Scrapy-基于python的最常见爬虫框架-实战
Posted 机器学习成长笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy-基于python的最常见爬虫框架-实战相关的知识,希望对你有一定的参考价值。
上一篇我们介绍了Scrapy的运行环境配置方法,并且成功运行了第一个“Hello World”程序。今天笔者准备爬取直聘页面的招聘信息,以加深对Scrapy的理解。
网上可以轻易搜到基于Scrapy爬取直聘信息的全过程记录,但基本都是2017年的某一版被四处转载,直聘网站页面的html信息已经有所修改,源代码多处失效,本文将会在其基础上提供最新调整后的爬取方法和具体过程。
一、开发环境
MacOS 10.13.6
Python 2.7.10
Scrapy 1.5.1
Atom 1.7.4
二、新建项目
$scrapy startproject www_zhipin_com
此处可以使用tree+'dirname'的指令查看你所创建项目的树形结构
三、定义要抓取的Item
在items.py文件中定义一个类,scrapy.Field()有点类似我们在数据库中定义的数据类型,也就是爬到的数据属性。
三、分析页面源代码
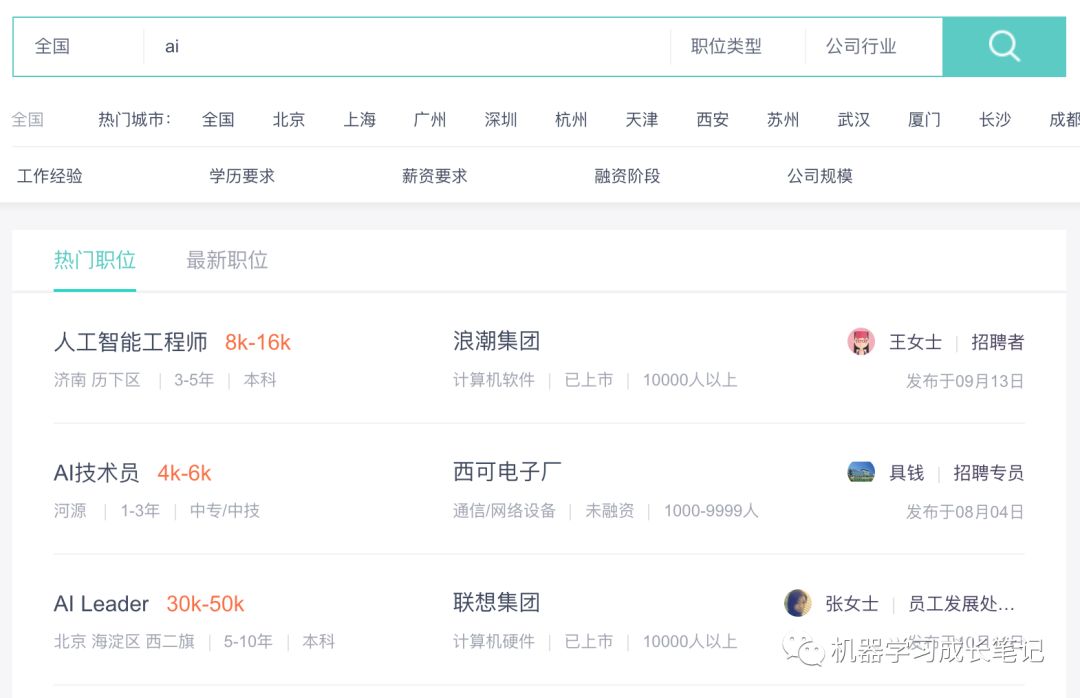
在首页搜索栏输入关键字“AI”,返回的每一条招聘信息即是我们需要爬取的对象

这是一条招聘记录的完整信息,爬虫就是使用 css 选择器获取标签里的文字或链接等。
四、爬虫代码
在 spiders 目录下新建 zhipin_spider.py
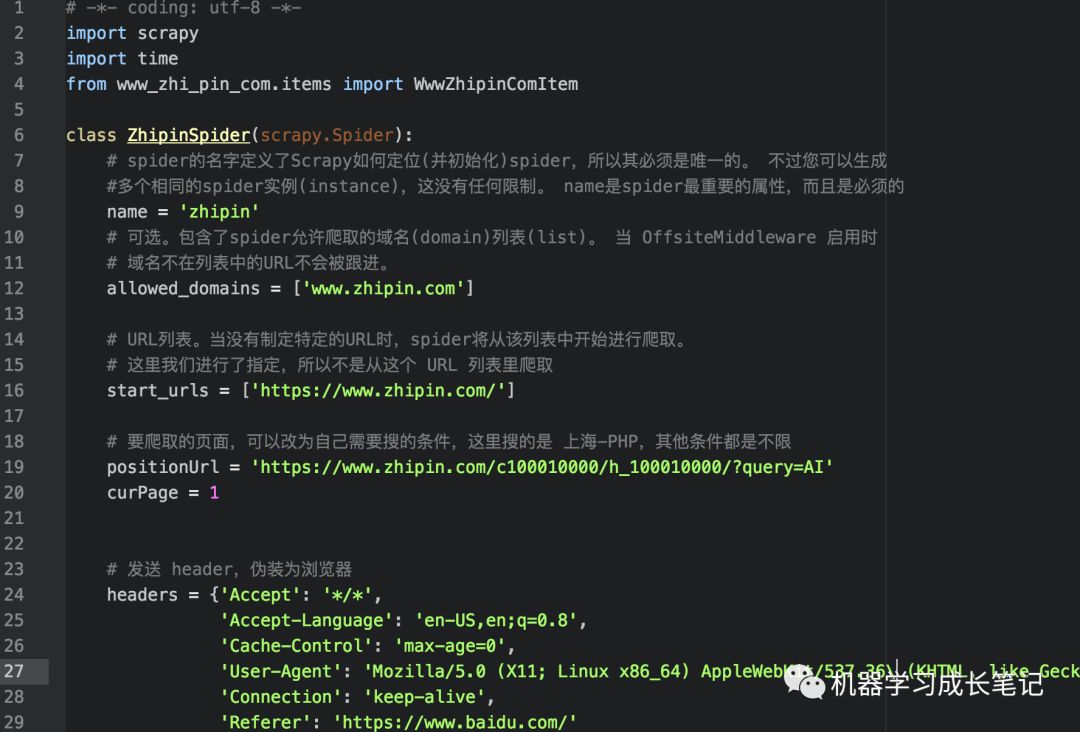
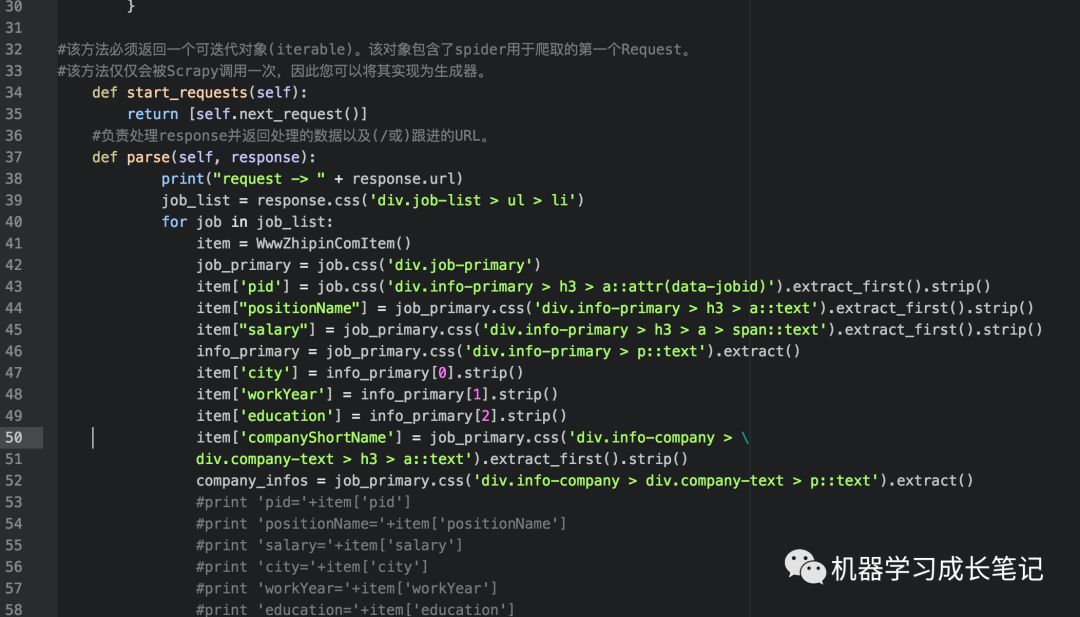
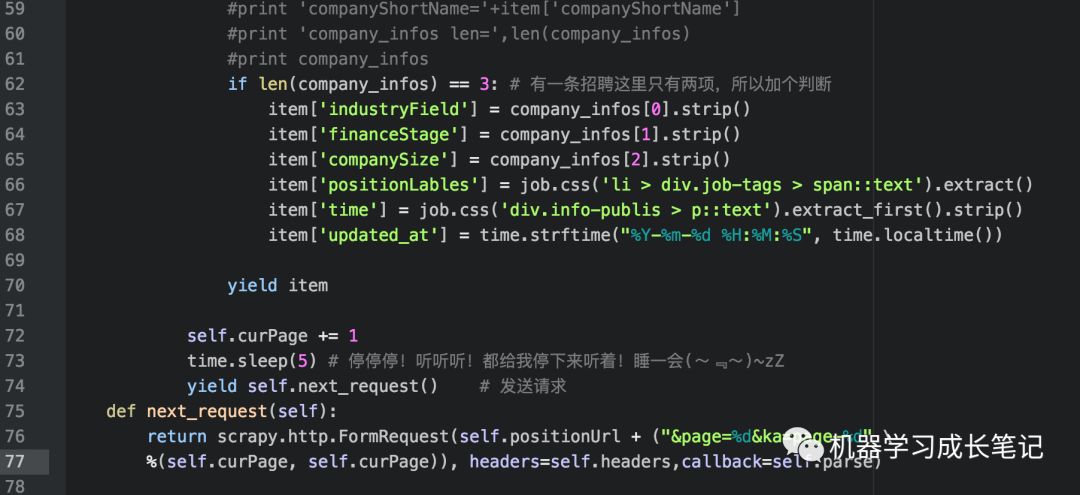
headers的构造内容为
headers = {'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36\ (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36',
'Connection': 'keep-alive',
'Referer': 'https://www.baidu.com/'
}
运行脚本 scrapy crawl zhipin -o item.json
生成的json脚本即为爬虫结果,如下:

五、坑-集锦
1、在settings.py中添加FEED_EXPORT_ENCODING = 'utf-8'
2、如果出现爬取time关键字时报错,核对页面html代码,目标页面针对此内容进行了修改,需要对代码进行相应修改

4、在不挂VPN的情况下,提示如下错误,挂载VPN后成功获取数据
(可能是cookie缓存的问题,尚未深究)
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302)
5、如果采用粘贴代码的方式,注意缩进格式和隐藏的空白符
6、控制爬取速率,如果仍出现数据残缺不全的情况,尝试修改settings.py内容
AUTOTHROTTLE_DEBUG = True
六、结语
通过实际案例体会到Scrapy的用法,实现最基本的功能,回顾了css相关知识。后期可以将获得的json数据导入mongodb,为数据分析提供基础。
对代码感兴趣的同学可以留言获取源代码链接,能力有限,请多批评指正。
以上是关于Scrapy-基于python的最常见爬虫框架-实战的主要内容,如果未能解决你的问题,请参考以下文章