cancel 响应没有及时被参与者接收到,那么参与者在等待超时之后执行了 commit 操作。这样就和其他接到 Cancel 命令并执行回滚的参与者之间存在数据不一致的情况。
2.2.3 SAGA协议实现分布式事务
2.2.3.1 SAGA协议介绍
Saga的组成:
每个Saga由一系列sub-transaction Ti 组成
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果
saga的执行顺序有两种:
T1, T2, T3, ..., Tn
T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n
Saga定义了两种恢复策略:
backward recovery,向后恢复,即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
forward recovery,向前恢复,适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
Saga的注意事项
Ti和Ci是幂等的。举个例子,假设在执行Ti的时候超时了,此时我们是不知道执行结果的,如果采用forward recovery策略就会再次发送Ti,那么就有可能出现Ti被执行了两次,所以要求Ti幂等。如果采用backward recovery策略就会发送Ci,而如果Ci也超时了,就会尝试再次发送Ci,那么就有可能出现Ci被执行两次,所以要求Ci幂等。
Ci必须是能够成功的,如果无法成功则需要人工介入。如果Ci不能执行成功就意味着整个Saga无法完全撤销,这个是不允许的。但总会出现一些特殊情况比如Ci的代码有bug、服务长时间崩溃等,这个时候就需要人工介入了
Ti - Ci和Ci - Ti的执行结果必须是一样的:sub-transaction被撤销了。举例说明,还是考虑Ti执行超时的场景,我们采用了backward recovery,发送一个Ci,那么就会有三种情况:
1:Ti的请求丢失了,服务之前没有、之后也不会执行Ti
2:Ti在Ci之前执行
3:Ci在Ti之前执行
对于第1种情况,容易处理。对于第2、3种情况,则要求Ti和Ci是可交换的(commutative),并且其最终结果都是sub-transaction被撤销。
Saga架构
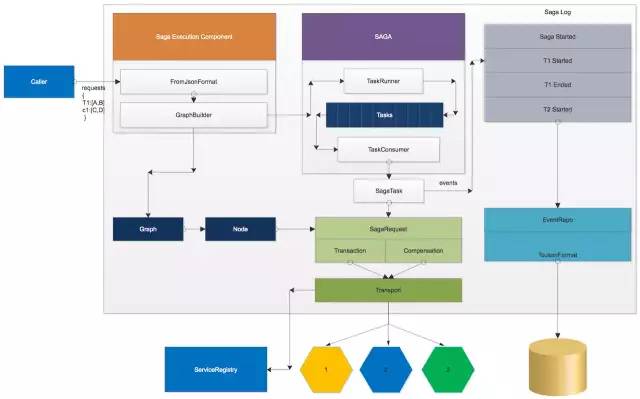
Saga Execution Component解析请求JSON并构建请求图
TaskRunner 用任务队列确保请求的执行顺序
TaskConsumer 处理Saga任务,将事件写入saga log,并将请求发送到远程服务
2.2.3.2 SAGA的ACID特性
原子性:通过SAGA协调器实现
一致性:本地事务+SAGA Log
持久性:SAGA Log
隔离性:不保证(同TCC)
3 分布式事务的处理方案
3.1 XA
仅在同一个事务上下文中需要协调多种资源(即数据库,以及消息主题或队列)时,才有必要使用 X/Open XA 接口。数据库接入XA需要使用XA版的数据库驱动,消息队列要实现XA需要实现javax.transaction.xa.XAResource接口。
3.1.1 jotm的分布式事务
代码如下:
public class UserService {
@Autowired
private UserDao userDao;
@Autowired
private LogDao logDao;
@Transactional
public void save(User user){
userDao.save(user);
logDao.save(user);
throw new RuntimeException();
}
}
@Resource
public class UserDao {
@Resource(name="jdbcTemplateA")
private JdbcTemplate jdbcTemplate;
public void save(User user){
jdbcTemplate.update("insert into user(name,age) values(?,?)",user.getName(),user.getAge());
}
}
@Repository
public class LogDao {
@Resource(name="jdbcTemplateB")
private JdbcTemplate jdbcTemplate;
public void save(User user){
jdbcTemplate.update("insert into log(name,age) values(?,?)",user.getName(),user.getAge());
}
}
配置:
<bean id="jotm" class="org.objectweb.jotm.Current" />
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="userTransaction" ref="jotm" />
</bean>
<tx:annotation-driven transaction-manager="transactionManager"/>
<!-- 配置数据源 -->
<bean id="dataSourceA" class="org.enhydra.jdbc.pool.StandardXAPoolDataSource" destroy-method="shutdown">
<property name="dataSource">
<bean class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
<property name="transactionManager" ref="jotm" />
<property name="driverName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8" />
</bean>
</property>
<property name="user" value="xxx" />
<property name="password" value="xxx" />
</bean>
<!-- 配置数据源 -->
<bean id="dataSourceB" class="org.enhydra.jdbc.pool.StandardXAPoolDataSource" destroy-method="shutdown">
<property name="dataSource">
<bean class="org.enhydra.jdbc.standard.StandardXADataSource" destroy-method="shutdown">
<property name="transactionManager" ref="jotm" />
<property name="driverName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8" />
</bean>
</property>
<property name="user" value="xxx" />
<property name="password" value="xxx" />
</bean>
<bean id="jdbcTemplateA" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSourceA" />
</bean>
<bean id="jdbcTemplateB" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSourceB" />
</bean>
使用到的JAR包:
compile 'org.ow2.jotm:jotm-core:2.3.1-M1'
compile 'org.ow2.jotm:jotm-datasource:2.3.1-M1'
compile 'com.experlog:xapool:1.5
事务配置: 我们知道分布式事务中需要一个事务管理器即接口javax.transaction.TransactionManager、面向开发人员的javax.transaction.UserTransaction。对于jotm来说,他们的实现类都是Current
public class Current implements UserTransaction, TransactionManager
我们如果想使用分布式事务的同时,又想使用Spring带给我们的@Transactional便利,就需要配置一个JtaTransactionManager,而该JtaTransactionManager是需要一个userTransaction实例的,所以用到了上面的Current,如下配置:
<bean id="jotm" class="org.objectweb.jotm.Current" />
<bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="userTransaction" ref="jotm" />
</bean>
<tx:annotation-driven transaction-manager="transactionManager"/>
同时上述StandardXADataSource是需要一个TransactionManager实例的,所以上述StandardXADataSource配置把jotm加了进去.
执行过程:
第一步:事务拦截器开启事务
我们知道加入了@Transactional注解,同时开启tx:annotation-driven,会对本对象进行代理,加入事务拦截器。在事务拦截器中,获取javax.transaction.UserTransaction,这里即org.objectweb.jotm.Current,然后使用它开启事务,并和当前线程进行绑定,绑定关系数据存放在org.objectweb.jotm.Current中。第二步:使用jdbcTemplate进行业务操作
dbcTemplateA要从dataSourceA中获取Connection,和当前线程进行绑定,同时以对应的dataSourceA作为key。同时判断当前线程是否含有事务,通过dataSourceA中的org.objectweb.jotm.Current发现当前线程有事务,则把Connection自动提交设置为false,同时将该连接纳入当前事务中。
jdbcTemplateB要从dataSourceB中获取Connection,和当前线程进行绑定,同时以对应的dataSourceB作为key。同时判断当前线程是否含有事务,通过dataSourceB中的org.objectweb.jotm.Current发现当前线程有事务,则把Connection自动提交设置为false,同时将该连接纳入当前事务中。第三步:异常回滚 一旦抛出异常,则需要进行事务的回滚操作。回滚就是将当前事务进行回滚,该事务的回滚会调用和它关联的所有Connection的回滚。
3.1.2 Atomikos的分布式事务
代码同上,配置为:
<bean id="atomikosUserTransaction" class="com.atomikos.icatch.jta.UserTransactionImp">
<property name="transactionTimeout" value="300" />
</bean>
<bean id="springTransactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="userTransaction" ref="atomikosUserTransaction" />
</bean>
<tx:annotation-driven transaction-manager="springTransactionManager"/>
<!-- 配置数据源 -->
<bean id="dataSourceC" class="com.atomikos.jdbc.AtomikosDataSourceBean" init-method="init" destroy-method="close">
<property name="uniqueResourceName" value="XA1DBMS" />
<property name="xaDataSourceClassName" value="com.mysql.jdbc.jdbc2.optional.MysqlXADataSource" />
<property name="xaProperties">
<props>
<prop key="URL">jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8</prop>
<prop key="user">xxx</prop>
<prop key="password">xxx</prop>
</props>
</property>
<property name="poolSize" value="3" />
<property name="minPoolSize" value="3" />
<property name="maxPoolSize" value="5" />
</bean>
<!-- 配置数据源 -->
<bean id="dataSourceD" class="com.atomikos.jdbc.AtomikosDataSourceBean" init-method="init" destroy-method="close">
<property name="uniqueResourceName" value="XA2DBMS" />
<property name="xaDataSourceClassName" value="com.mysql.jdbc.jdbc2.optional.MysqlXADataSource" />
<property name="xaProperties">
<props>
<prop key="URL">jdbc:mysql://localhost:3306/test2?useUnicode=true&characterEncoding=utf-8</prop>
<prop key="user">xxx</prop>
<prop key="password">xxx</prop>
</props>
</property>
<property name="poolSize" value="3" />
<property name="minPoolSize" value="3" />
<property name="maxPoolSize" value="5" />
</bean>
<bean id="jdbcTemplateC" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSourceC" />
</bean>
<bean id="jdbcTemplateD" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSourceD" />
</bean>
事务配置:
我们知道分布式事务中需要一个事务管理器即接口javax.transaction.TransactionManager、面向开发人员的javax.transaction.UserTransaction。对于Atomikos来说分别对应如下:
com.atomikos.icatch.jta.UserTransactionImp
com.atomikos.icatch.jta.UserTransactionManager 我们如果想使用分布式事务的同时,又想使用Spring带给我们的@Transactional便利,就需要配置一个JtaTransactionManager,而该JtaTransactionManager是需要一个userTransaction实例的
<bean id="userTransaction" class="com.atomikos.icatch.jta.UserTransactionImp">
<property name="transactionTimeout" value="300" />
</bean>
<bean id="springTransactionManager" class="org.springframework.transaction.jta.JtaTransactionManager">
<property name="userTransaction" ref="userTransaction" />
</bean>
<tx:annotation-driven transaction-manager="springTransactionManager"/>
可以对比下jotm的案例配置jotm的分布式事务配置。可以看到jotm中使用的xapool中的StandardXADataSource是需要一个transactionManager的,而Atomikos使用的AtomikosNonXADataSourceBean则不需要。我们知道,StandardXADataSource中有了transactionManager就可以获取当前线程的事务,同时把XAResource加入进当前事务中去,而AtomikosNonXADataSourceBean却没有,它是怎么把XAResource加入进当前线程绑定的事务呢?这时候就需要可以通过静态方法随时获取当前线程绑定的事务。 使用到的JAR包:
compile 'com.atomikos:transactions-jdbc:4.0.0M4'3.2 单机事务+同步回调(异步)
以订单子系统和支付子系统为例,如下图:
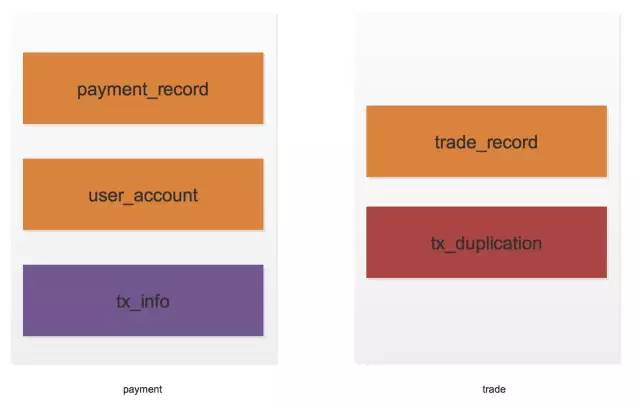
如上图,payment是支付系统,trade是订单系统,两个系统对应的数据库是分开的。支付完成之后,支付系统需要通知订单系统状态变更。
对于payment要执行的操作可以用伪代码表示如下:
begin tx;
count = update account set amount = amount - ${cash} where uid = ${uid} and amount >= amount
if (count <= 0) return false
update payment_record set status = paid where trade_id = ${tradeId}
commit;
对于trade要执行的操作可以用伪代码表示如下:
begin tx;
count = update trade_record set status = paid where trade_id = ${trade_id} and status = unpaid
if (count <= 0) return false
do other things ...
commit;
但是对于这两段代码如何串起来是个问题,我们增加一个事务表,即图中的tx_info,来记录成功完成的支付事务,tx_info中需要有可以标示被支付系统处理状态的字段,为了和支付信息一致,需要放入事务中,代码如下:
begin tx;
count = update account set amount = amount - ${cash} where uid = ${uid} and amount >= amount
if (count <= 0) return false
update payment_record set status = paid where trade_id = ${tradeId}
insert into tx_info values(${trade_id},${amount}...)
commit;
支付系统边界到此为止,接下来就是订单系统轮询访问tx_info,拉取已经支付成功的订单信息,对每一条信息都执行trade系统的逻辑,伪代码如下:
foreach trade_id in tx_info
do trade_tx
save tx_info.id to some store
事无延迟取决于时间程序轮询间隔,这样我们做到了一致性,最终订单都会在支付之后的最大时间间隔内完成状态迁移。
当然,这里也可以采用支付系统通过RPC方式同步通知订单系统的方式来实现,处理状态通过tx_info中的字段来表示。
另外,交易系统每次拉取数据的起点以及消费记录需要记录下来,这样才能不遗漏不重复地执行,所以需要增加一张表用于排重,即上图中的tx_duplication。但是每次对tx_duplication表的插入要在trade_tx的事务中完成,伪代码如下:
begin tx;
c = insert ignore tx_duplication values($trade_id...)
if (c <= 0) return false
count = update trade_record set status = paid where trade_id = ${trade_id} and status = unpaid
if (count <= 0) return false
do other things ...
commit;
另外,tx_duplication表中trade_id表上必须有唯一键,这个算是结合之前的幂等篇来保证trade_tx的操作是幂等的。
3.3 MQ做中间表角色
在上面的方案中,tx_info表所起到的作用就是队列作用,记录一个系统的表更,作为通知给需要感知的系统的事件。而时间程序去拉取只是系统去获取感兴趣事件的一个方式,而对应交易系统的本地事务只是对应消费事件的一个过程。在这样的描述下,这些功能就是一个MQ——消息中间件。如下图
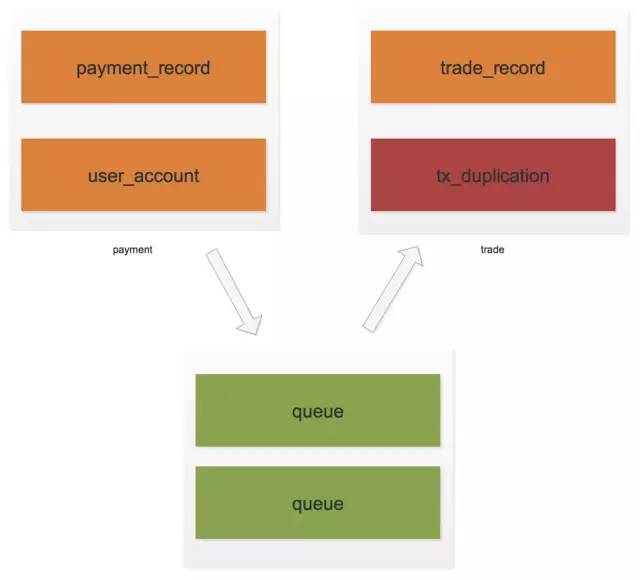
这样tx_info表的功能就交给了MQ,消息消费的偏移量也不需要关心了,MQ会搞定的,但是tx_duplication还是必须存在的,因为MQ并不能避免消息的重复投递,这其中的原因有很多,主要是还是分布式的CAP造成的,再次不详细描述。
这要求MQ必须支持事务功能,可以达到本地事务和消息发出是一致性的,但是不必是强一致的。通常使用的方式如下的伪代码:
sendPrepare();
isCommit = local_tx()
if (isCommit) sendCommit()
else sendRollback()
在做本地事务之前,先向MQ发送一个prepare消息,然后执行本地事务,本地事务提交成功的话,向MQ发送一个commit消息,否则发送一个abort消息,取消之前的消息。MQ只会在收到commit确认才会将消息投递出去,所以这样的形式可以保证在一切正常的情况下,本地事务和MQ可以达到一致性。
但是分布式存在异常情况,网络超时,机器宕机等等,比如当系统执行了local_tx()成功之后,还没来得及将commit消息发送给MQ,或者说发送出去了,网络超时了等等原因,MQ没有收到commit,即commit消息丢失了,那么MQ就不会把prepare消息投递出去。如果这个无法保证的话,那么这个方案是不可行的。针对这种情况,需要一个第三方异常校验模块来对MQ中在一定时间段内没有commit/abort 的消息和发消息的系统进行检查,确认该消息是否应该投递出去或者丢弃,得到系统的确认之后,MQ会做投递还是丢弃,这样就完全保证了MQ和发消息的系统的一致性,从而保证了接收消息系统的一致性。
这个方案要求MQ的系统可用性必须非常高,至少要超过使用MQ的系统(推荐rocketmq,kafka都支持发送预备消息和业务回查),这样才能保证依赖他的系统能稳定运行。
3.4 SAGA方案
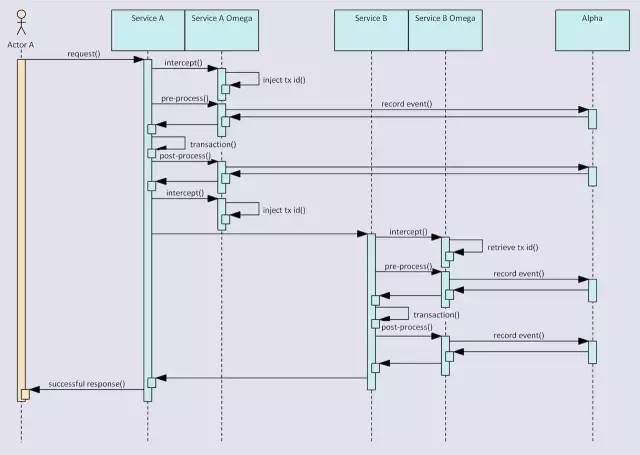
成功场景
成功场景下,每个事务都会有开始和有对应的结束事件。
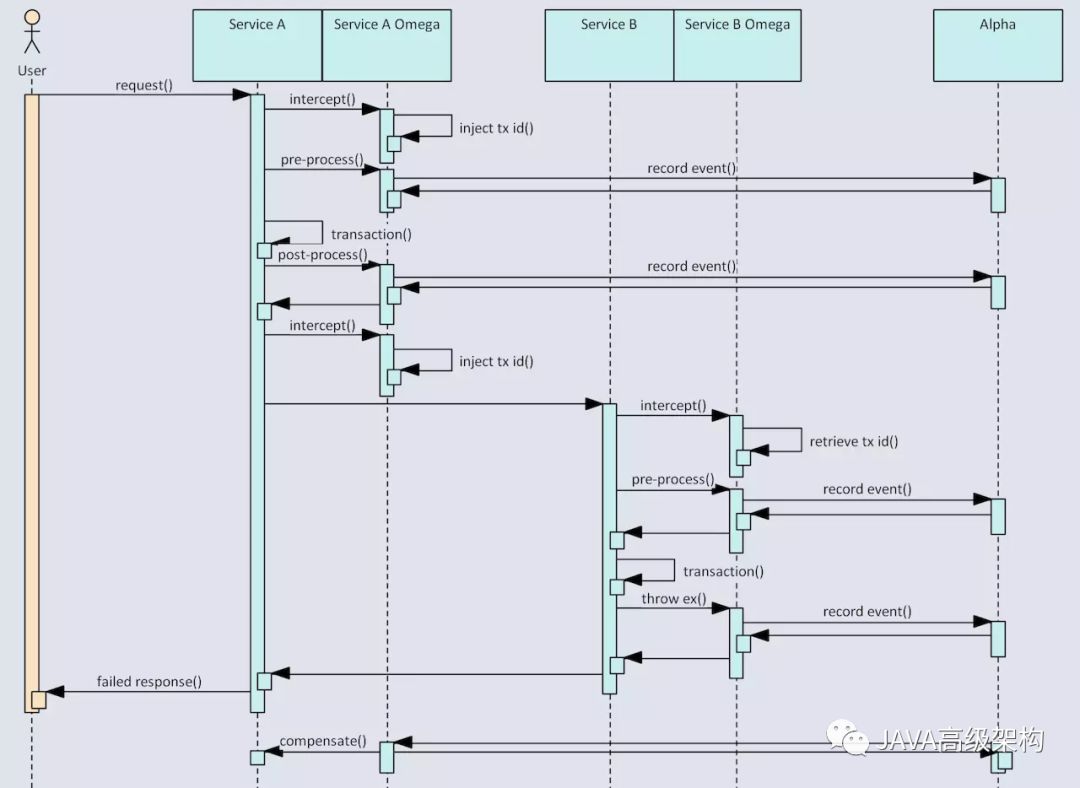
异常场景
异常场景下,omega会向alpha上报中断事件,然后alpha会向该全局事务的其它已完成的子事务发送补偿指令,确保最终所有的子事务要么都成功,要么都回滚。
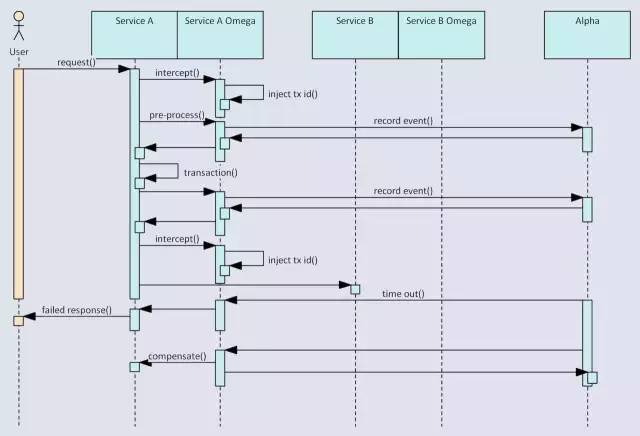
超时场景
超时场景下,已超时的事件会被alpha的定期扫描器检测出来,与此同时,该超时事务对应的全局事务也会被中断。
例子
假设要租车、预订酒店满足分布式事务。
租车服务
@Service
class CarBookingService {
private Map<Integer, CarBooking> bookings = new ConcurrentHashMap<>();
@Compensable(compensationMethod = "cancel")
void order(CarBooking booking) {
booking.confirm();
bookings.put(booking.getId(), booking);
}
void cancel(CarBooking booking) {
Integer id = booking.getId();
if (bookings.containsKey(id)) {
bookings.get(id).cancel();
}
}
Collection<CarBooking> getAllBookings() {
return bookings.values();
}
void clearAllBookings() {
bookings.clear();
}
}
酒店预订
@Service
class HotelBookingService {
private Map<Integer, HotelBooking> bookings = new ConcurrentHashMap<>();
@Compensable(compensationMethod = "cancel")
void order(HotelBooking booking) {
if (booking.getAmount() > 2) {
throw new IllegalArgumentException("can not order the rooms large than two");
}
booking.confirm();
bookings.put(booking.getId(), booking);
}
void cancel(HotelBooking booking) {
Integer id = booking.getId();
if (bookings.containsKey(id)) {
bookings.get(id).cancel();
}
}
Collection<HotelBooking> getAllBookings() {
return bookings.values();
}
void clearAllBookings() {
bookings.clear();
}
}
主服务
@RestController
public class BookingController {
@Value("${car.service.address:http://car.servicecomb.io:8080}")
private String carServiceUrl;
@Value("${hotel.service.address:http://hotel.servicecomb.io:8080}")
private String hotelServiceUrl;
@Autowired
private RestTemplate template;
@SagaStart
@PostMapping("/booking/{name}/{rooms}/{cars}")
public String order(@PathVariable String name, @PathVariable Integer rooms, @PathVariable Integer cars) {
template.postForEntity(
carServiceUrl + "/order/{name}/{cars}",
null, String.class, name, cars);
postCarBooking();
template.postForEntity(
hotelServiceUrl + "/order/{name}/{rooms}",
null, String.class, name, rooms);
postBooking();
return name + " booking " + rooms + " rooms and " + cars + " cars OK";
}
// This method is used by the byteman to inject exception here
private void postCarBooking() {
}
// This method is used by the byteman to inject the faults such as the timeout or the crash
private void postBooking() {
}
}

3.5 TCC方案
eg:订单支付
1:订单服务->修改订单状态
2:库存服务->扣减库存
3:积分服务->增加积分
4:仓库服务->创建出库单
try阶段
1:订单服务->状态变更为“UpDating”
2:库存服务->可用库存减少1,冻结库存增加1
3:积分服务->积分不变,增加预备积分
4:仓库服务->创建出库单,状态设置为“UnKnown”
confirm阶段
1:订单服务->状态变更为“已支付”
2:库存服务->冻结库存清零
3:积分服务->积分增加,预备积分清零
4:仓库服务->状态设置为“出库单已创建”
cancel阶段
1:订单服务->状态变更为“已取消”
2:库存服务->可用库存增加,冻结库存清零
3:积分服务->预备积分清零
4:仓库服务->状态设置为“已取消”
4 小结
| 基本概念 | 优点 | 缺点 |
|---|---|---|
| 本地事务。事务由资源管理器(如DBMS)本地管理 | 严格的ACID | 不具备分布事务处理能力 |
| 全局事务(DTP模型) TX协议:应用或应用服务器与事务管理器的接口 XA协议:全局事务管理器与资源管理器的接口 |
严格的ACID | 效率非常低 |
| JTA:面向应用、应用服务器与资源管理器的高层事务接口 JTS:JTA事务管理器的实现标准,向上支持JTA,向下通过CORBA OTS实现跨事务域的互操作性 EJB |
简单一致的编程模型 跨域分布处理的ACID保证 |
DTP模型本身的局限 缺少充分公开的大规模、高可用、密集事务应用的成功案例 |
| 基于MQ | 消息数据独立存储、独立伸缩 降低业务系统与消息系统间的耦合 |
一次消息发送需要两次请求 业务处理服务需实现消息状态回查接口 |
| 二阶段提交 | 原理简单,实现方便 | 同步阻塞:在二阶段提交的过程中,所有的节点都在等待其他节点的响应,无法进行其他操作。这种同步阻塞极大的限制了分布式系统的性能。 单点问题:协调者在整个二阶段提交过程中很重要,如果协调者在提交阶段出现问题,那么整个流程将无法运转。更重要的是,其他参与者将会处于一直锁定事务资源的状态中,而无法继续完成事务操作。 数据不一致:假设当协调者向所有的参与者发送commit请求之后,发生了局部网络异常,或者是协调者在尚未发送完所有 commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求。这将导致严重的数据不一致问题。 容错性不好:如果在二阶段提交的提交询问阶段中,参与者出现故障,导致协调者始终无法获取到所有参与者的确认信息,这时协调者只能依靠其自身的超时机制,判断是否需要中断事务。显然,这种策略过于保守。换句话说,二阶段提交协议没有设计较为完善的容错机制,任意一个节点是失败都会导致整个事务的失败。 |
| TCC | 相对于二阶段提交,三阶段提交主要解决的单点故障问题,并减少了阻塞的时间。因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行 commit。而不会一直持有事务资源并处于阻塞状态。 | 三阶段提交也会导致数据一致性问题。由于网络原因,协调者发送的 abort 响应没有及时被参与者接收到,那么参与者在等待超时之后执行了 commit 操作。这样就和其他接到 abort 命令并执行回滚的参与者之间存在数据不一致的情况。 |
| SAGA | 简单业务使用TCC需要修改原来业务逻辑,saga只需要添加一个补偿动作 由于没有预留动作所以不用担心资源释放的问题异常处理简单 |
由于没有预留动作导致补偿处理麻烦 |
业务各有各的不同,有些业务能容忍短期不一致,有些业务的操作可以幂等,无论什么样的分布式事务解决方案都有其优缺点,没有一个银弹能够适配所有。因此,业务需要什么样的解决方案,还需要结合自身的业务需求、业务特点、技术架构以及各解决方案的特性,综合分析,才能找到最适合的方案。
温馨提示
以上是关于分布式事务原理及解决方案的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出Seata原理及实战「入门基础专题」探索Seata服务的AT模式下的分布式开发实战指南
精华推荐 | 深入浅出RocketMQ原理及实战「性能原理挖掘系列」透彻剖析贯穿RocketMQ的事务性消息的底层原理并在分析其实际开发场景